 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Safe Diversity in NLG via Imitation Learning
Paper and Code
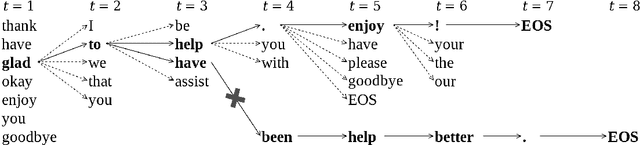

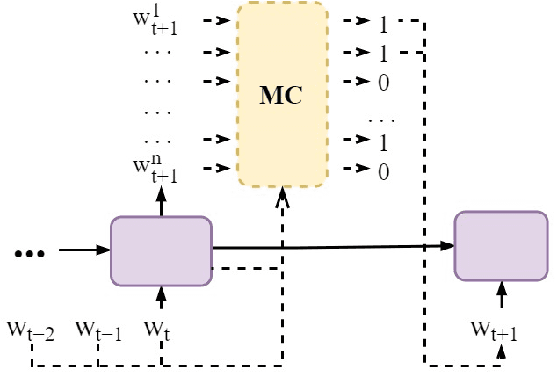
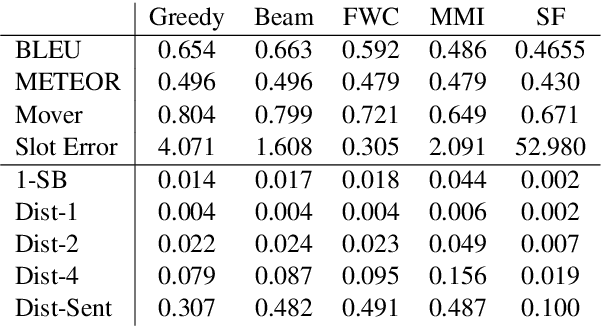
Deep-learning models for language generation tasks tend to produce repetitive output. Various methods have been proposed to encourage lexical diversity during decoding, but this often comes at a cost to the perceived fluency and adequacy of the output. In this work, we propose to ameliorate this cost by using an Imitation Learning approach to explore the level of diversity that a language generation model can safely produce. Specifically, we augment the decoding process with a meta-classifier trained to distinguish which words at any given timestep will lead to high-quality output. We focus our experiments on concept-to-text generation where models are sensitive to the inclusion of irrelevant words due to the strict relation between input and output. Our analysis shows that previous methods for diversity underperform in this setting, while human evaluation suggests that our proposed method achieves a high level of diversity with minimal effect to the output's fluency and adequacy.