 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNumS: Scalable Array Programming for the Cloud
Jun 28, 2022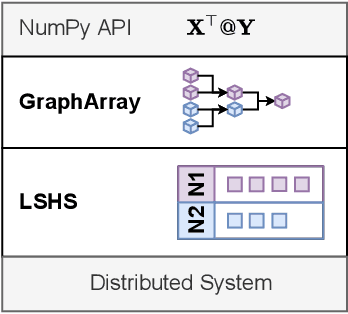

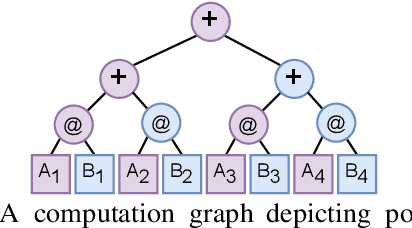
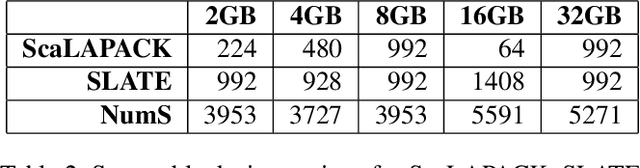
Scientists increasingly rely on Python tools to perform scalable distributed memory array operations using rich, NumPy-like expressions. However, many of these tools rely on dynamic schedulers optimized for abstract task graphs, which often encounter memory and network bandwidth-related bottlenecks due to sub-optimal data and operator placement decisions. Tools built on the message passing interface (MPI), such as ScaLAPACK and SLATE, have better scaling properties, but these solutions require specialized knowledge to use. In this work, we present NumS, an array programming library which optimizes NumPy-like expressions on task-based distributed systems. This is achieved through a novel scheduler called Load Simulated Hierarchical Scheduling (LSHS). LSHS is a local search method which optimizes operator placement by minimizing maximum memory and network load on any given node within a distributed system. Coupled with a heuristic for load balanced data layouts, our approach is capable of attaining communication lower bounds on some common numerical operations, and our empirical study shows that LSHS enhances performance on Ray by decreasing network load by a factor of 2x, requiring 4x less memory, and reducing execution time by 10x on the logistic regression problem. On terabyte-scale data, NumS achieves competitive performance to SLATE on DGEMM, up to 20x speedup over Dask on a key operation for tensor factorization, and a 2x speedup on logistic regression compared to Dask ML and Spark's MLlib.
Variance Reduction with Sparse Gradients
Jan 27, 2020
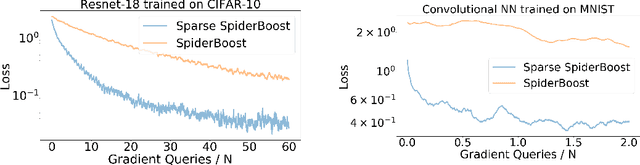
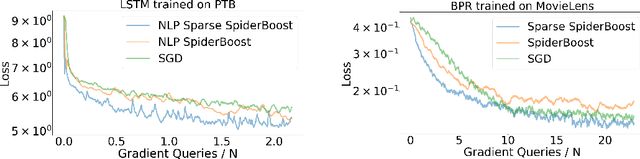
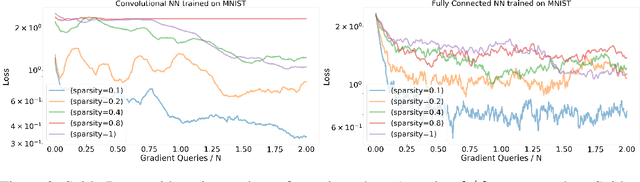
Variance reduction methods such as SVRG and SpiderBoost use a mixture of large and small batch gradients to reduce the variance of stochastic gradients. Compared to SGD, these methods require at least double the number of operations per update to model parameters. To reduce the computational cost of these methods, we introduce a new sparsity operator: The random-top-k operator. Our operator reduces computational complexity by estimating gradient sparsity exhibited in a variety of applications by combining the top-k operator and the randomized coordinate descent operator. With this operator, large batch gradients offer an extra benefit beyond variance reduction: A reliable estimate of gradient sparsity. Theoretically, our algorithm is at least as good as the best algorithm (SpiderBoost), and further excels in performance whenever the random-top-k operator captures gradient sparsity. Empirically, our algorithm consistently outperforms SpiderBoost using various models on various tasks including image classification, natural language processing, and sparse matrix factorization. We also provide empirical evidence to support the intuition behind our algorithm via a simple gradient entropy computation, which serves to quantify gradient sparsity at every iteration.
Ray: A Distributed Framework for Emerging AI Applications
Sep 30, 2018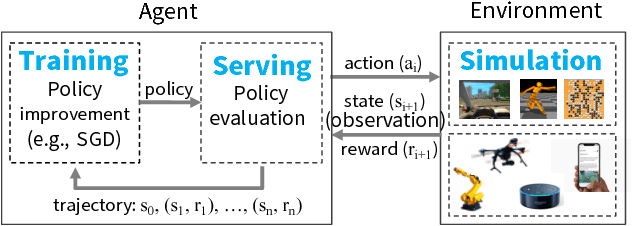


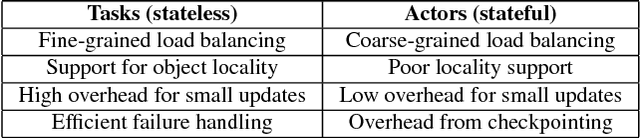
The next generation of AI applications will continuously interact with the environment and learn from these interactions. These applications impose new and demanding systems requirements, both in terms of performance and flexibility. In this paper, we consider these requirements and present Ray---a distributed system to address them. Ray implements a unified interface that can express both task-parallel and actor-based computations, supported by a single dynamic execution engine. To meet the performance requirements, Ray employs a distributed scheduler and a distributed and fault-tolerant store to manage the system's control state. In our experiments, we demonstrate scaling beyond 1.8 million tasks per second and better performance than existing specialized systems for several challenging reinforcement learning applications.