 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicy Gradient based Quantum Approximate Optimization Algorithm
Paper and Code
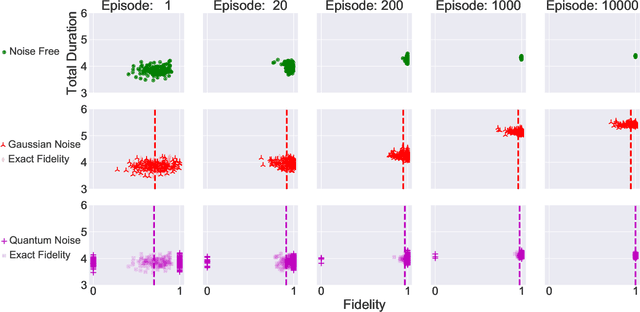
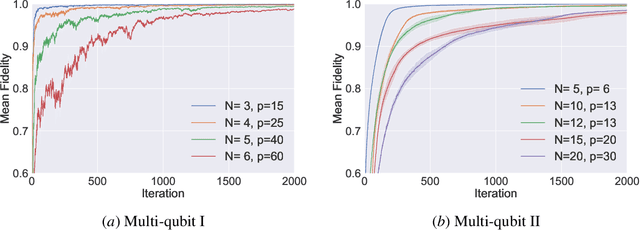
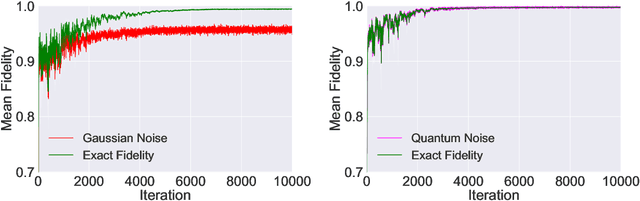
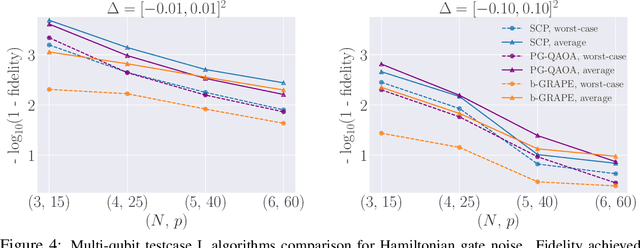
The quantum approximate optimization algorithm (QAOA), as a hybrid quantum/classical algorithm, has received much interest recently. QAOA can also be viewed as a variational ansatz for quantum control. However, its direct application to emergent quantum technology encounters additional physical constraints: (i) the states of the quantum system are not observable; (ii) obtaining the derivatives of the objective function can be computationally expensive or even inaccessible in experiments, and (iii) the values of the objective function may be sensitive to various sources of uncertainty, as is the case for noisy intermediate-scale quantum (NISQ) devices. Taking such constraints into account, we show that policy-gradient-based reinforcement learning (RL) algorithms are well suited for optimizing the variational parameters of QAOA in a noise-robust fashion, opening up the way for developing RL techniques for continuous quantum control. This is advantageous to help mitigate and monitor the potentially unknown sources of errors in modern quantum simulators. We analyze the performance of the algorithm for quantum state transfer problems in single- and multi-qubit systems, subject to various sources of noise such as error terms in the Hamiltonian, or quantum uncertainty in the measurement process. We show that, in noisy setups, it is capable of outperforming state-of-the-art existing optimization algorithms.