 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstitutional Classifiers++: Efficient Production-Grade Defenses against Universal Jailbreaks
Jan 08, 2026We introduce enhanced Constitutional Classifiers that deliver production-grade jailbreak robustness with dramatically reduced computational costs and refusal rates compared to previous-generation defenses. Our system combines several key insights. First, we develop exchange classifiers that evaluate model responses in their full conversational context, which addresses vulnerabilities in last-generation systems that examine outputs in isolation. Second, we implement a two-stage classifier cascade where lightweight classifiers screen all traffic and escalate only suspicious exchanges to more expensive classifiers. Third, we train efficient linear probe classifiers and ensemble them with external classifiers to simultaneously improve robustness and reduce computational costs. Together, these techniques yield a production-grade system achieving a 40x computational cost reduction compared to our baseline exchange classifier, while maintaining a 0.05% refusal rate on production traffic. Through extensive red-teaming comprising over 1,700 hours, we demonstrate strong protection against universal jailbreaks -- no attack on this system successfully elicited responses to all eight target queries comparable in detail to an undefended model. Our work establishes Constitutional Classifiers as practical and efficient safeguards for large language models.
Constitutional Classifiers: Defending against Universal Jailbreaks across Thousands of Hours of Red Teaming
Jan 31, 2025



Large language models (LLMs) are vulnerable to universal jailbreaks-prompting strategies that systematically bypass model safeguards and enable users to carry out harmful processes that require many model interactions, like manufacturing illegal substances at scale. To defend against these attacks, we introduce Constitutional Classifiers: safeguards trained on synthetic data, generated by prompting LLMs with natural language rules (i.e., a constitution) specifying permitted and restricted content. In over 3,000 estimated hours of red teaming, no red teamer found a universal jailbreak that could extract information from an early classifier-guarded LLM at a similar level of detail to an unguarded model across most target queries. On automated evaluations, enhanced classifiers demonstrated robust defense against held-out domain-specific jailbreaks. These classifiers also maintain deployment viability, with an absolute 0.38% increase in production-traffic refusals and a 23.7% inference overhead. Our work demonstrates that defending against universal jailbreaks while maintaining practical deployment viability is tractable.
Prosody in Cascade and Direct Speech-to-Text Translation: a case study on Korean Wh-Phrases
Feb 01, 2024



Speech-to-Text Translation (S2TT) has typically been addressed with cascade systems, where speech recognition systems generate a transcription that is subsequently passed to a translation model. While there has been a growing interest in developing direct speech translation systems to avoid propagating errors and losing non-verbal content, prior work in direct S2TT has struggled to conclusively establish the advantages of integrating the acoustic signal directly into the translation process. This work proposes using contrastive evaluation to quantitatively measure the ability of direct S2TT systems to disambiguate utterances where prosody plays a crucial role. Specifically, we evaluated Korean-English translation systems on a test set containing wh-phrases, for which prosodic features are necessary to produce translations with the correct intent, whether it's a statement, a yes/no question, a wh-question, and more. Our results clearly demonstrate the value of direct translation systems over cascade translation models, with a notable 12.9% improvement in overall accuracy in ambiguous cases, along with up to a 15.6% increase in F1 scores for one of the major intent categories. To the best of our knowledge, this work stands as the first to provide quantitative evidence that direct S2TT models can effectively leverage prosody. The code for our evaluation is openly accessible and freely available for review and utilisation.
A Field Test of Bandit Algorithms for Recommendations: Understanding the Validity of Assumptions on Human Preferences in Multi-armed Bandits
Apr 16, 2023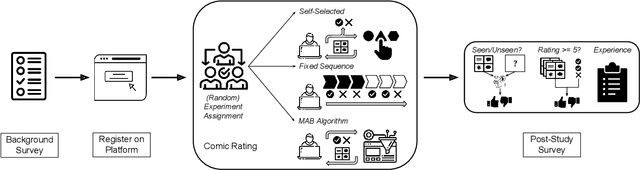



Personalized recommender systems suffuse modern life, shaping what media we read and what products we consume. Algorithms powering such systems tend to consist of supervised learning-based heuristics, such as latent factor models with a variety of heuristically chosen prediction targets. Meanwhile, theoretical treatments of recommendation frequently address the decision-theoretic nature of the problem, including the need to balance exploration and exploitation, via the multi-armed bandits (MABs) framework. However, MAB-based approaches rely heavily on assumptions about human preferences. These preference assumptions are seldom tested using human subject studies, partly due to the lack of publicly available toolkits to conduct such studies. In this work, we conduct a study with crowdworkers in a comics recommendation MABs setting. Each arm represents a comic category, and users provide feedback after each recommendation. We check the validity of core MABs assumptions-that human preferences (reward distributions) are fixed over time-and find that they do not hold. This finding suggests that any MAB algorithm used for recommender systems should account for human preference dynamics. While answering these questions, we provide a flexible experimental framework for understanding human preference dynamics and testing MABs algorithms with human users. The code for our experimental framework and the collected data can be found at https://github.com/HumainLab/human-bandit-evaluation.
Generalising Multilingual Concept-to-Text NLG with Language Agnostic Delexicalisation
May 07, 2021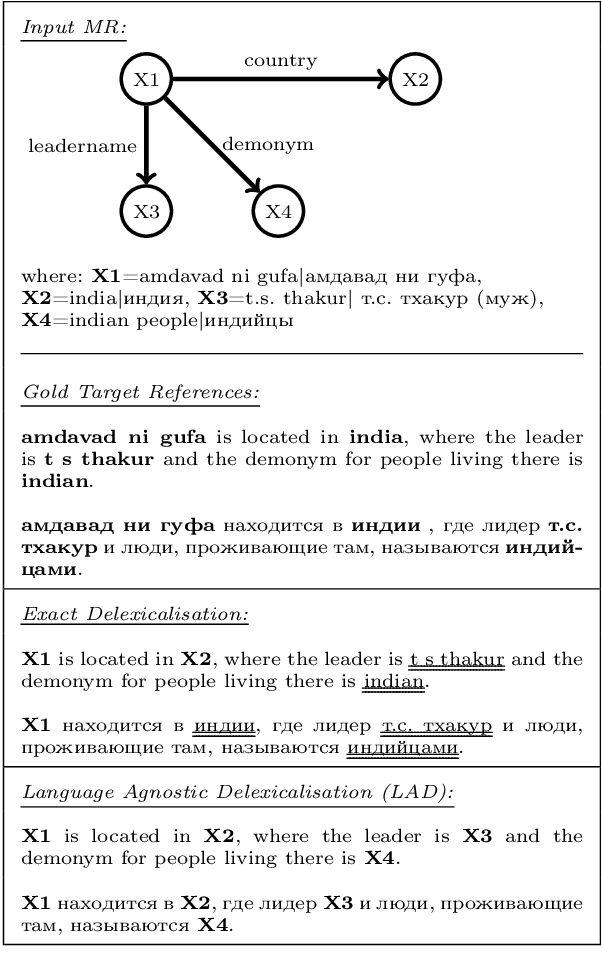
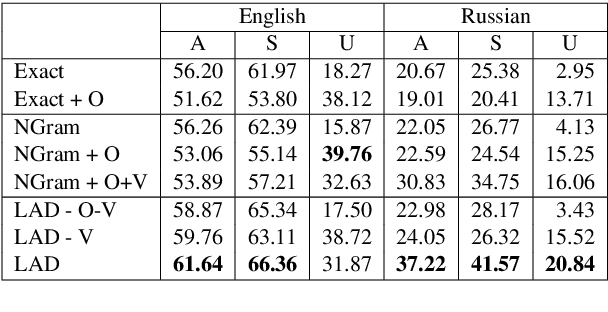

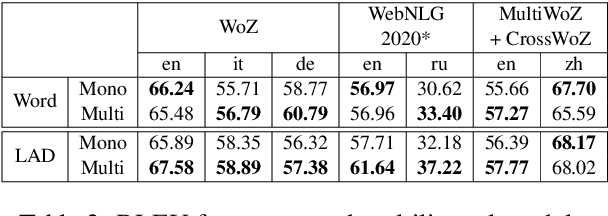
Concept-to-text Natural Language Generation is the task of expressing an input meaning representation in natural language. Previous approaches in this task have been able to generalise to rare or unseen instances by relying on a delexicalisation of the input. However, this often requires that the input appears verbatim in the output text. This poses challenges in multilingual settings, where the task expands to generate the output text in multiple languages given the same input. In this paper, we explore the application of multilingual models in concept-to-text and propose Language Agnostic Delexicalisation, a novel delexicalisation method that uses multilingual pretrained embeddings, and employs a character-level post-editing model to inflect words in their correct form during relexicalisation. Our experiments across five datasets and five languages show that multilingual models outperform monolingual models in concept-to-text and that our framework outperforms previous approaches, especially for low resource languages.
Generating Safe Diversity in NLG via Imitation Learning
Apr 29, 2020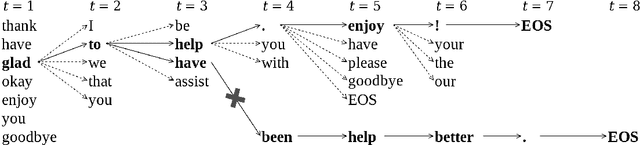

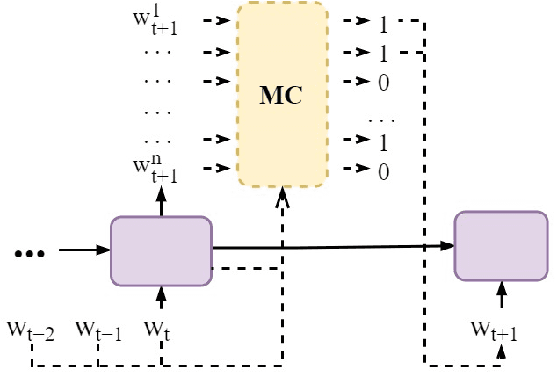
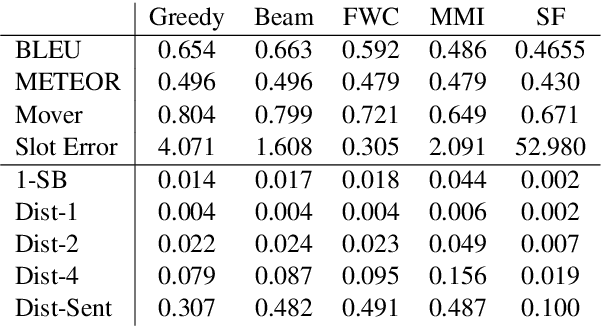
Deep-learning models for language generation tasks tend to produce repetitive output. Various methods have been proposed to encourage lexical diversity during decoding, but this often comes at a cost to the perceived fluency and adequacy of the output. In this work, we propose to ameliorate this cost by using an Imitation Learning approach to explore the level of diversity that a language generation model can safely produce. Specifically, we augment the decoding process with a meta-classifier trained to distinguish which words at any given timestep will lead to high-quality output. We focus our experiments on concept-to-text generation where models are sensitive to the inclusion of irrelevant words due to the strict relation between input and output. Our analysis shows that previous methods for diversity underperform in this setting, while human evaluation suggests that our proposed method achieves a high level of diversity with minimal effect to the output's fluency and adequacy.
Accelerating Deep Learning by Focusing on the Biggest Losers
Oct 02, 2019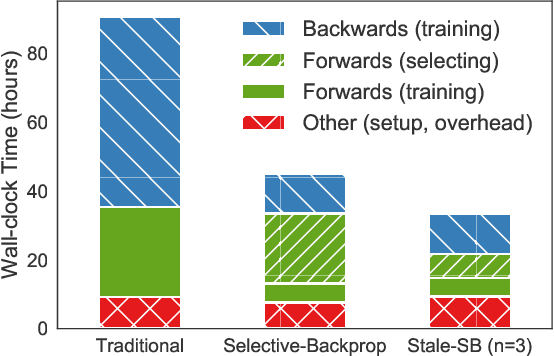
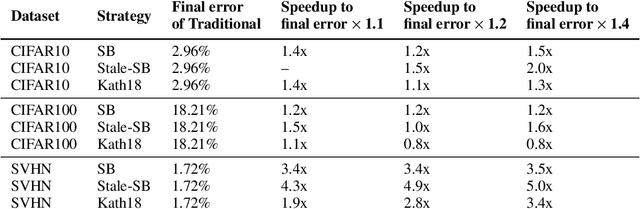

This paper introduces Selective-Backprop, a technique that accelerates the training of deep neural networks (DNNs) by prioritizing examples with high loss at each iteration. Selective-Backprop uses the output of a training example's forward pass to decide whether to use that example to compute gradients and update parameters, or to skip immediately to the next example. By reducing the number of computationally-expensive backpropagation steps performed, Selective-Backprop accelerates training. Evaluation on CIFAR10, CIFAR100, and SVHN, across a variety of modern image models, shows that Selective-Backprop converges to target error rates up to 3.5x faster than with standard SGD and between 1.02--1.8x faster than a state-of-the-art importance sampling approach. Further acceleration of 26% can be achieved by using stale forward pass results for selection, thus also skipping forward passes of low priority examples.
Scaling Video Analytics on Constrained Edge Nodes
May 24, 2019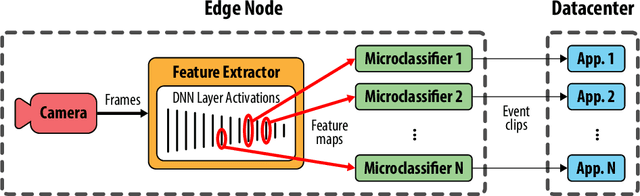
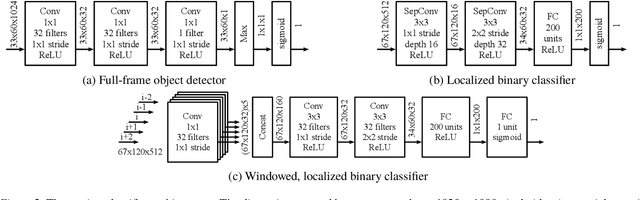


As video camera deployments continue to grow, the need to process large volumes of real-time data strains wide area network infrastructure. When per-camera bandwidth is limited, it is infeasible for applications such as traffic monitoring and pedestrian tracking to offload high-quality video streams to a datacenter. This paper presents FilterForward, a new edge-to-cloud system that enables datacenter-based applications to process content from thousands of cameras by installing lightweight edge filters that backhaul only relevant video frames. FilterForward introduces fast and expressive per-application microclassifiers that share computation to simultaneously detect dozens of events on computationally constrained edge nodes. Only matching events are transmitted to the cloud. Evaluation on two real-world camera feed datasets shows that FilterForward reduces bandwidth use by an order of magnitude while improving computational efficiency and event detection accuracy for challenging video content.
EDF: Ensemble, Distill, and Fuse for Easy Video Labeling
Dec 10, 2018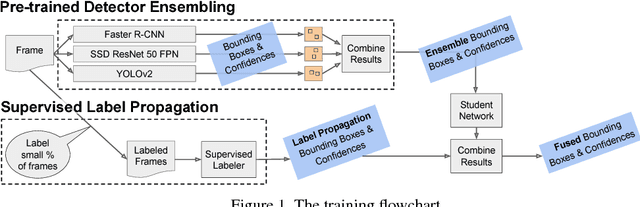
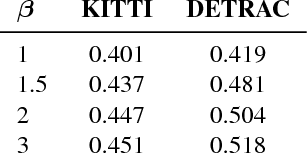
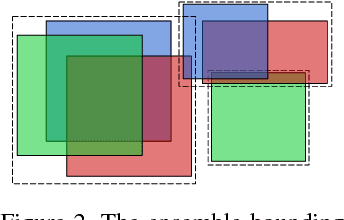

We present a way to rapidly bootstrap object detection on unseen videos using minimal human annotations. We accomplish this by combining two complementary sources of knowledge (one generic and the other specific) using bounding box merging and model distillation. The first (generic) knowledge source is obtained from ensembling pre-trained object detectors using a novel bounding box merging and confidence reweighting scheme. We make the observation that model distillation with data augmentation can train a specialized detector that outperforms the noisy labels it was trained on, and train a Student Network on the ensemble detections that obtains higher mAP than the ensemble itself. The second (specialized) knowledge source comes from training a detector (which we call the Supervised Labeler) on a labeled subset of the video to generate detections on the unlabeled portion. We demonstrate on two popular vehicular datasets that these techniques work to emit bounding boxes for all vehicles in the frame with higher mean average precision (mAP) than any of the reference networks used, and that the combination of ensembled and human-labeled data produces object detections that outperform either alone.
Clipper: A Low-Latency Online Prediction Serving System
Feb 28, 2017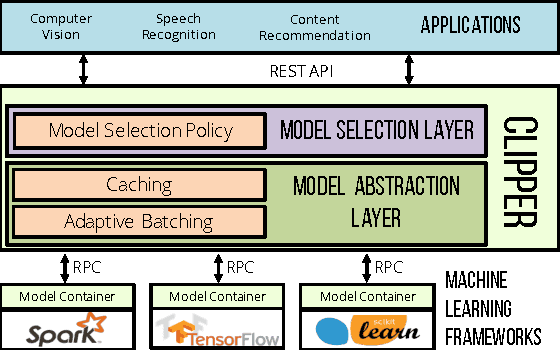
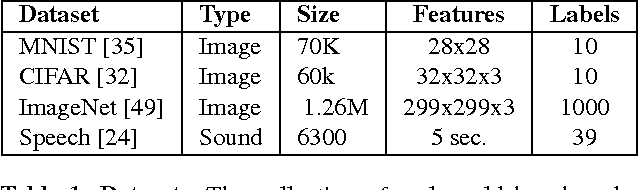
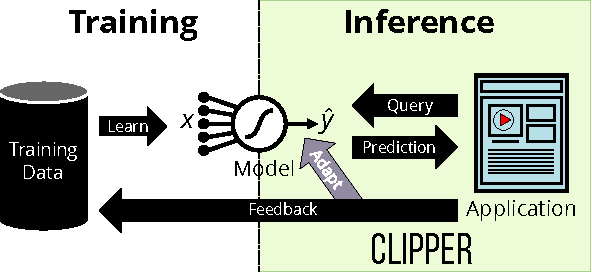

Machine learning is being deployed in a growing number of applications which demand real-time, accurate, and robust predictions under heavy query load. However, most machine learning frameworks and systems only address model training and not deployment. In this paper, we introduce Clipper, a general-purpose low-latency prediction serving system. Interposing between end-user applications and a wide range of machine learning frameworks, Clipper introduces a modular architecture to simplify model deployment across frameworks and applications. Furthermore, by introducing caching, batching, and adaptive model selection techniques, Clipper reduces prediction latency and improves prediction throughput, accuracy, and robustness without modifying the underlying machine learning frameworks. We evaluate Clipper on four common machine learning benchmark datasets and demonstrate its ability to meet the latency, accuracy, and throughput demands of online serving applications. Finally, we compare Clipper to the TensorFlow Serving system and demonstrate that we are able to achieve comparable throughput and latency while enabling model composition and online learning to improve accuracy and render more robust predictions.