 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning for Energy-limited Wireless Networks: A Partial Model Aggregation Approach
Paper and Code
Apr 20, 2022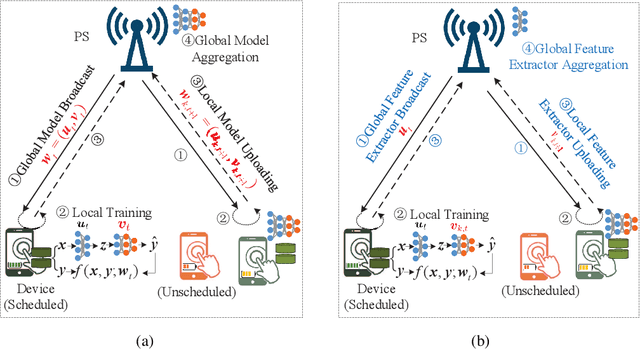
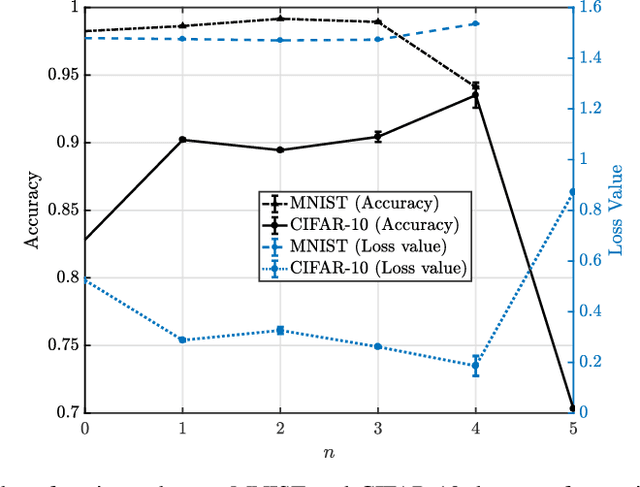
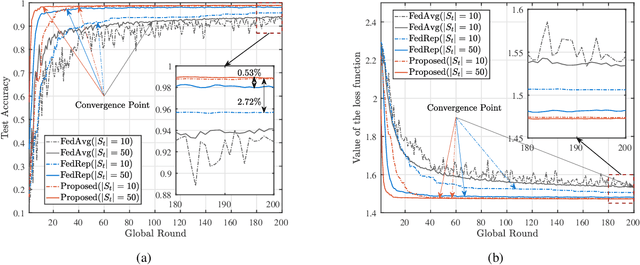
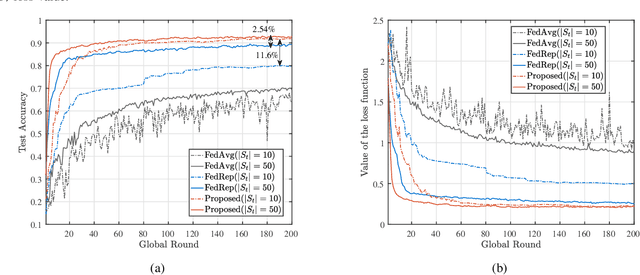
The limited communication resources, e.g., bandwidth and energy, and data heterogeneity across devices are two of the main bottlenecks for federated learning (FL). To tackle these challenges, we first devise a novel FL framework with partial model aggregation (PMA), which only aggregates the lower layers of neural networks responsible for feature extraction while the upper layers corresponding to complex pattern recognition remain at devices for personalization. The proposed PMA-FL is able to address the data heterogeneity and reduce the transmitted information in wireless channels. We then obtain a convergence bound of the framework under a non-convex loss function setting. With the aid of this bound, we define a new objective function, named the scheduled data sample volume, to transfer the original inexplicit optimization problem into a tractable one for device scheduling, bandwidth allocation, computation and communication time division. Our analysis reveals that the optimal time division is achieved when the communication and computation parts of PMA-FL have the same power. We also develop a bisection method to solve the optimal bandwidth allocation policy and use the set expansion algorithm to address the optimal device scheduling. Compared with the state-of-the-art benchmarks, the proposed PMA-FL improves 2.72% and 11.6% accuracy on two typical heterogeneous datasets, i.e., MINIST and CIFAR-10, respectively. In addition, the proposed joint dynamic device scheduling and resource optimization approach achieve slightly higher accuracy than the considered benchmarks, but they provide a satisfactory energy and time reduction: 29% energy or 20% time reduction on the MNIST; and 25% energy or 12.5% time reduction on the CIFAR-10.