Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditions for Convergence in Regularized Machine Learning Objectives
Paper and Code
May 17, 2013
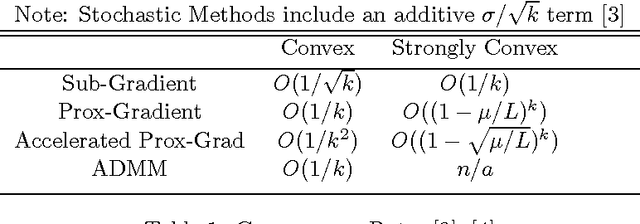
Analysis of the convergence rates of modern convex optimization algorithms can be achived through binary means: analysis of emperical convergence, or analysis of theoretical convergence. These two pathways of capturing information diverge in efficacy when moving to the world of distributed computing, due to the introduction of non-intuitive, non-linear slowdowns associated with broadcasting, and in some cases, gathering operations. Despite these nuances in the rates of convergence, we can still show the existence of convergence, and lower bounds for the rates. This paper will serve as a helpful cheat-sheet for machine learning practitioners encountering this problem class in the field.
* 3 Pages
View paper on