 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Active Visual Search with Monte Carlo planning under Uncertain Detections
Mar 06, 2023



We propose a solution for Active Visual Search of objects in an environment, whose 2D floor map is the only known information. Our solution has three key features that make it more plausible and robust to detector failures compared to state-of-the-art methods: (i) it is unsupervised as it does not need any training sessions. (ii) During the exploration, a probability distribution on the 2D floor map is updated according to an intuitive mechanism, while an improved belief update increases the effectiveness of the agent's exploration. (iii) We incorporate the awareness that an object detector may fail into the aforementioned probability modelling by exploiting the success statistics of a specific detector. Our solution is dubbed POMP-BE-PD (Pomcp-based Online Motion Planning with Belief by Exploration and Probabilistic Detection). It uses the current pose of an agent and an RGB-D observation to learn an optimal search policy, exploiting a POMDP solved by a Monte-Carlo planning approach. On the Active Vision Database benchmark, we increase the average success rate over all the environments by a significant 35% while decreasing the average path length by 4% with respect to competing methods. Thus, our results are state-of-the-art, even without using any training procedure.
POMP++: Pomcp-based Active Visual Search in unknown indoor environments
Jul 02, 2021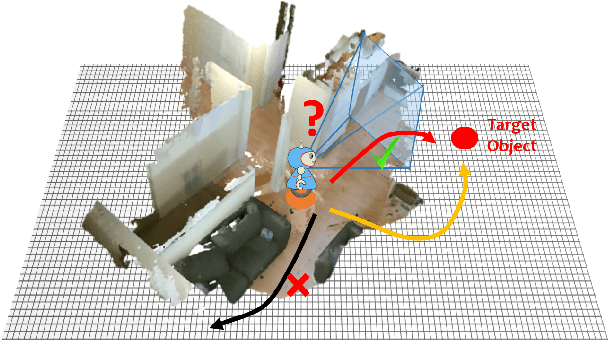
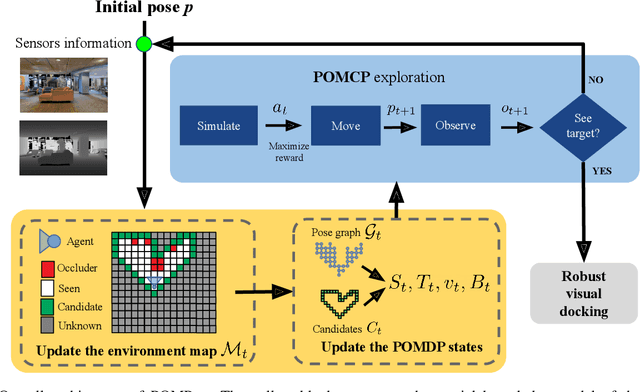
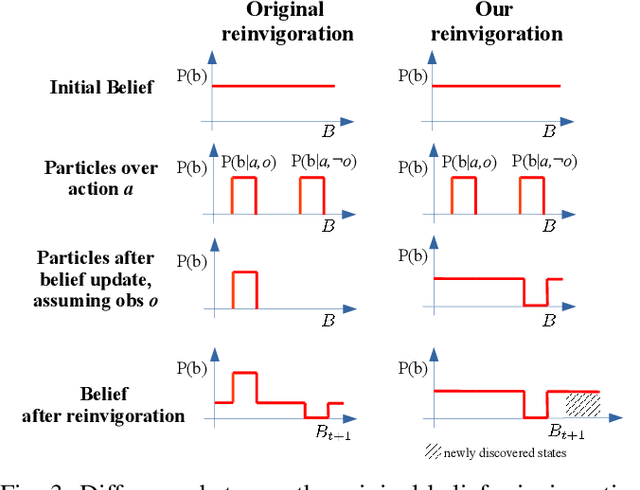

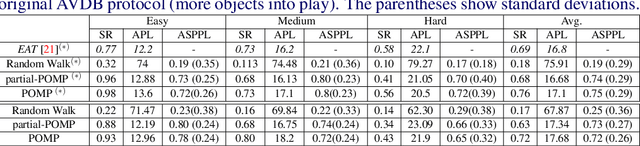
In this paper we focus on the problem of learning online an optimal policy for Active Visual Search (AVS) of objects in unknown indoor environments. We propose POMP++, a planning strategy that introduces a novel formulation on top of the classic Partially Observable Monte Carlo Planning (POMCP) framework, to allow training-free online policy learning in unknown environments. We present a new belief reinvigoration strategy which allows to use POMCP with a dynamically growing state space to address the online generation of the floor map. We evaluate our method on two public benchmark datasets, AVD that is acquired by real robotic platforms and Habitat ObjectNav that is rendered from real 3D scene scans, achieving the best success rate with an improvement of >10% over the state-of-the-art methods.
POMP: Pomcp-based Online Motion Planning for active visual search in indoor environments
Sep 17, 2020
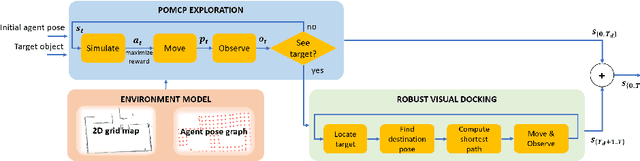

In this paper we focus on the problem of learning an optimal policy for Active Visual Search (AVS) of objects in known indoor environments with an online setup. Our POMP method uses as input the current pose of an agent (e.g. a robot) and a RGB-D frame. The task is to plan the next move that brings the agent closer to the target object. We model this problem as a Partially Observable Markov Decision Process solved by a Monte-Carlo planning approach. This allows us to make decisions on the next moves by iterating over the known scenario at hand, exploring the environment and searching for the object at the same time. Differently from the current state of the art in Reinforcement Learning, POMP does not require extensive and expensive (in time and computation) labelled data so being very agile in solving AVS in small and medium real scenarios. We only require the information of the floormap of the environment, an information usually available or that can be easily extracted from an a priori single exploration run. We validate our method on the publicly available AVD benchmark, achieving an average success rate of 0.76 with an average path length of 17.1, performing close to the state of the art but without any training needed. Additionally, we show experimentally the robustness of our method when the quality of the object detection goes from ideal to faulty.