 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHoplite: Efficient Collective Communication for Task-Based Distributed Systems
Feb 13, 2020


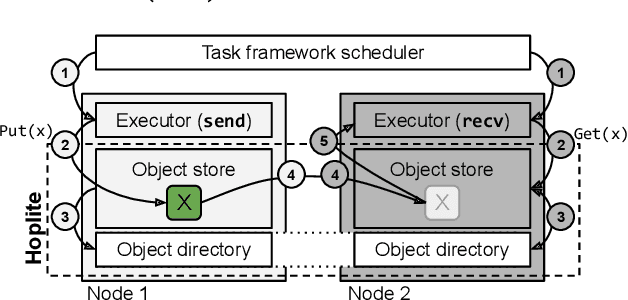
Collective communication systems such as MPI offer high performance group communication primitives at the cost of application flexibility. Today, an increasing number of distributed applications (e.g, reinforcement learning) require flexibility in expressing dynamic and asynchronous communication patterns. To accommodate these applications, task-based distributed computing frameworks (e.g., Ray, Dask, Hydro) have become popular as they allow applications to dynamically specify communication by invoking tasks, or functions, at runtime. This design makes efficient collective communication challenging because (1) the group of communicating processes is chosen at runtime, and (2) processes may not all be ready at the same time. We design and implement Hoplite, a communication layer for task-based distributed systems that achieves high performance collective communication without compromising application flexibility. The key idea of Hoplite is to use distributed protocols to compute a data transfer schedule on the fly. This enables the same optimizations used in traditional collective communication, but for applications that specify the communication incrementally. We show that Hoplite can achieve similar performance compared with a traditional collective communication library, MPICH. We port a popular distributed computing framework, Ray, on atop of Hoplite. We show that Hoplite can speed up asynchronous parameter server and distributed reinforcement learning workloads that are difficult to execute efficiently with traditional collective communication by up to 8.1x and 3.9x, respectively.
Policy Gradient Search: Online Planning and Expert Iteration without Search Trees
Apr 07, 2019


Monte Carlo Tree Search (MCTS) algorithms perform simulation-based search to improve policies online. During search, the simulation policy is adapted to explore the most promising lines of play. MCTS has been used by state-of-the-art programs for many problems, however a disadvantage to MCTS is that it estimates the values of states with Monte Carlo averages, stored in a search tree; this does not scale to games with very high branching factors. We propose an alternative simulation-based search method, Policy Gradient Search (PGS), which adapts a neural network simulation policy online via policy gradient updates, avoiding the need for a search tree. In Hex, PGS achieves comparable performance to MCTS, and an agent trained using Expert Iteration with PGS was able defeat MoHex 2.0, the strongest open-source Hex agent, in 9x9 Hex.
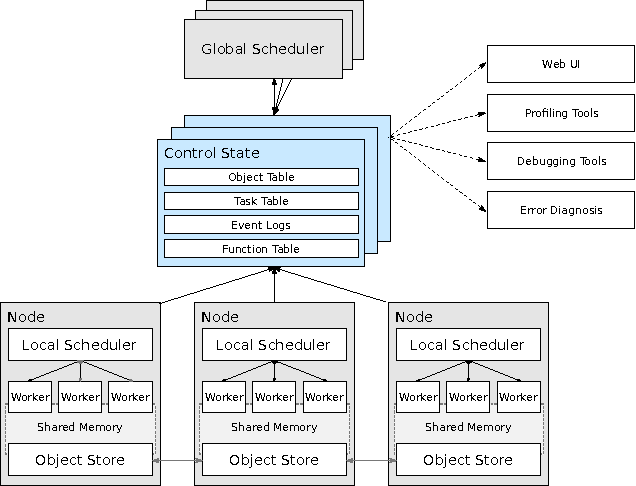
Ray: A Distributed Framework for Emerging AI Applications
Sep 30, 2018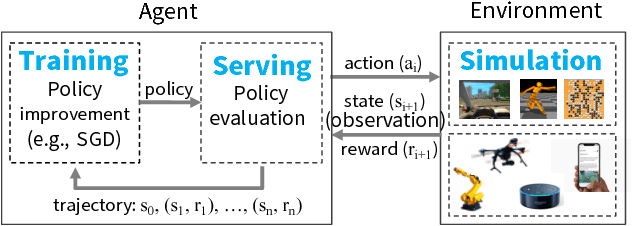


The next generation of AI applications will continuously interact with the environment and learn from these interactions. These applications impose new and demanding systems requirements, both in terms of performance and flexibility. In this paper, we consider these requirements and present Ray---a distributed system to address them. Ray implements a unified interface that can express both task-parallel and actor-based computations, supported by a single dynamic execution engine. To meet the performance requirements, Ray employs a distributed scheduler and a distributed and fault-tolerant store to manage the system's control state. In our experiments, we demonstrate scaling beyond 1.8 million tasks per second and better performance than existing specialized systems for several challenging reinforcement learning applications.
Tune: A Research Platform for Distributed Model Selection and Training
Jul 13, 2018


Modern machine learning algorithms are increasingly computationally demanding, requiring specialized hardware and distributed computation to achieve high performance in a reasonable time frame. Many hyperparameter search algorithms have been proposed for improving the efficiency of model selection, however their adaptation to the distributed compute environment is often ad-hoc. We propose Tune, a unified framework for model selection and training that provides a narrow-waist interface between training scripts and search algorithms. We show that this interface meets the requirements for a broad range of hyperparameter search algorithms, allows straightforward scaling of search to large clusters, and simplifies algorithm implementation. We demonstrate the implementation of several state-of-the-art hyperparameter search algorithms in Tune. Tune is available at http://ray.readthedocs.io/en/latest/tune.html.
RLlib: Abstractions for Distributed Reinforcement Learning
Jun 29, 2018

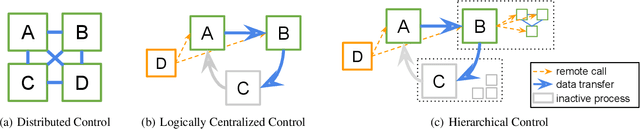

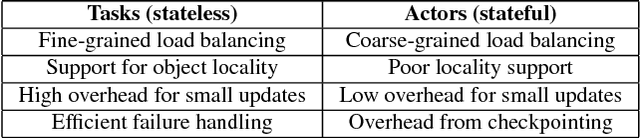
Reinforcement learning (RL) algorithms involve the deep nesting of highly irregular computation patterns, each of which typically exhibits opportunities for distributed computation. We argue for distributing RL components in a composable way by adapting algorithms for top-down hierarchical control, thereby encapsulating parallelism and resource requirements within short-running compute tasks. We demonstrate the benefits of this principle through RLlib: a library that provides scalable software primitives for RL. These primitives enable a broad range of algorithms to be implemented with high performance, scalability, and substantial code reuse. RLlib is available at https://rllib.io/.
Discovering Causal Signals in Images
Oct 31, 2017


This paper establishes the existence of observable footprints that reveal the "causal dispositions" of the object categories appearing in collections of images. We achieve this goal in two steps. First, we take a learning approach to observational causal discovery, and build a classifier that achieves state-of-the-art performance on finding the causal direction between pairs of random variables, given samples from their joint distribution. Second, we use our causal direction classifier to effectively distinguish between features of objects and features of their contexts in collections of static images. Our experiments demonstrate the existence of a relation between the direction of causality and the difference between objects and their contexts, and by the same token, the existence of observable signals that reveal the causal dispositions of objects.
Real-Time Machine Learning: The Missing Pieces
May 19, 2017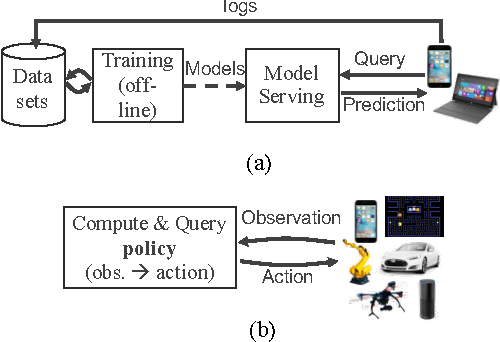
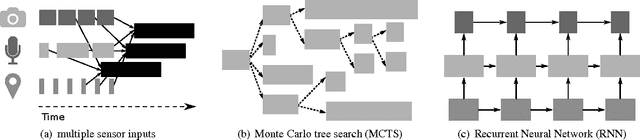
Machine learning applications are increasingly deployed not only to serve predictions using static models, but also as tightly-integrated components of feedback loops involving dynamic, real-time decision making. These applications pose a new set of requirements, none of which are difficult to achieve in isolation, but the combination of which creates a challenge for existing distributed execution frameworks: computation with millisecond latency at high throughput, adaptive construction of arbitrary task graphs, and execution of heterogeneous kernels over diverse sets of resources. We assert that a new distributed execution framework is needed for such ML applications and propose a candidate approach with a proof-of-concept architecture that achieves a 63x performance improvement over a state-of-the-art execution framework for a representative application.
A Linearly-Convergent Stochastic L-BFGS Algorithm
Apr 13, 2016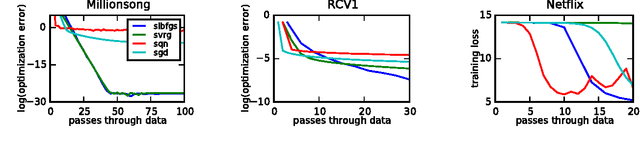
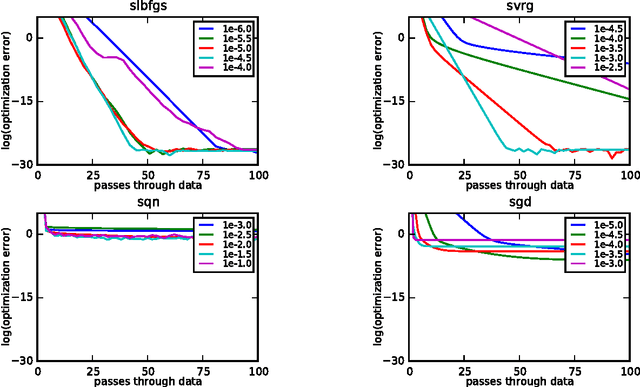
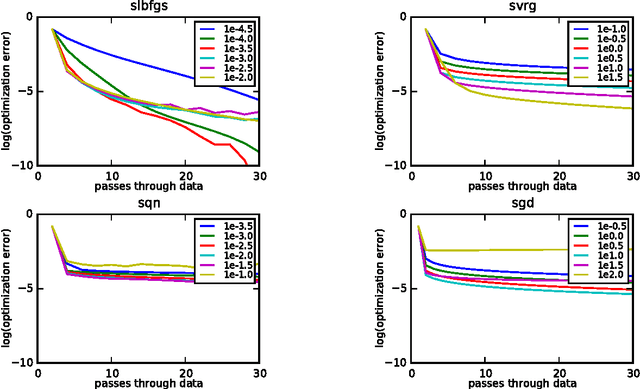
We propose a new stochastic L-BFGS algorithm and prove a linear convergence rate for strongly convex and smooth functions. Our algorithm draws heavily from a recent stochastic variant of L-BFGS proposed in Byrd et al. (2014) as well as a recent approach to variance reduction for stochastic gradient descent from Johnson and Zhang (2013). We demonstrate experimentally that our algorithm performs well on large-scale convex and non-convex optimization problems, exhibiting linear convergence and rapidly solving the optimization problems to high levels of precision. Furthermore, we show that our algorithm performs well for a wide-range of step sizes, often differing by several orders of magnitude.
No Regret Bound for Extreme Bandits
Apr 11, 2016Algorithms for hyperparameter optimization abound, all of which work well under different and often unverifiable assumptions. Motivated by the general challenge of sequentially choosing which algorithm to use, we study the more specific task of choosing among distributions to use for random hyperparameter optimization. This work is naturally framed in the extreme bandit setting, which deals with sequentially choosing which distribution from a collection to sample in order to minimize (maximize) the single best cost (reward). Whereas the distributions in the standard bandit setting are primarily characterized by their means, a number of subtleties arise when we care about the minimal cost as opposed to the average cost. For example, there may not be a well-defined "best" distribution as there is in the standard bandit setting. The best distribution depends on the rewards that have been obtained and on the remaining time horizon. Whereas in the standard bandit setting, it is sensible to compare policies with an oracle which plays the single best arm, in the extreme bandit setting, there are multiple sensible oracle models. We define a sensible notion of "extreme regret" in the extreme bandit setting, which parallels the concept of regret in the standard bandit setting. We then prove that no policy can asymptotically achieve no extreme regret.
SparkNet: Training Deep Networks in Spark
Feb 28, 2016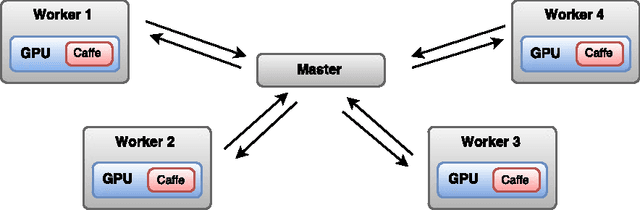


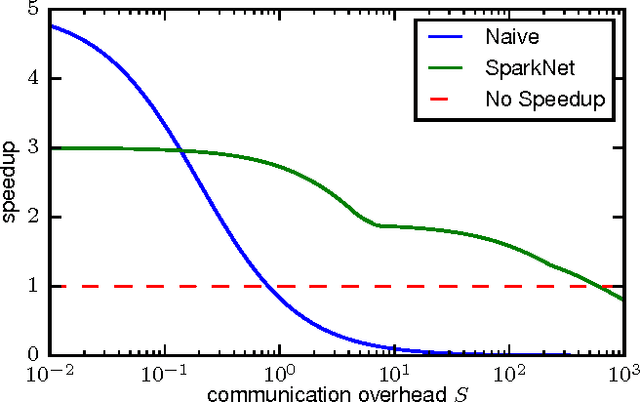
Training deep networks is a time-consuming process, with networks for object recognition often requiring multiple days to train. For this reason, leveraging the resources of a cluster to speed up training is an important area of work. However, widely-popular batch-processing computational frameworks like MapReduce and Spark were not designed to support the asynchronous and communication-intensive workloads of existing distributed deep learning systems. We introduce SparkNet, a framework for training deep networks in Spark. Our implementation includes a convenient interface for reading data from Spark RDDs, a Scala interface to the Caffe deep learning framework, and a lightweight multi-dimensional tensor library. Using a simple parallelization scheme for stochastic gradient descent, SparkNet scales well with the cluster size and tolerates very high-latency communication. Furthermore, it is easy to deploy and use with no parameter tuning, and it is compatible with existing Caffe models. We quantify the dependence of the speedup obtained by SparkNet on the number of machines, the communication frequency, and the cluster's communication overhead, and we benchmark our system's performance on the ImageNet dataset.