 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust-U1: Can MLLMs Self-Recover Corrupted Visual Content for Robust Understanding?
Jun 06, 2026Multimodal Large Language Models (MLLMs) have demonstrated remarkable success in visual understanding, yet their performance degrades significantly under real-world visual corruptions. While existing robustness enhancement approaches exist, they are limited: black-box feature alignment lacks interpretability, and white-box text-based reasoning cannot restore lost pixel-level details. This work investigates a fundamental research question: Can MLLMs recover corrupted visual content by themselves? To address this, we propose Robust-U1, a novel framework that equips MLLMs with explicit visual self-recovery capability for robust understanding. The approach comprises three core stages: supervised fine-tuning for initial reconstruction, reinforcement learning with dual rewards (pixel-level SSIM and semantic-level CLIP similarity) for aligning high visual quality, and multimodal reasoning that jointly considers both the corrupted input and the recovered image. Extensive experiments demonstrate that Robust-U1 achieves state-of-the-art robustness on the real-world corruption benchmark and maintains superior performance under adversarial corruptions on general VQA benchmarks. Analysis confirms that high-quality visual recovery directly enhances reasoning performance, establishing self-recovery as a critical mechanism for robust visual understanding. The source code is available at https://github.com/jqtangust/Robust-U1.
Robust-R1: Degradation-Aware Reasoning for Robust Visual Understanding
Dec 19, 2025Multimodal Large Language Models struggle to maintain reliable performance under extreme real-world visual degradations, which impede their practical robustness. Existing robust MLLMs predominantly rely on implicit training/adaptation that focuses solely on visual encoder generalization, suffering from limited interpretability and isolated optimization. To overcome these limitations, we propose Robust-R1, a novel framework that explicitly models visual degradations through structured reasoning chains. Our approach integrates: (i) supervised fine-tuning for degradation-aware reasoning foundations, (ii) reward-driven alignment for accurately perceiving degradation parameters, and (iii) dynamic reasoning depth scaling adapted to degradation intensity. To facilitate this approach, we introduce a specialized 11K dataset featuring realistic degradations synthesized across four critical real-world visual processing stages, each annotated with structured chains connecting degradation parameters, perceptual influence, pristine semantic reasoning chain, and conclusion. Comprehensive evaluations demonstrate state-of-the-art robustness: Robust-R1 outperforms all general and robust baselines on the real-world degradation benchmark R-Bench, while maintaining superior anti-degradation performance under multi-intensity adversarial degradations on MMMB, MMStar, and RealWorldQA.
Majorization-Minimization Dual Stagewise Algorithm for Generalized Lasso
Jan 04, 2025The generalized lasso is a natural generalization of the celebrated lasso approach to handle structural regularization problems. Many important methods and applications fall into this framework, including fused lasso, clustered lasso, and constrained lasso. To elevate its effectiveness in large-scale problems, extensive research has been conducted on the computational strategies of generalized lasso. However, to our knowledge, most studies are under the linear setup, with limited advances in non-Gaussian and non-linear models. We propose a majorization-minimization dual stagewise (MM-DUST) algorithm to efficiently trace out the full solution paths of the generalized lasso problem. The majorization technique is incorporated to handle different convex loss functions through their quadratic majorizers. Utilizing the connection between primal and dual problems and the idea of ``slow-brewing'' from stagewise learning, the minimization step is carried out in the dual space through a sequence of simple coordinate-wise updates on the dual coefficients with a small step size. Consequently, selecting an appropriate step size enables a trade-off between statistical accuracy and computational efficiency. We analyze the computational complexity of MM-DUST and establish the uniform convergence of the approximated solution paths. Extensive simulation studies and applications with regularized logistic regression and Cox model demonstrate the effectiveness of the proposed approach.
Tree-Guided Rare Feature Selection and Logic Aggregation with Electronic Health Records Data
Jun 18, 2022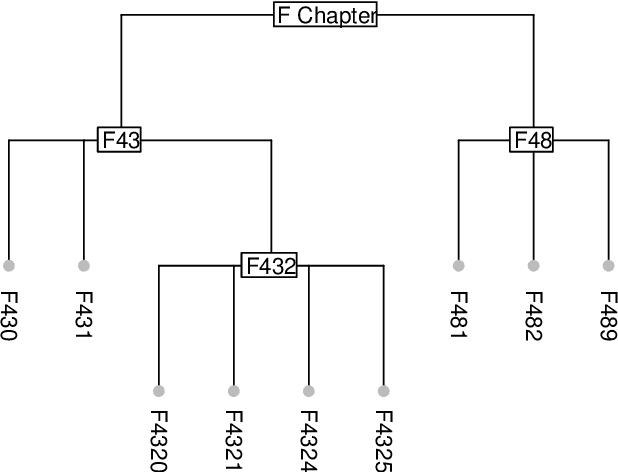
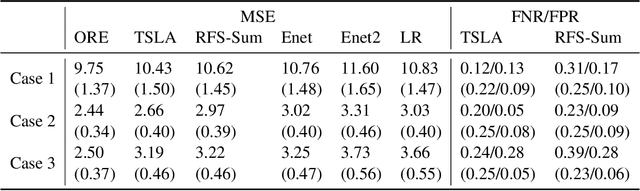
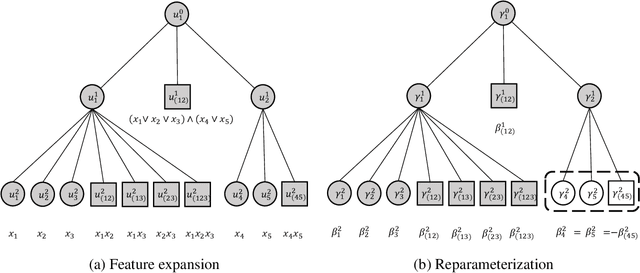
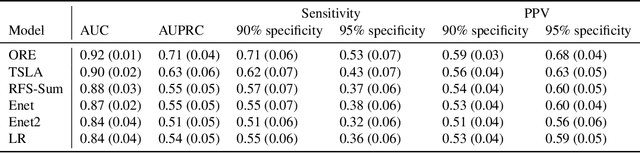
Statistical learning with a large number of rare binary features is commonly encountered in analyzing electronic health records (EHR) data, especially in the modeling of disease onset with prior medical diagnoses and procedures. Dealing with the resulting highly sparse and large-scale binary feature matrix is notoriously challenging as conventional methods may suffer from a lack of power in testing and inconsistency in model fitting while machine learning methods may suffer from the inability of producing interpretable results or clinically-meaningful risk factors. To improve EHR-based modeling and utilize the natural hierarchical structure of disease classification, we propose a tree-guided feature selection and logic aggregation approach for large-scale regression with rare binary features, in which dimension reduction is achieved through not only a sparsity pursuit but also an aggregation promoter with the logic operator of ``or''. We convert the combinatorial problem into a convex linearly-constrained regularized estimation, which enables scalable computation with theoretical guarantees. In a suicide risk study with EHR data, our approach is able to select and aggregate prior mental health diagnoses as guided by the diagnosis hierarchy of the International Classification of Diseases. By balancing the rarity and specificity of the EHR diagnosis records, our strategy improves both prediction and model interpretation. We identify important higher-level categories and subcategories of mental health conditions and simultaneously determine the level of specificity needed for each of them in predicting suicide risk.
Revisiting Distributed Synchronous SGD
Mar 21, 2017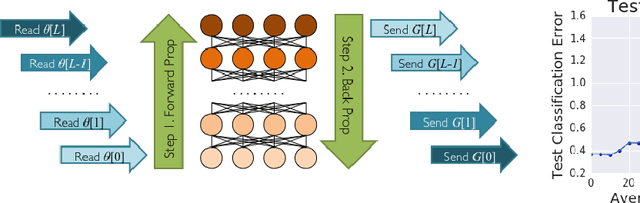
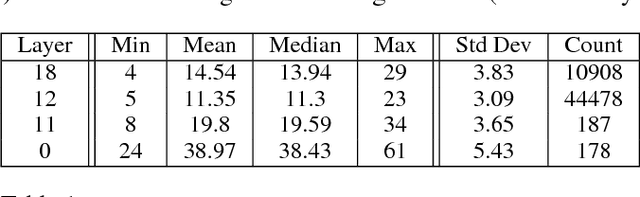

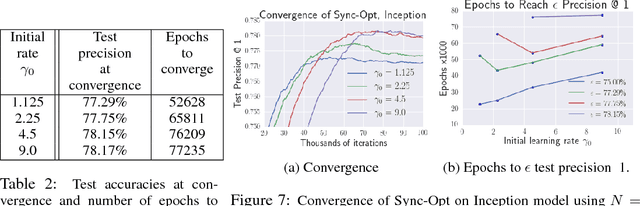
Distributed training of deep learning models on large-scale training data is typically conducted with asynchronous stochastic optimization to maximize the rate of updates, at the cost of additional noise introduced from asynchrony. In contrast, the synchronous approach is often thought to be impractical due to idle time wasted on waiting for straggling workers. We revisit these conventional beliefs in this paper, and examine the weaknesses of both approaches. We demonstrate that a third approach, synchronous optimization with backup workers, can avoid asynchronous noise while mitigating for the worst stragglers. Our approach is empirically validated and shown to converge faster and to better test accuracies.
TensorFlow: A system for large-scale machine learning
May 31, 2016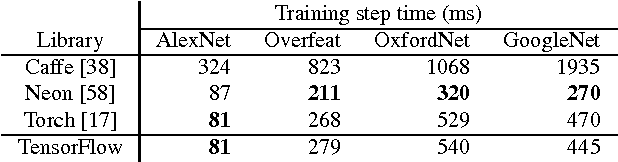

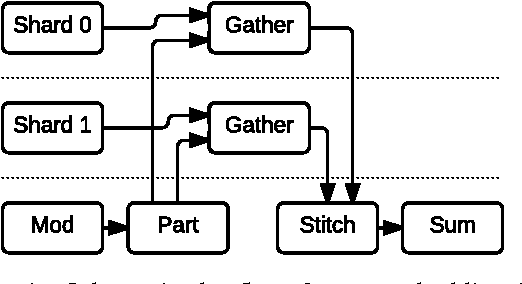
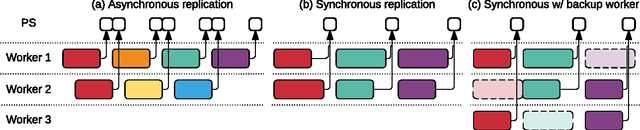
TensorFlow is a machine learning system that operates at large scale and in heterogeneous environments. TensorFlow uses dataflow graphs to represent computation, shared state, and the operations that mutate that state. It maps the nodes of a dataflow graph across many machines in a cluster, and within a machine across multiple computational devices, including multicore CPUs, general-purpose GPUs, and custom designed ASICs known as Tensor Processing Units (TPUs). This architecture gives flexibility to the application developer: whereas in previous "parameter server" designs the management of shared state is built into the system, TensorFlow enables developers to experiment with novel optimizations and training algorithms. TensorFlow supports a variety of applications, with particularly strong support for training and inference on deep neural networks. Several Google services use TensorFlow in production, we have released it as an open-source project, and it has become widely used for machine learning research. In this paper, we describe the TensorFlow dataflow model in contrast to existing systems, and demonstrate the compelling performance that TensorFlow achieves for several real-world applications.