 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTracking Gaze and Visual Focus of Attention of People Involved in Social Interaction
Nov 21, 2017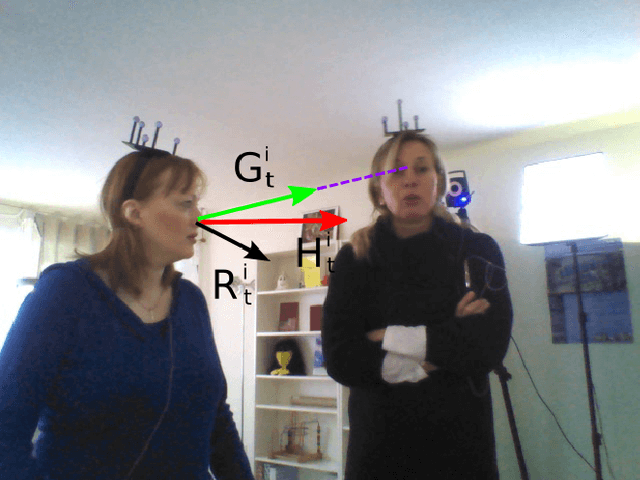
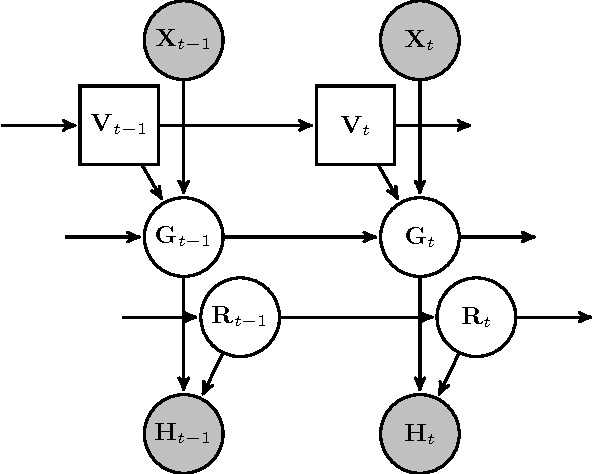
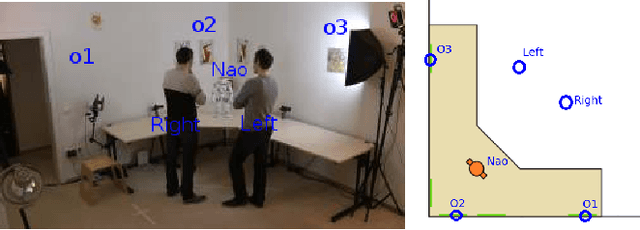
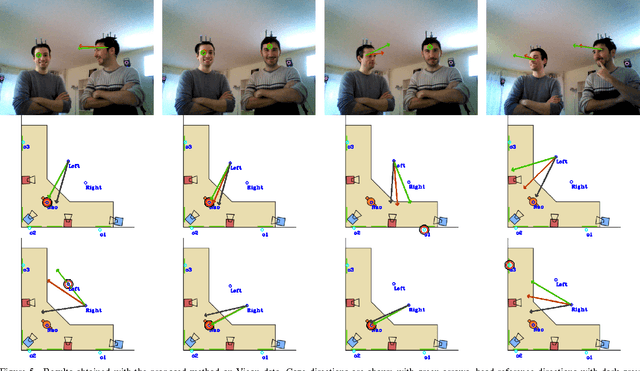
The visual focus of attention (VFOA) has been recognized as a prominent conversational cue. We are interested in estimating and tracking the VFOAs associated with multi-party social interactions. We note that in this type of situations the participants either look at each other or at an object of interest; therefore their eyes are not always visible. Consequently both gaze and VFOA estimation cannot be based on eye detection and tracking. We propose a method that exploits the correlation between eye gaze and head movements. Both VFOA and gaze are modeled as latent variables in a Bayesian switching state-space model. The proposed formulation leads to a tractable learning procedure and to an efficient algorithm that simultaneously tracks gaze and visual focus. The method is tested and benchmarked using two publicly available datasets that contain typical multi-party human-robot and human-human interactions.
* 15 pages, 8 figures, 6 tables