 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInventing painting styles through natural inspiration
May 19, 2023We propose two procedures to create painting styles using models trained only on natural images, providing objective proof that the model is not plagiarizing human art styles. In the first procedure we use the inductive bias from the artistic medium to achieve creative expression. Abstraction is achieved by using a reconstruction loss. The second procedure uses an additional natural image as inspiration to create a new style. These two procedures make it possible to invent new painting styles with no artistic training data. We believe that our approach can help pave the way for the ethical employment of generative AI in art, without infringing upon the originality of human creators.
Monte Carlo Tree Search based Hybrid Optimization of Variational Quantum Circuits
Mar 30, 2022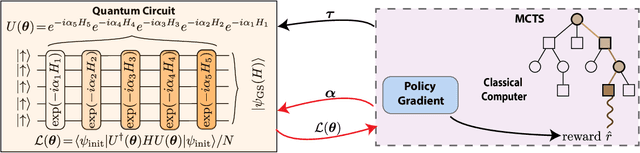

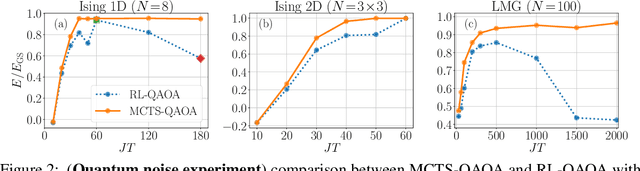
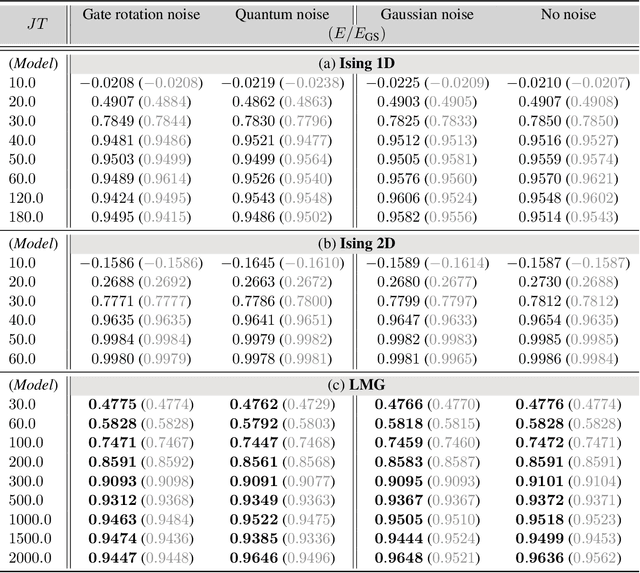
Variational quantum algorithms stand at the forefront of simulations on near-term and future fault-tolerant quantum devices. While most variational quantum algorithms involve only continuous optimization variables, the representational power of the variational ansatz can sometimes be significantly enhanced by adding certain discrete optimization variables, as is exemplified by the generalized quantum approximate optimization algorithm (QAOA). However, the hybrid discrete-continuous optimization problem in the generalized QAOA poses a challenge to the optimization. We propose a new algorithm called MCTS-QAOA, which combines a Monte Carlo tree search method with an improved natural policy gradient solver to optimize the discrete and continuous variables in the quantum circuit, respectively. We find that MCTS-QAOA has excellent noise-resilience properties and outperforms prior algorithms in challenging instances of the generalized QAOA.
Noise-Robust End-to-End Quantum Control using Deep Autoregressive Policy Networks
Dec 12, 2020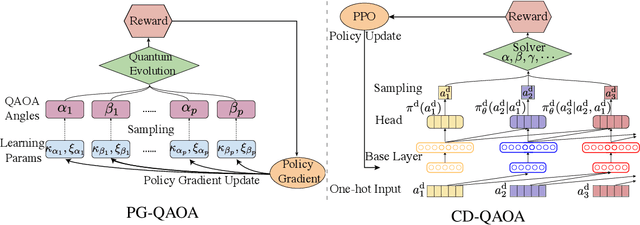
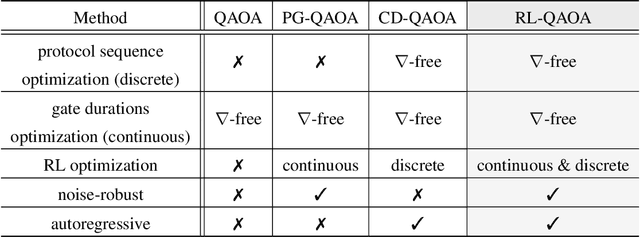
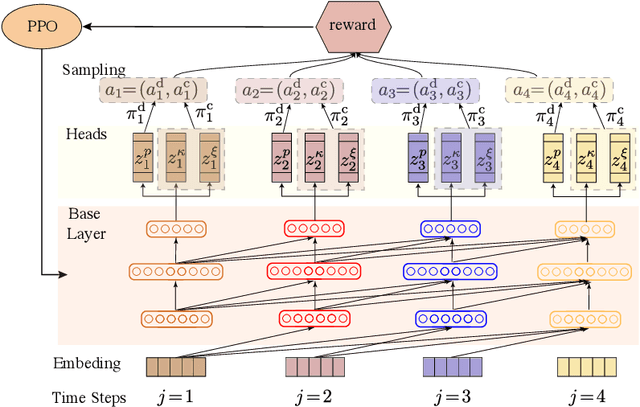

Variational quantum eigensolvers have recently received increased attention, as they enable the use of quantum computing devices to find solutions to complex problems, such as the ground energy and ground state of strongly-correlated quantum many-body systems. In many applications, it is the optimization of both continuous and discrete parameters that poses a formidable challenge. Using reinforcement learning (RL), we present a hybrid policy gradient algorithm capable of simultaneously optimizing continuous and discrete degrees of freedom in an uncertainty-resilient way. The hybrid policy is modeled by a deep autoregressive neural network to capture causality. We employ the algorithm to prepare the ground state of the nonintegrable quantum Ising model in a unitary process, parametrized by a generalized quantum approximate optimization ansatz: the RL agent solves the discrete combinatorial problem of constructing the optimal sequences of unitaries out of a predefined set and, at the same time, it optimizes the continuous durations for which these unitaries are applied. We demonstrate the noise-robust features of the agent by considering three sources of uncertainty: classical and quantum measurement noise, and errors in the control unitary durations. Our work exhibits the beneficial synergy between reinforcement learning and quantum control.
Reinforcement Learning for Many-Body Ground State Preparation based on Counter-Diabatic Driving
Oct 07, 2020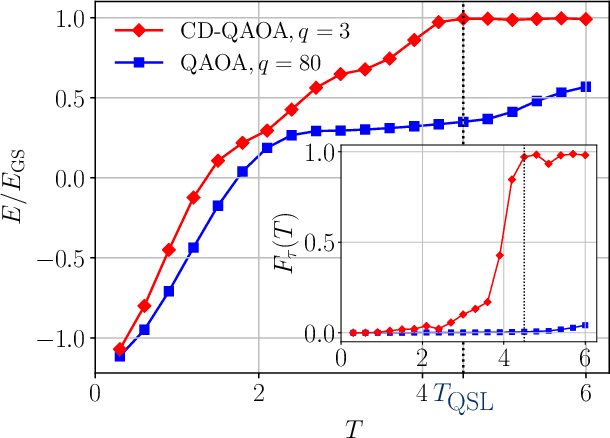

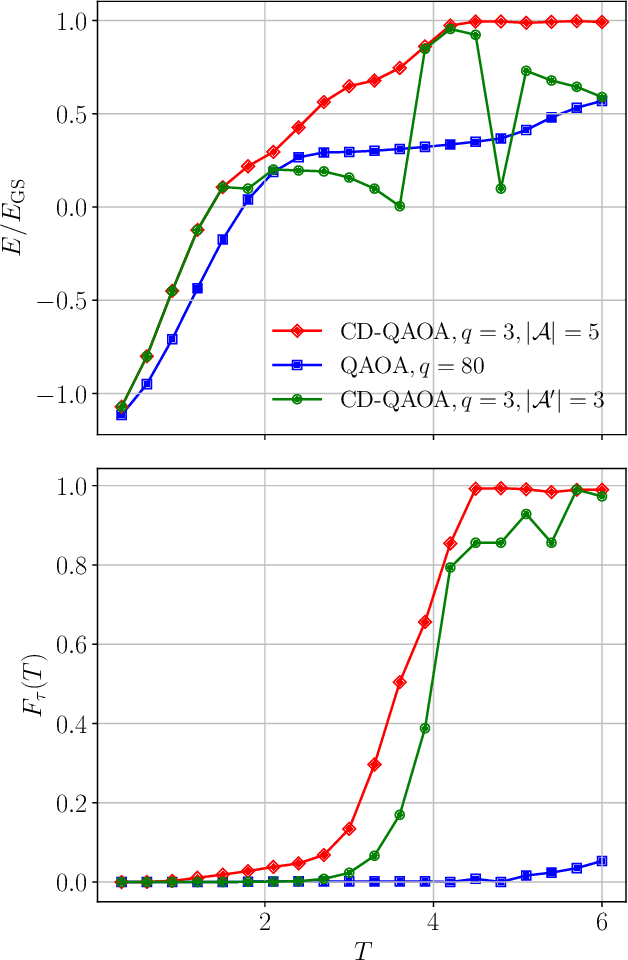
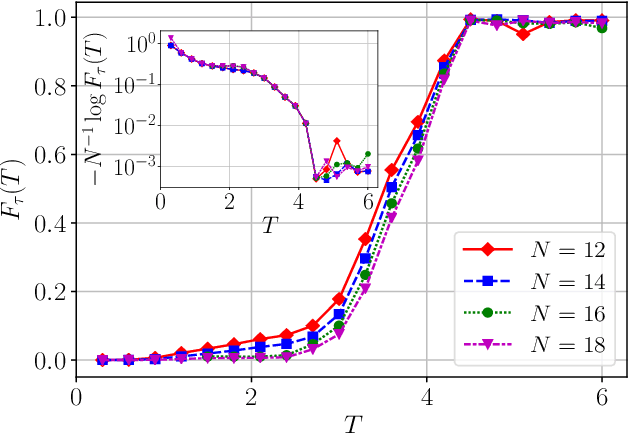
The Quantum Approximate Optimization Ansatz (QAOA) is a prominent example of variational quantum algorithms. We propose a generalized QAOA ansatz called CD-QAOA, which is inspired by the counter-diabatic (CD) driving procedure, designed for quantum many-body systems, and optimized using a reinforcement learning (RL) approach. The resulting hybrid control algorithm proves versatile in preparing the ground state of quantum-chaotic many-body spin chains, by minimizing the energy. We show that using terms occurring in the adiabatic gauge potential as additional control unitaries, it is possible to achieve fast high-fidelity many-body control away from the adiabatic regime. While each unitary retains the conventional QAOA-intrinsic continuous control degree of freedom such as the time duration, we take into account the order of the multiple available unitaries appearing in the control sequence as an additional discrete optimization problem. Endowing the policy gradient algorithm with an autoregressive deep learning architecture to capture causality, we train the RL agent to construct optimal sequences of unitaries. The algorithm has no access to the quantum state, and we find that the protocol learned on small systems may generalize to larger systems. By scanning a range of protocol durations, we present numerical evidence for a finite quantum speed limit in the nonintegrable mixed-field spin-1/2 Ising model, and for the suitability of the ansatz to prepare ground states of the spin-1 Heisenberg chain in the long-range and topologically ordered parameter regimes. This work paves the way to incorporate recent success from deep learning for the purpose of quantum many-body control.
Policy Gradient based Quantum Approximate Optimization Algorithm
Feb 04, 2020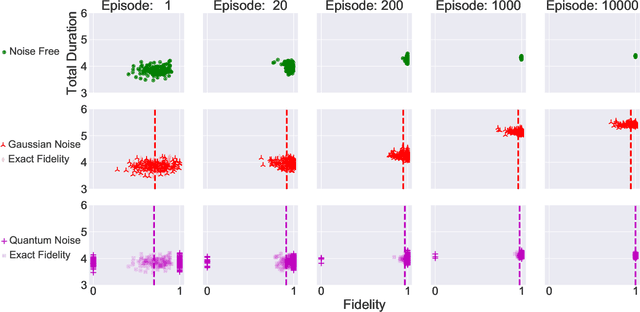
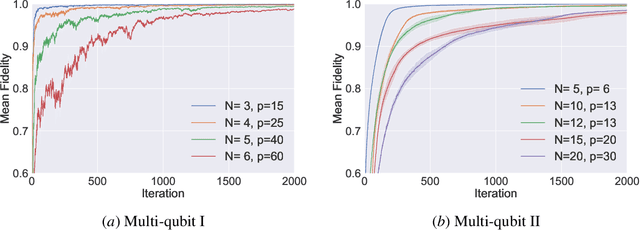
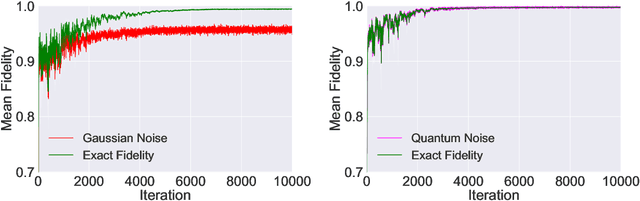
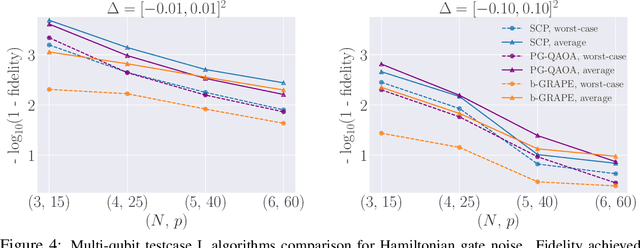
The quantum approximate optimization algorithm (QAOA), as a hybrid quantum/classical algorithm, has received much interest recently. QAOA can also be viewed as a variational ansatz for quantum control. However, its direct application to emergent quantum technology encounters additional physical constraints: (i) the states of the quantum system are not observable; (ii) obtaining the derivatives of the objective function can be computationally expensive or even inaccessible in experiments, and (iii) the values of the objective function may be sensitive to various sources of uncertainty, as is the case for noisy intermediate-scale quantum (NISQ) devices. Taking such constraints into account, we show that policy-gradient-based reinforcement learning (RL) algorithms are well suited for optimizing the variational parameters of QAOA in a noise-robust fashion, opening up the way for developing RL techniques for continuous quantum control. This is advantageous to help mitigate and monitor the potentially unknown sources of errors in modern quantum simulators. We analyze the performance of the algorithm for quantum state transfer problems in single- and multi-qubit systems, subject to various sources of noise such as error terms in the Hamiltonian, or quantum uncertainty in the measurement process. We show that, in noisy setups, it is capable of outperforming state-of-the-art existing optimization algorithms.
IMPACT: Importance Weighted Asynchronous Architectures with Clipped Target Networks
Jan 23, 2020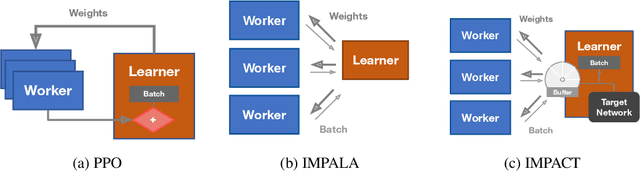
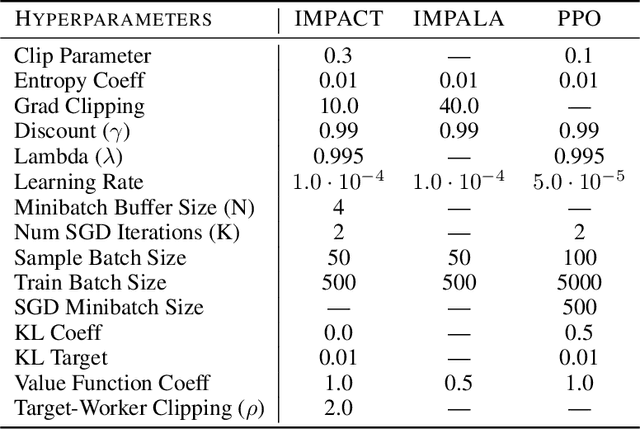
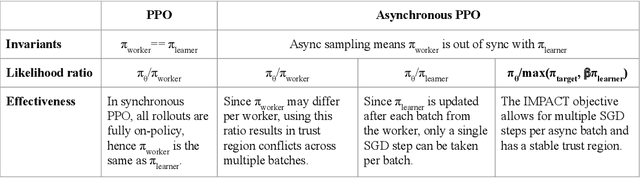
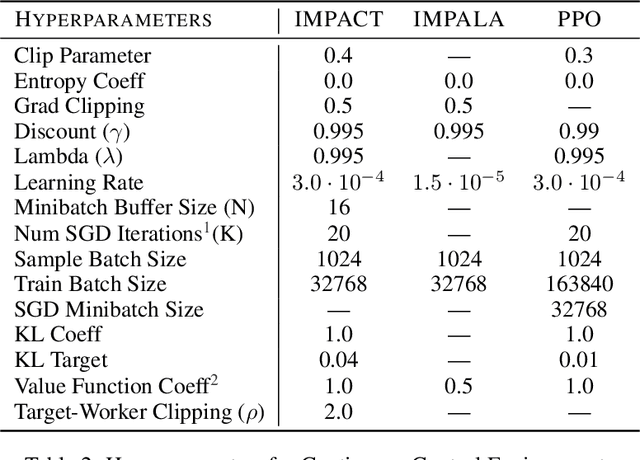
The practical usage of reinforcement learning agents is often bottlenecked by the duration of training time. To accelerate training, practitioners often turn to distributed reinforcement learning architectures to parallelize and accelerate the training process. However, modern methods for scalable reinforcement learning (RL) often tradeoff between the throughput of samples that an RL agent can learn from (sample throughput) and the quality of learning from each sample (sample efficiency). In these scalable RL architectures, as one increases sample throughput (i.e. increasing parallelization in IMPALA), sample efficiency drops significantly. To address this, we propose a new distributed reinforcement learning algorithm, IMPACT. IMPACT extends IMPALA with three changes: a target network for stabilizing the surrogate objective, a circular buffer, and truncated importance sampling. In discrete action-space environments, we show that IMPACT attains higher reward and, simultaneously, achieves up to 30% decrease in training wall-time than that of IMPALA. For continuous control environments, IMPACT trains faster than existing scalable agents while preserving the sample efficiency of synchronous PPO.