 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Simultaneous Multi-Step Prediction of Road Dynamics and Cost Map
Paper and Code
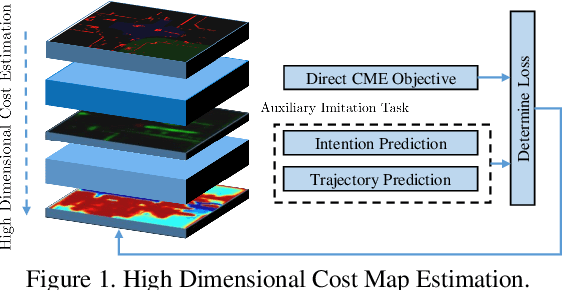
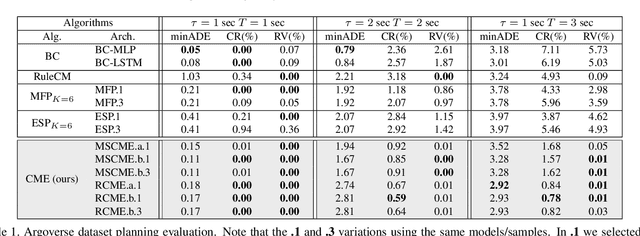
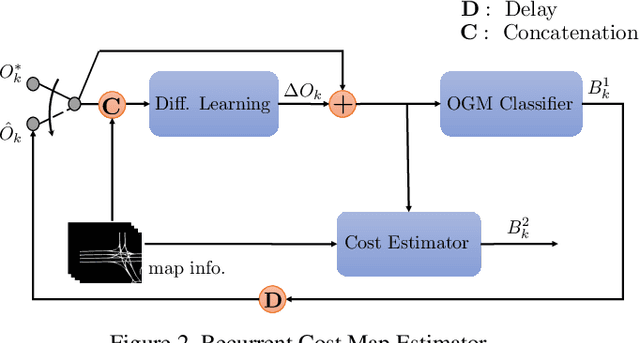
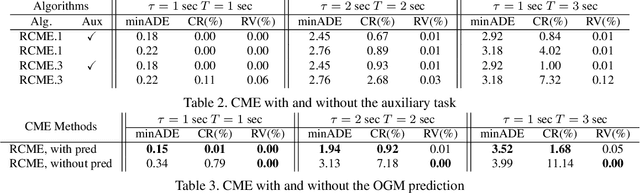
While supervised learning is widely used for perception modules in conventional autonomous driving solutions, scalability is hindered by the huge amount of data labeling needed. In contrast, while end-to-end architectures do not require labeled data and are potentially more scalable, interpretability is sacrificed. We introduce a novel architecture that is trained in a fully self-supervised fashion for simultaneous multi-step prediction of space-time cost map and road dynamics. Our solution replaces the manually designed cost function for motion planning with a learned high dimensional cost map that is naturally interpretable and allows diverse contextual information to be integrated without manual data labeling. Experiments on real world driving data show that our solution leads to lower number of collisions and road violations in long planning horizons in comparison to baselines, demonstrating the feasibility of fully self-supervised prediction without sacrificing either scalability or interpretability.