 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Distributed Synchronous SGD
Mar 21, 2017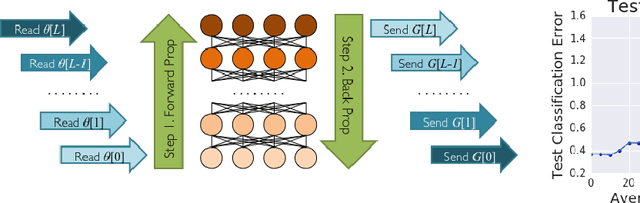

Distributed training of deep learning models on large-scale training data is typically conducted with asynchronous stochastic optimization to maximize the rate of updates, at the cost of additional noise introduced from asynchrony. In contrast, the synchronous approach is often thought to be impractical due to idle time wasted on waiting for straggling workers. We revisit these conventional beliefs in this paper, and examine the weaknesses of both approaches. We demonstrate that a third approach, synchronous optimization with backup workers, can avoid asynchronous noise while mitigating for the worst stragglers. Our approach is empirically validated and shown to converge faster and to better test accuracies.
Hemingway: Modeling Distributed Optimization Algorithms
Feb 20, 2017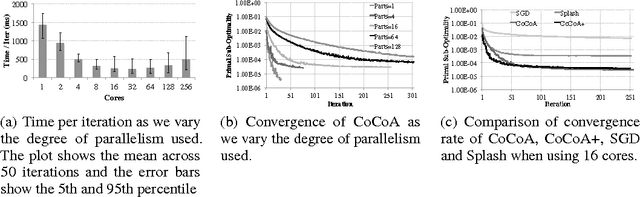
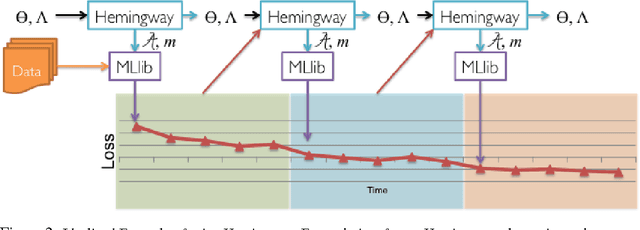
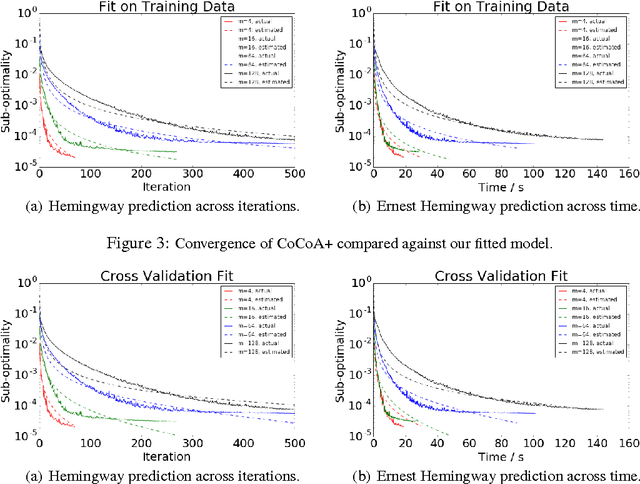
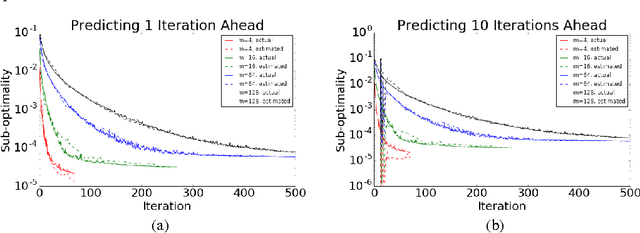
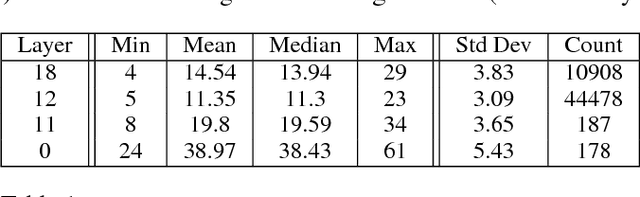
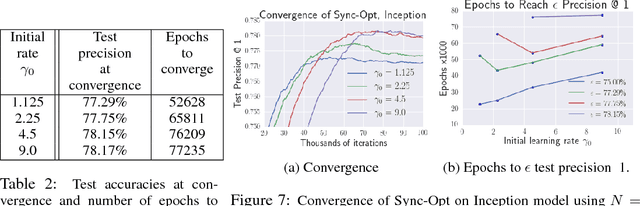
Distributed optimization algorithms are widely used in many industrial machine learning applications. However choosing the appropriate algorithm and cluster size is often difficult for users as the performance and convergence rate of optimization algorithms vary with the size of the cluster. In this paper we make the case for an ML-optimizer that can select the appropriate algorithm and cluster size to use for a given problem. To do this we propose building two models: one that captures the system level characteristics of how computation, communication change as we increase cluster sizes and another that captures how convergence rates change with cluster sizes. We present preliminary results from our prototype implementation called Hemingway and discuss some of the challenges involved in developing such a system.
CYCLADES: Conflict-free Asynchronous Machine Learning
May 31, 2016
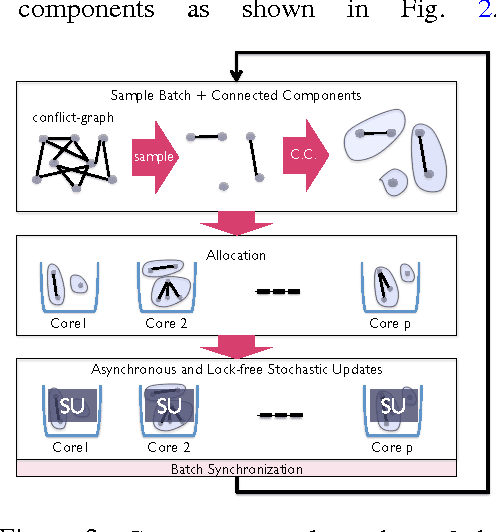

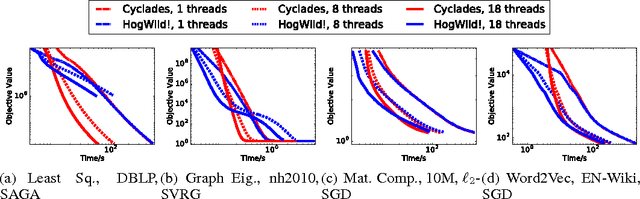
We present CYCLADES, a general framework for parallelizing stochastic optimization algorithms in a shared memory setting. CYCLADES is asynchronous during shared model updates, and requires no memory locking mechanisms, similar to HOGWILD!-type algorithms. Unlike HOGWILD!, CYCLADES introduces no conflicts during the parallel execution, and offers a black-box analysis for provable speedups across a large family of algorithms. Due to its inherent conflict-free nature and cache locality, our multi-core implementation of CYCLADES consistently outperforms HOGWILD!-type algorithms on sufficiently sparse datasets, leading to up to 40% speedup gains compared to the HOGWILD! implementation of SGD, and up to 5x gains over asynchronous implementations of variance reduction algorithms.
Perturbed Iterate Analysis for Asynchronous Stochastic Optimization
Mar 25, 2016

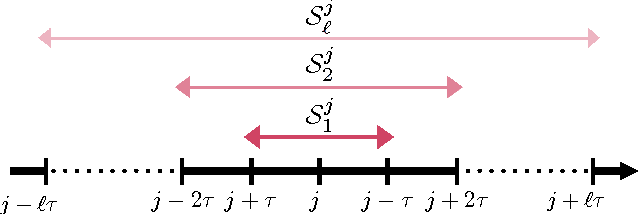
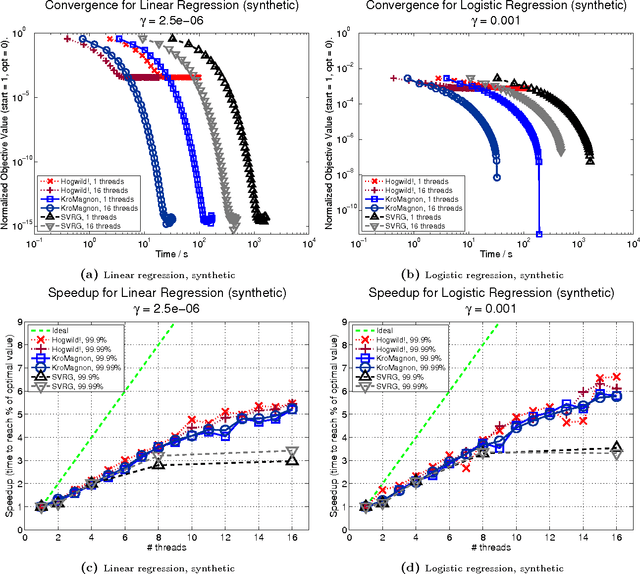
We introduce and analyze stochastic optimization methods where the input to each gradient update is perturbed by bounded noise. We show that this framework forms the basis of a unified approach to analyze asynchronous implementations of stochastic optimization algorithms.In this framework, asynchronous stochastic optimization algorithms can be thought of as serial methods operating on noisy inputs. Using our perturbed iterate framework, we provide new analyses of the Hogwild! algorithm and asynchronous stochastic coordinate descent, that are simpler than earlier analyses, remove many assumptions of previous models, and in some cases yield improved upper bounds on the convergence rates. We proceed to apply our framework to develop and analyze KroMagnon: a novel, parallel, sparse stochastic variance-reduced gradient (SVRG) algorithm. We demonstrate experimentally on a 16-core machine that the sparse and parallel version of SVRG is in some cases more than four orders of magnitude faster than the standard SVRG algorithm.
Parallel Correlation Clustering on Big Graphs
Jul 20, 2015

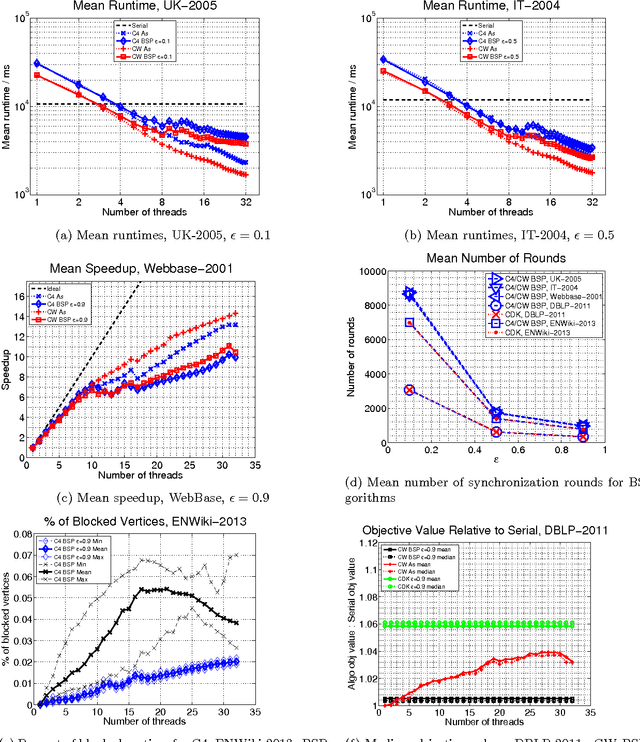
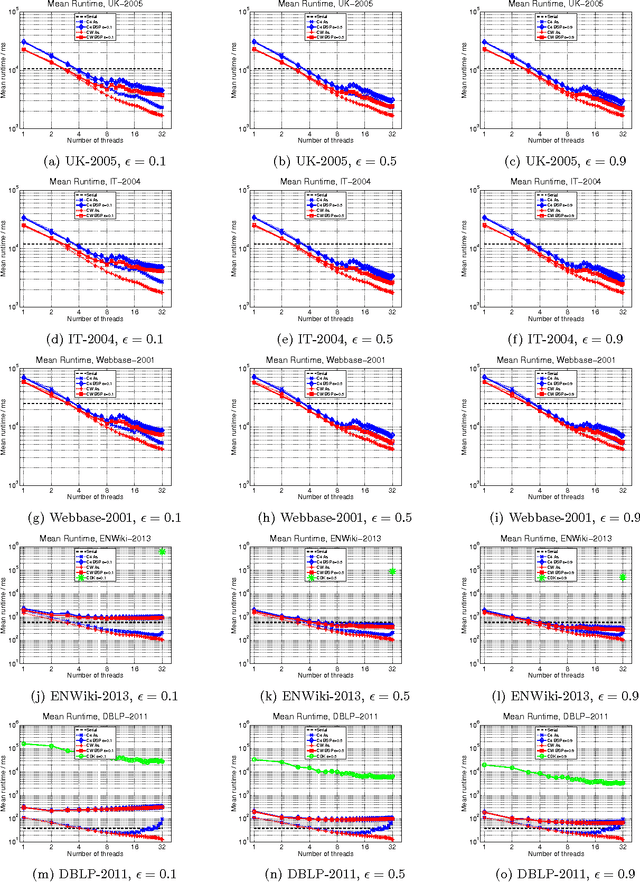
Given a similarity graph between items, correlation clustering (CC) groups similar items together and dissimilar ones apart. One of the most popular CC algorithms is KwikCluster: an algorithm that serially clusters neighborhoods of vertices, and obtains a 3-approximation ratio. Unfortunately, KwikCluster in practice requires a large number of clustering rounds, a potential bottleneck for large graphs. We present C4 and ClusterWild!, two algorithms for parallel correlation clustering that run in a polylogarithmic number of rounds and achieve nearly linear speedups, provably. C4 uses concurrency control to enforce serializability of a parallel clustering process, and guarantees a 3-approximation ratio. ClusterWild! is a coordination free algorithm that abandons consistency for the benefit of better scaling; this leads to a provably small loss in the 3-approximation ratio. We provide extensive experimental results for both algorithms, where we outperform the state of the art, both in terms of clustering accuracy and running time. We show that our algorithms can cluster billion-edge graphs in under 5 seconds on 32 cores, while achieving a 15x speedup.
MLI: An API for Distributed Machine Learning
Oct 25, 2013
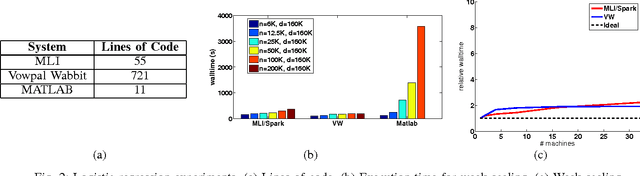
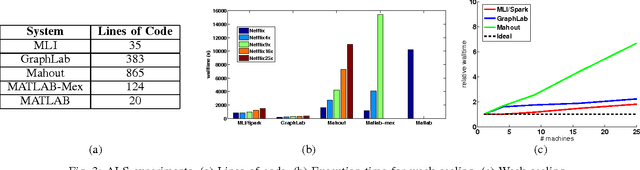
MLI is an Application Programming Interface designed to address the challenges of building Machine Learn- ing algorithms in a distributed setting based on data-centric computing. Its primary goal is to simplify the development of high-performance, scalable, distributed algorithms. Our initial results show that, relative to existing systems, this interface can be used to build distributed implementations of a wide variety of common Machine Learning algorithms with minimal complexity and highly competitive performance and scalability.
Optimistic Concurrency Control for Distributed Unsupervised Learning
Jul 30, 2013

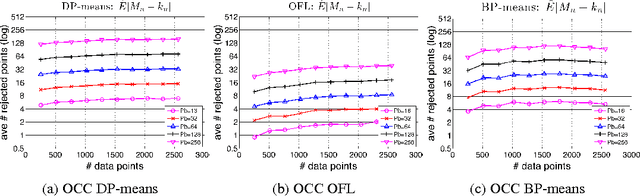
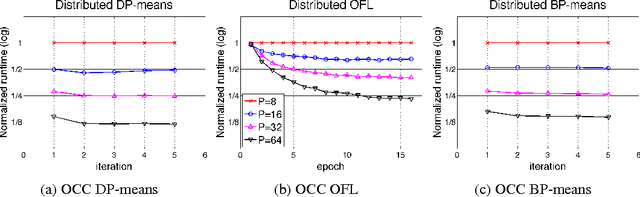
Research on distributed machine learning algorithms has focused primarily on one of two extremes - algorithms that obey strict concurrency constraints or algorithms that obey few or no such constraints. We consider an intermediate alternative in which algorithms optimistically assume that conflicts are unlikely and if conflicts do arise a conflict-resolution protocol is invoked. We view this "optimistic concurrency control" paradigm as particularly appropriate for large-scale machine learning algorithms, particularly in the unsupervised setting. We demonstrate our approach in three problem areas: clustering, feature learning and online facility location. We evaluate our methods via large-scale experiments in a cluster computing environment.
Conditions for Convergence in Regularized Machine Learning Objectives
May 17, 2013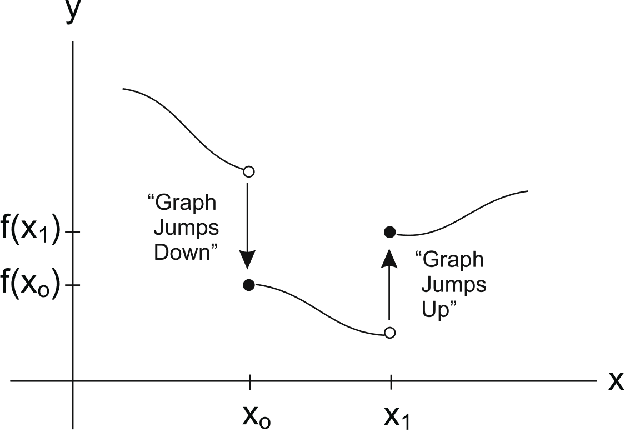
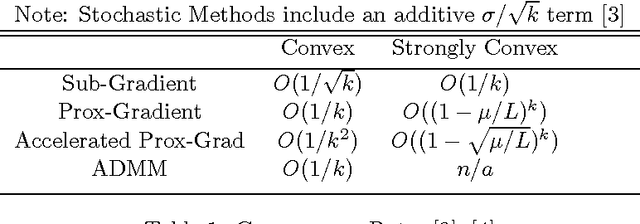
Analysis of the convergence rates of modern convex optimization algorithms can be achived through binary means: analysis of emperical convergence, or analysis of theoretical convergence. These two pathways of capturing information diverge in efficacy when moving to the world of distributed computing, due to the introduction of non-intuitive, non-linear slowdowns associated with broadcasting, and in some cases, gathering operations. Despite these nuances in the rates of convergence, we can still show the existence of convergence, and lower bounds for the rates. This paper will serve as a helpful cheat-sheet for machine learning practitioners encountering this problem class in the field.