 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating LLM Inference with Staged Speculative Decoding
Aug 08, 2023

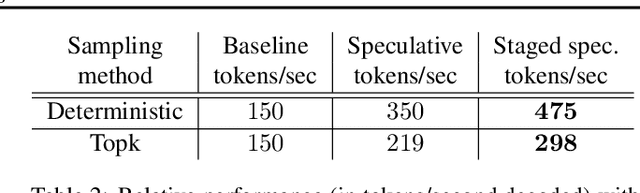

Recent advances with large language models (LLM) illustrate their diverse capabilities. We propose a novel algorithm, staged speculative decoding, to accelerate LLM inference in small-batch, on-device scenarios. We address the low arithmetic intensity of small-batch inference by improving upon previous work in speculative decoding. First, we restructure the speculative batch as a tree, which reduces generation costs and increases the expected tokens per batch. Second, we add a second stage of speculative decoding. Taken together, we reduce single-batch decoding latency by 3.16x with a 762M parameter GPT-2-L model while perfectly preserving output quality.
Analysis of DAWNBench, a Time-to-Accuracy Machine Learning Performance Benchmark
Jun 04, 2018


The deep learning community has proposed optimizations spanning hardware, software, and learning theory to improve the computational performance of deep learning workloads. While some of these optimizations perform the same operations faster (e.g., switching from a NVIDIA K80 to P100), many modify the semantics of the training procedure (e.g., large minibatch training, reduced precision), which can impact a model's generalization ability. Due to a lack of standard evaluation criteria that considers these trade-offs, it has become increasingly difficult to compare these different advances. To address this shortcoming, DAWNBENCH and the upcoming MLPERF benchmarks use time-to-accuracy as the primary metric for evaluation, with the accuracy threshold set close to state-of-the-art and measured on a held-out dataset not used in training; the goal is to train to this accuracy threshold as fast as possible. In DAWNBENCH , the winning entries improved time-to-accuracy on ImageNet by two orders of magnitude over the seed entries. Despite this progress, it is unclear how sensitive time-to-accuracy is to the chosen threshold as well as the variance between independent training runs, and how well models optimized for time-to-accuracy generalize. In this paper, we provide evidence to suggest that time-to-accuracy has a low coefficient of variance and that the models tuned for it generalize nearly as well as pre-trained models. We additionally analyze the winning entries to understand the source of these speedups, and give recommendations for future benchmarking efforts.
CYCLADES: Conflict-free Asynchronous Machine Learning
May 31, 2016
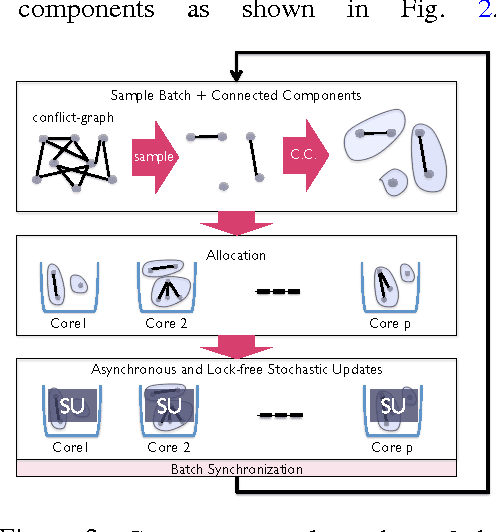

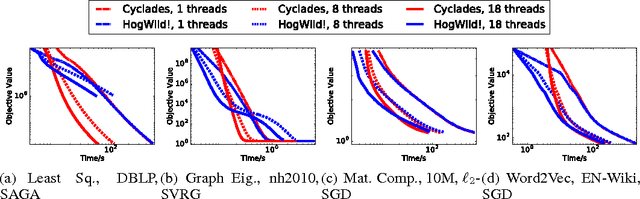
We present CYCLADES, a general framework for parallelizing stochastic optimization algorithms in a shared memory setting. CYCLADES is asynchronous during shared model updates, and requires no memory locking mechanisms, similar to HOGWILD!-type algorithms. Unlike HOGWILD!, CYCLADES introduces no conflicts during the parallel execution, and offers a black-box analysis for provable speedups across a large family of algorithms. Due to its inherent conflict-free nature and cache locality, our multi-core implementation of CYCLADES consistently outperforms HOGWILD!-type algorithms on sufficiently sparse datasets, leading to up to 40% speedup gains compared to the HOGWILD! implementation of SGD, and up to 5x gains over asynchronous implementations of variance reduction algorithms.