 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Machine Learning: The Missing Pieces
Paper and Code
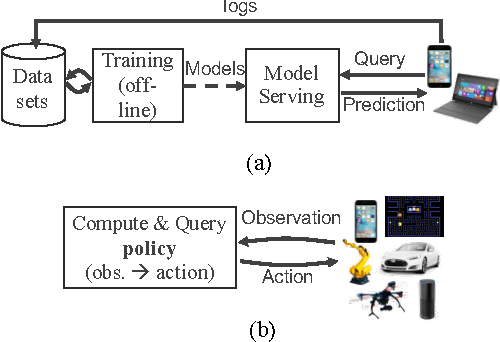
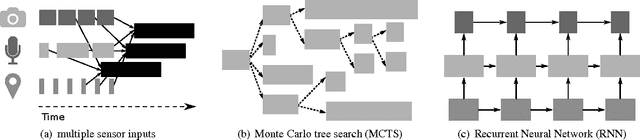
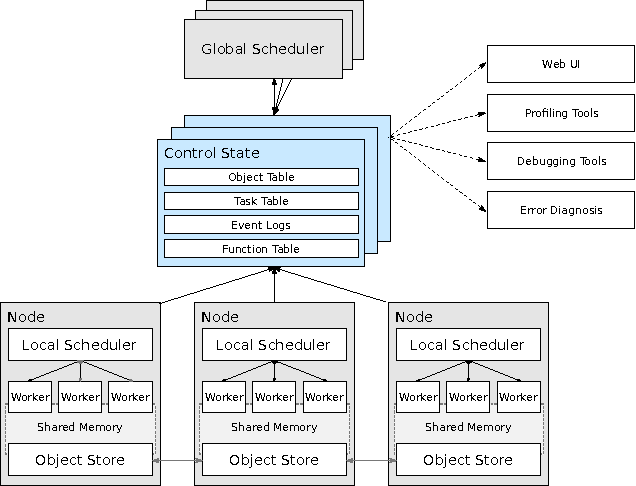
Machine learning applications are increasingly deployed not only to serve predictions using static models, but also as tightly-integrated components of feedback loops involving dynamic, real-time decision making. These applications pose a new set of requirements, none of which are difficult to achieve in isolation, but the combination of which creates a challenge for existing distributed execution frameworks: computation with millisecond latency at high throughput, adaptive construction of arbitrary task graphs, and execution of heterogeneous kernels over diverse sets of resources. We assert that a new distributed execution framework is needed for such ML applications and propose a candidate approach with a proof-of-concept architecture that achieves a 63x performance improvement over a state-of-the-art execution framework for a representative application.