 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimax Active Learning
Dec 18, 2020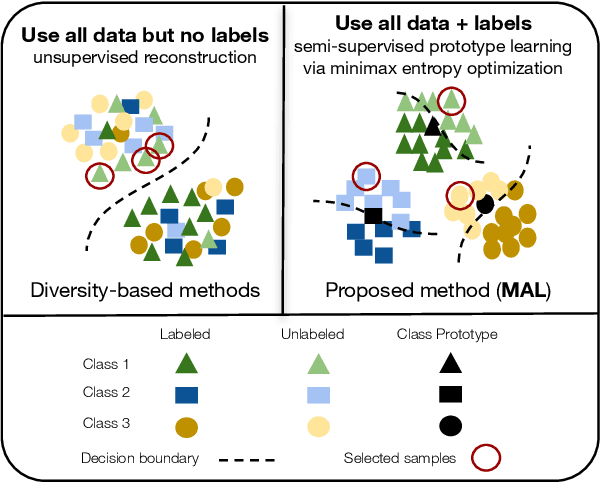
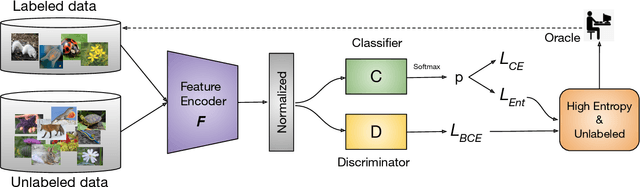

Active learning aims to develop label-efficient algorithms by querying the most representative samples to be labeled by a human annotator. Current active learning techniques either rely on model uncertainty to select the most uncertain samples or use clustering or reconstruction to choose the most diverse set of unlabeled examples. While uncertainty-based strategies are susceptible to outliers, solely relying on sample diversity does not capture the information available on the main task. In this work, we develop a semi-supervised minimax entropy-based active learning algorithm that leverages both uncertainty and diversity in an adversarial manner. Our model consists of an entropy minimizing feature encoding network followed by an entropy maximizing classification layer. This minimax formulation reduces the distribution gap between the labeled/unlabeled data, while a discriminator is simultaneously trained to distinguish the labeled/unlabeled data. The highest entropy samples from the classifier that the discriminator predicts as unlabeled are selected for labeling. We extensively evaluate our method on various image classification and semantic segmentation benchmark datasets and show superior performance over the state-of-the-art methods.
Remembering for the Right Reasons: Explanations Reduce Catastrophic Forgetting
Oct 04, 2020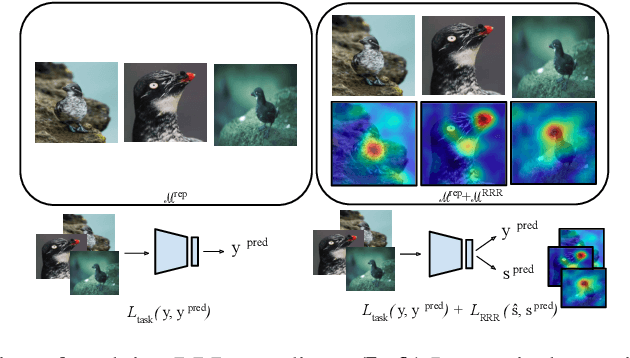

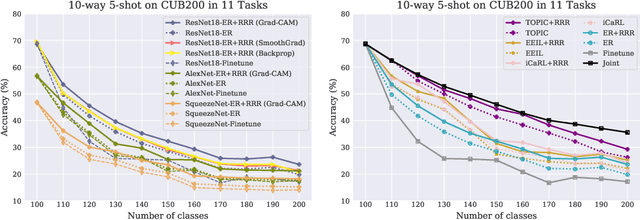

The goal of continual learning (CL) is to learn a sequence of tasks without suffering from the phenomenon of catastrophic forgetting. Previous work has shown that leveraging memory in the form of a replay buffer can reduce performance degradation on prior tasks. We hypothesize that forgetting can be further reduced when the model is encouraged to remember the \textit{evidence} for previously made decisions. As a first step towards exploring this hypothesis, we propose a simple novel training paradigm, called Remembering for the Right Reasons (RRR), that additionally stores visual model explanations for each example in the buffer and ensures the model has "the right reasons" for its predictions by encouraging its explanations to remain consistent with those used to make decisions at training time. Without this constraint, there is a drift in explanations and increase in forgetting as conventional continual learning algorithms learn new tasks. We demonstrate how RRR can be easily added to any memory or regularization-based approach and results in reduced forgetting, and more importantly, improved model explanations. We have evaluated our approach in the standard and few-shot settings and observed a consistent improvement across various CL approaches using different architectures and techniques to generate model explanations and demonstrated our approach showing a promising connection between explainability and continual learning. Our code is available at https://github.com/SaynaEbrahimi/Remembering-for-the-Right-Reasons.