 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComposing Meta-Policies for Autonomous Driving Using Hierarchical Deep Reinforcement Learning
Paper and Code
Nov 04, 2017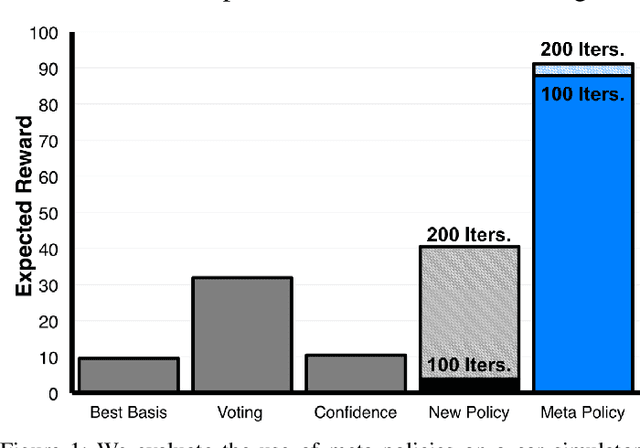
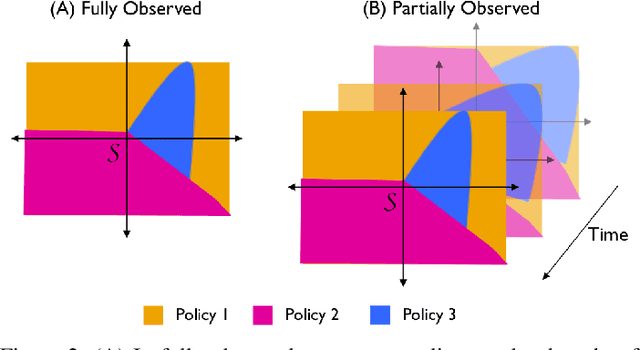
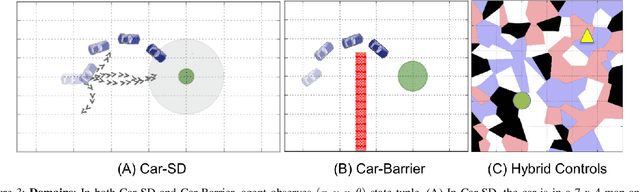
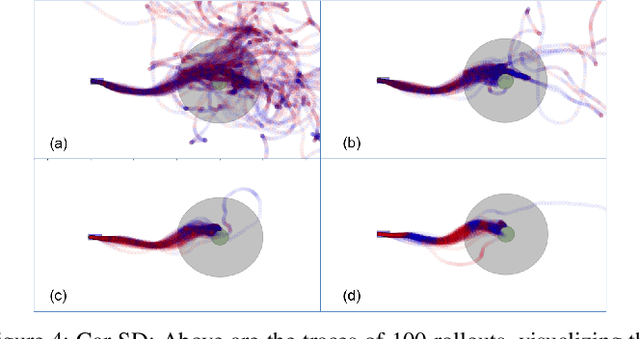
Rather than learning new control policies for each new task, it is possible, when tasks share some structure, to compose a "meta-policy" from previously learned policies. This paper reports results from experiments using Deep Reinforcement Learning on a continuous-state, discrete-action autonomous driving simulator. We explore how Deep Neural Networks can represent meta-policies that switch among a set of previously learned policies, specifically in settings where the dynamics of a new scenario are composed of a mixture of previously learned dynamics and where the state observation is possibly corrupted by sensing noise. We also report the results of experiments varying dynamics mixes, distractor policies, magnitudes/distributions of sensing noise, and obstacles. In a fully observed experiment, the meta-policy learning algorithm achieves 2.6x the reward achieved by the next best policy composition technique with 80% less exploration. In a partially observed experiment, the meta-policy learning algorithm converges after 50 iterations while a direct application of RL fails to converge even after 200 iterations.