 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIMPACT: Importance Weighted Asynchronous Architectures with Clipped Target Networks
Jan 23, 2020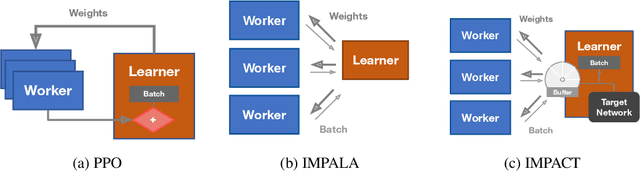
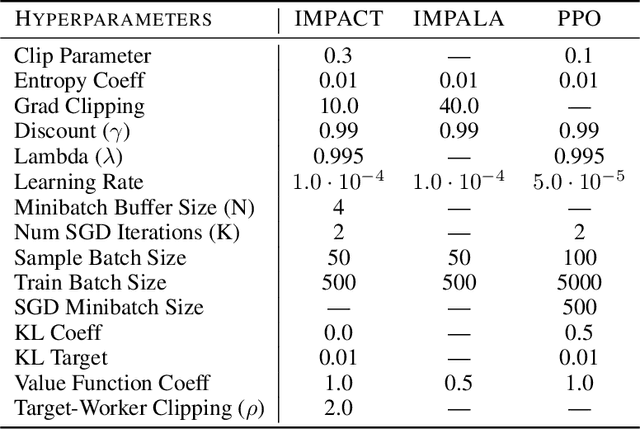
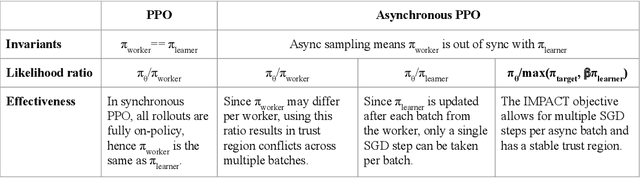
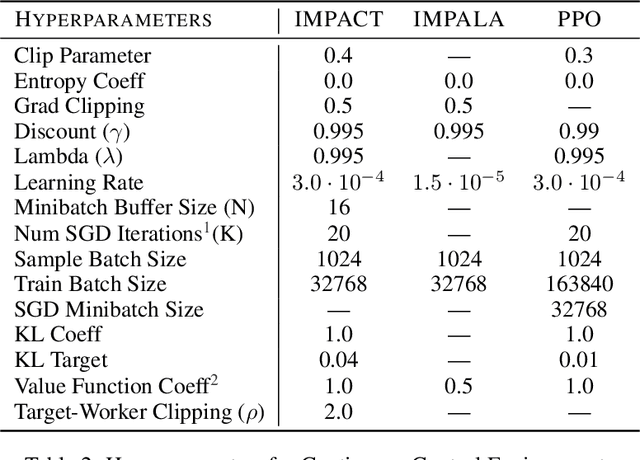
The practical usage of reinforcement learning agents is often bottlenecked by the duration of training time. To accelerate training, practitioners often turn to distributed reinforcement learning architectures to parallelize and accelerate the training process. However, modern methods for scalable reinforcement learning (RL) often tradeoff between the throughput of samples that an RL agent can learn from (sample throughput) and the quality of learning from each sample (sample efficiency). In these scalable RL architectures, as one increases sample throughput (i.e. increasing parallelization in IMPALA), sample efficiency drops significantly. To address this, we propose a new distributed reinforcement learning algorithm, IMPACT. IMPACT extends IMPALA with three changes: a target network for stabilizing the surrogate objective, a circular buffer, and truncated importance sampling. In discrete action-space environments, we show that IMPACT attains higher reward and, simultaneously, achieves up to 30% decrease in training wall-time than that of IMPALA. For continuous control environments, IMPACT trains faster than existing scalable agents while preserving the sample efficiency of synchronous PPO.
HyperSched: Dynamic Resource Reallocation for Model Development on a Deadline
Jan 08, 2020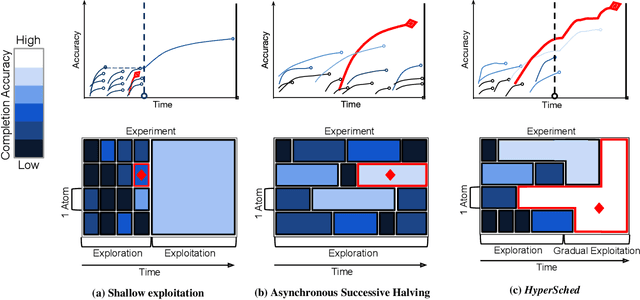
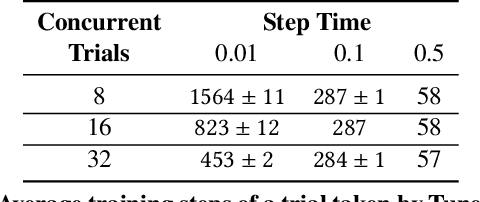
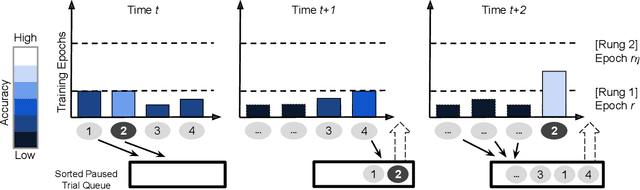

Prior research in resource scheduling for machine learning training workloads has largely focused on minimizing job completion times. Commonly, these model training workloads collectively search over a large number of parameter values that control the learning process in a hyperparameter search. It is preferable to identify and maximally provision the best-performing hyperparameter configuration (trial) to achieve the highest accuracy result as soon as possible. To optimally trade-off evaluating multiple configurations and training the most promising ones by a fixed deadline, we design and build HyperSched -- a dynamic application-level resource scheduler to track, identify, and preferentially allocate resources to the best performing trials to maximize accuracy by the deadline. HyperSched leverages three properties of a hyperparameter search workload over-looked in prior work - trial disposability, progressively identifiable rankings among different configurations, and space-time constraints - to outperform standard hyperparameter search algorithms across a variety of benchmarks.
Ray: A Distributed Framework for Emerging AI Applications
Sep 30, 2018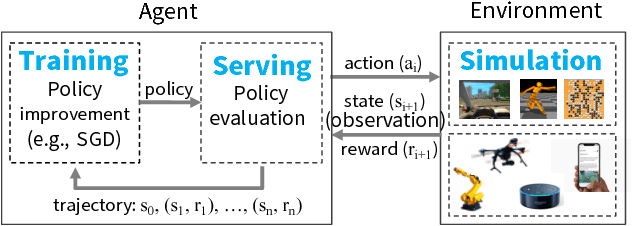


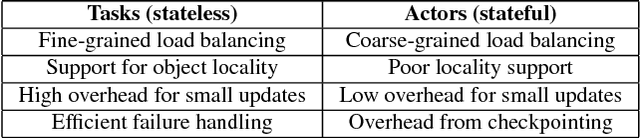
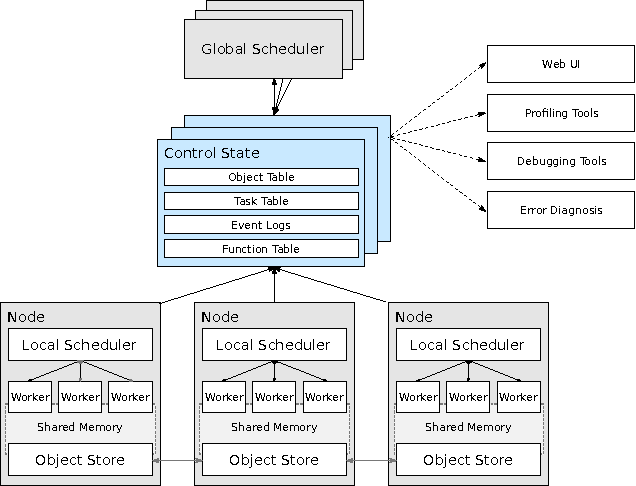
The next generation of AI applications will continuously interact with the environment and learn from these interactions. These applications impose new and demanding systems requirements, both in terms of performance and flexibility. In this paper, we consider these requirements and present Ray---a distributed system to address them. Ray implements a unified interface that can express both task-parallel and actor-based computations, supported by a single dynamic execution engine. To meet the performance requirements, Ray employs a distributed scheduler and a distributed and fault-tolerant store to manage the system's control state. In our experiments, we demonstrate scaling beyond 1.8 million tasks per second and better performance than existing specialized systems for several challenging reinforcement learning applications.
Tune: A Research Platform for Distributed Model Selection and Training
Jul 13, 2018


Modern machine learning algorithms are increasingly computationally demanding, requiring specialized hardware and distributed computation to achieve high performance in a reasonable time frame. Many hyperparameter search algorithms have been proposed for improving the efficiency of model selection, however their adaptation to the distributed compute environment is often ad-hoc. We propose Tune, a unified framework for model selection and training that provides a narrow-waist interface between training scripts and search algorithms. We show that this interface meets the requirements for a broad range of hyperparameter search algorithms, allows straightforward scaling of search to large clusters, and simplifies algorithm implementation. We demonstrate the implementation of several state-of-the-art hyperparameter search algorithms in Tune. Tune is available at http://ray.readthedocs.io/en/latest/tune.html.
RLlib: Abstractions for Distributed Reinforcement Learning
Jun 29, 2018

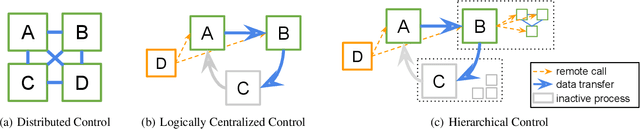

Reinforcement learning (RL) algorithms involve the deep nesting of highly irregular computation patterns, each of which typically exhibits opportunities for distributed computation. We argue for distributing RL components in a composable way by adapting algorithms for top-down hierarchical control, thereby encapsulating parallelism and resource requirements within short-running compute tasks. We demonstrate the benefits of this principle through RLlib: a library that provides scalable software primitives for RL. These primitives enable a broad range of algorithms to be implemented with high performance, scalability, and substantial code reuse. RLlib is available at https://rllib.io/.
Composing Meta-Policies for Autonomous Driving Using Hierarchical Deep Reinforcement Learning
Nov 04, 2017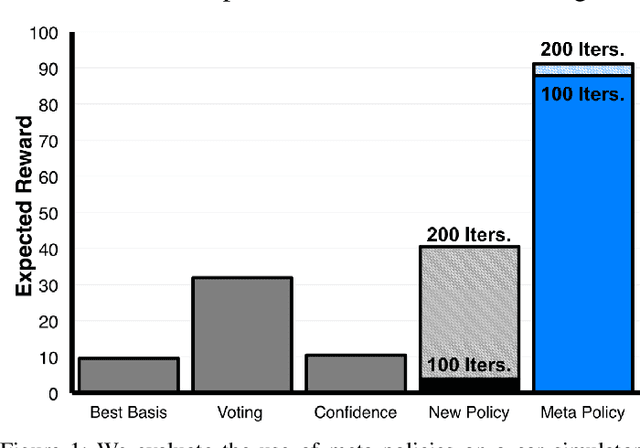
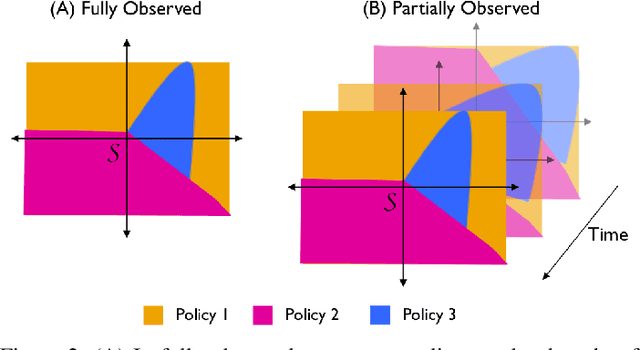
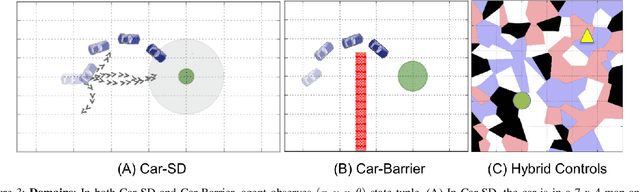
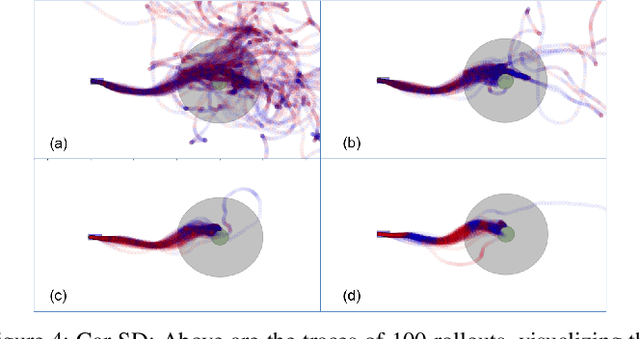
Rather than learning new control policies for each new task, it is possible, when tasks share some structure, to compose a "meta-policy" from previously learned policies. This paper reports results from experiments using Deep Reinforcement Learning on a continuous-state, discrete-action autonomous driving simulator. We explore how Deep Neural Networks can represent meta-policies that switch among a set of previously learned policies, specifically in settings where the dynamics of a new scenario are composed of a mixture of previously learned dynamics and where the state observation is possibly corrupted by sensing noise. We also report the results of experiments varying dynamics mixes, distractor policies, magnitudes/distributions of sensing noise, and obstacles. In a fully observed experiment, the meta-policy learning algorithm achieves 2.6x the reward achieved by the next best policy composition technique with 80% less exploration. In a partially observed experiment, the meta-policy learning algorithm converges after 50 iterations while a direct application of RL fails to converge even after 200 iterations.
Real-Time Machine Learning: The Missing Pieces
May 19, 2017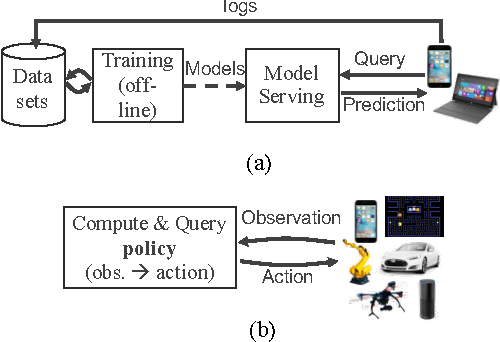
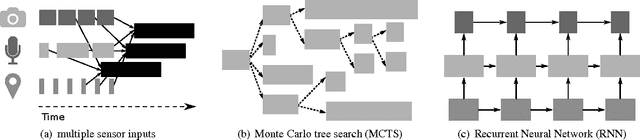
Machine learning applications are increasingly deployed not only to serve predictions using static models, but also as tightly-integrated components of feedback loops involving dynamic, real-time decision making. These applications pose a new set of requirements, none of which are difficult to achieve in isolation, but the combination of which creates a challenge for existing distributed execution frameworks: computation with millisecond latency at high throughput, adaptive construction of arbitrary task graphs, and execution of heterogeneous kernels over diverse sets of resources. We assert that a new distributed execution framework is needed for such ML applications and propose a candidate approach with a proof-of-concept architecture that achieves a 63x performance improvement over a state-of-the-art execution framework for a representative application.
HIRL: Hierarchical Inverse Reinforcement Learning for Long-Horizon Tasks with Delayed Rewards
Apr 21, 2016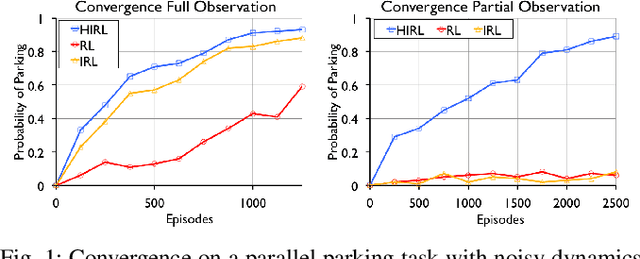



Reinforcement Learning (RL) struggles in problems with delayed rewards, and one approach is to segment the task into sub-tasks with incremental rewards. We propose a framework called Hierarchical Inverse Reinforcement Learning (HIRL), which is a model for learning sub-task structure from demonstrations. HIRL decomposes the task into sub-tasks based on transitions that are consistent across demonstrations. These transitions are defined as changes in local linearity w.r.t to a kernel function. Then, HIRL uses the inferred structure to learn reward functions local to the sub-tasks but also handle any global dependencies such as sequentiality. We have evaluated HIRL on several standard RL benchmarks: Parallel Parking with noisy dynamics, Two-Link Pendulum, 2D Noisy Motion Planning, and a Pinball environment. In the parallel parking task, we find that rewards constructed with HIRL converge to a policy with an 80% success rate in 32% fewer time-steps than those constructed with Maximum Entropy Inverse RL (MaxEnt IRL), and with partial state observation, the policies learned with IRL fail to achieve this accuracy while HIRL still converges. We further find that that the rewards learned with HIRL are robust to environment noise where they can tolerate 1 stdev. of random perturbation in the poses in the environment obstacles while maintaining roughly the same convergence rate. We find that HIRL rewards can converge up-to 6x faster than rewards constructed with IRL.