 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIDK Cascades: Fast Deep Learning by Learning not to Overthink
Jun 27, 2018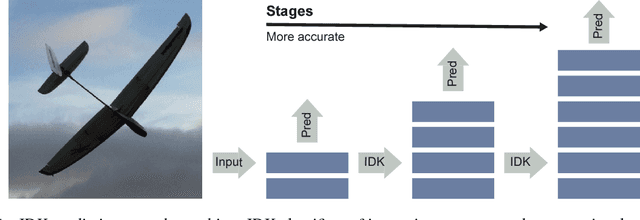


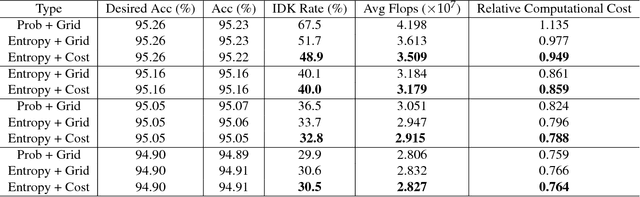
Advances in deep learning have led to substantial increases in prediction accuracy but have been accompanied by increases in the cost of rendering predictions. We conjecture that fora majority of real-world inputs, the recent advances in deep learning have created models that effectively "overthink" on simple inputs. In this paper, we revisit the classic question of building model cascades that primarily leverage class asymmetry to reduce cost. We introduce the "I Don't Know"(IDK) prediction cascades framework, a general framework to systematically compose a set of pre-trained models to accelerate inference without a loss in prediction accuracy. We propose two search based methods for constructing cascades as well as a new cost-aware objective within this framework. The proposed IDK cascade framework can be easily adopted in the existing model serving systems without additional model re-training. We evaluate the proposed techniques on a range of benchmarks to demonstrate the effectiveness of the proposed framework.
Composing Meta-Policies for Autonomous Driving Using Hierarchical Deep Reinforcement Learning
Nov 04, 2017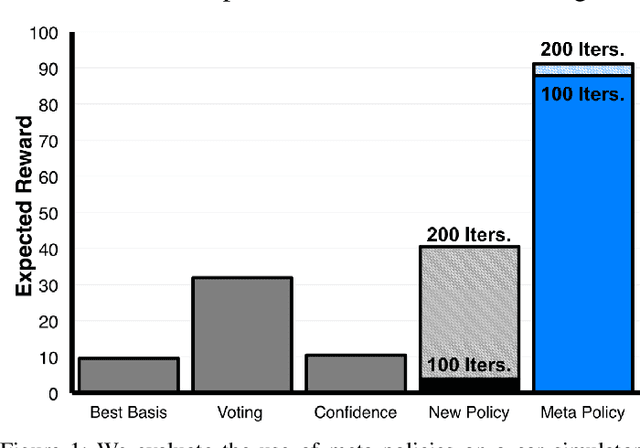
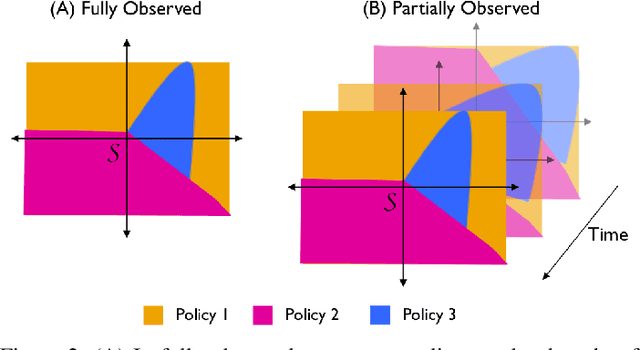
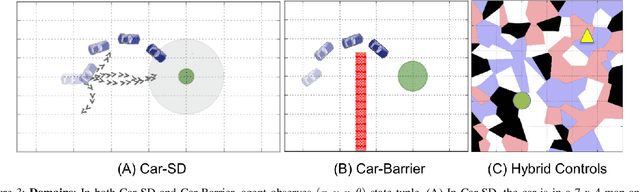
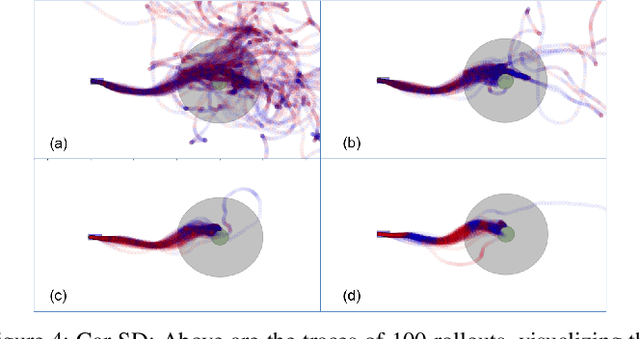
Rather than learning new control policies for each new task, it is possible, when tasks share some structure, to compose a "meta-policy" from previously learned policies. This paper reports results from experiments using Deep Reinforcement Learning on a continuous-state, discrete-action autonomous driving simulator. We explore how Deep Neural Networks can represent meta-policies that switch among a set of previously learned policies, specifically in settings where the dynamics of a new scenario are composed of a mixture of previously learned dynamics and where the state observation is possibly corrupted by sensing noise. We also report the results of experiments varying dynamics mixes, distractor policies, magnitudes/distributions of sensing noise, and obstacles. In a fully observed experiment, the meta-policy learning algorithm achieves 2.6x the reward achieved by the next best policy composition technique with 80% less exploration. In a partially observed experiment, the meta-policy learning algorithm converges after 50 iterations while a direct application of RL fails to converge even after 200 iterations.
Clipper: A Low-Latency Online Prediction Serving System
Feb 28, 2017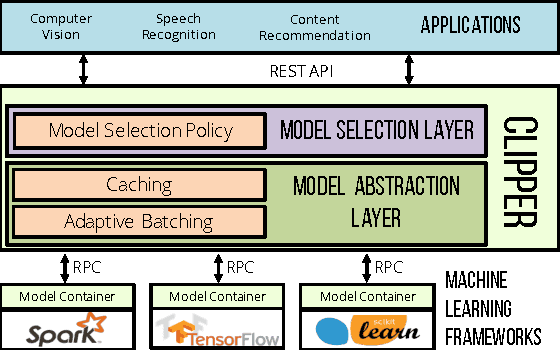
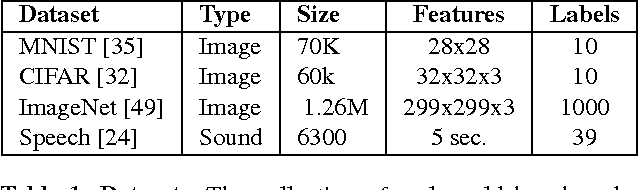
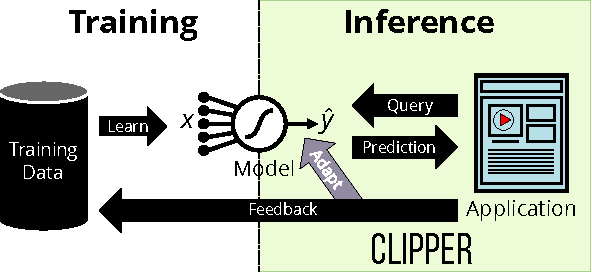

Machine learning is being deployed in a growing number of applications which demand real-time, accurate, and robust predictions under heavy query load. However, most machine learning frameworks and systems only address model training and not deployment. In this paper, we introduce Clipper, a general-purpose low-latency prediction serving system. Interposing between end-user applications and a wide range of machine learning frameworks, Clipper introduces a modular architecture to simplify model deployment across frameworks and applications. Furthermore, by introducing caching, batching, and adaptive model selection techniques, Clipper reduces prediction latency and improves prediction throughput, accuracy, and robustness without modifying the underlying machine learning frameworks. We evaluate Clipper on four common machine learning benchmark datasets and demonstrate its ability to meet the latency, accuracy, and throughput demands of online serving applications. Finally, we compare Clipper to the TensorFlow Serving system and demonstrate that we are able to achieve comparable throughput and latency while enabling model composition and online learning to improve accuracy and render more robust predictions.