 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeek Models Shall Inherit the Earth
Jul 10, 2025The past decade has seen incredible scaling of AI systems by a few companies, leading to inequality in AI model performance. This paper argues that, contrary to prevailing intuition, the diminishing returns to compute scaling will lead to a convergence of AI model capabilities. In other words, meek models (those with limited computation budget) shall inherit the earth, approaching the performance level of the best models overall. We develop a model illustrating that under a fixed-distribution next-token objective, the marginal capability returns to raw compute shrink substantially. Given current scaling practices, we argue that these diminishing returns are strong enough that even companies that can scale their models exponentially faster than other organizations will eventually have little advantage in capabilities. As part of our argument, we give several reasons that proxies like training loss differences capture important capability measures using evidence from benchmark data and theoretical performance models. In addition, we analyze empirical data on the capability difference of AI models over time. Finally, in light of the increasing ability of meek models, we argue that AI strategy and policy require reexamination, and we outline the areas this shift will affect.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
REBUS: A Robust Evaluation Benchmark of Understanding Symbols
Jan 11, 2024We propose a new benchmark evaluating the performance of multimodal large language models on rebus puzzles. The dataset covers 333 original examples of image-based wordplay, cluing 13 categories such as movies, composers, major cities, and food. To achieve good performance on the benchmark of identifying the clued word or phrase, models must combine image recognition and string manipulation with hypothesis testing, multi-step reasoning, and an understanding of human cognition, making for a complex, multimodal evaluation of capabilities. We find that proprietary models such as GPT-4V and Gemini Pro significantly outperform all other tested models. However, even the best model has a final accuracy of just 24%, highlighting the need for substantial improvements in reasoning. Further, models rarely understand all parts of a puzzle, and are almost always incapable of retroactively explaining the correct answer. Our benchmark can therefore be used to identify major shortcomings in the knowledge and reasoning of multimodal large language models.
Noise-Robust End-to-End Quantum Control using Deep Autoregressive Policy Networks
Dec 12, 2020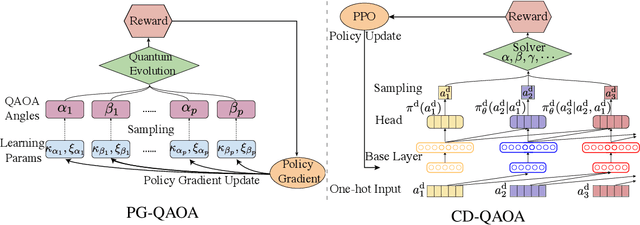
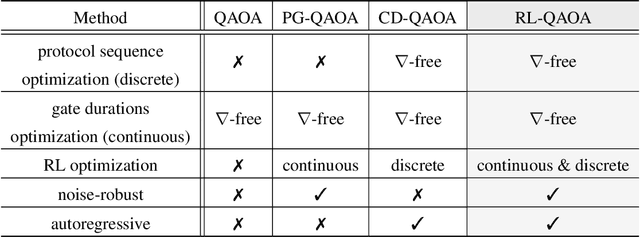
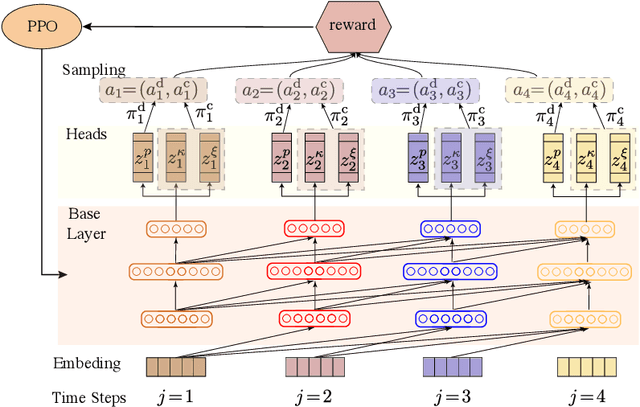

Variational quantum eigensolvers have recently received increased attention, as they enable the use of quantum computing devices to find solutions to complex problems, such as the ground energy and ground state of strongly-correlated quantum many-body systems. In many applications, it is the optimization of both continuous and discrete parameters that poses a formidable challenge. Using reinforcement learning (RL), we present a hybrid policy gradient algorithm capable of simultaneously optimizing continuous and discrete degrees of freedom in an uncertainty-resilient way. The hybrid policy is modeled by a deep autoregressive neural network to capture causality. We employ the algorithm to prepare the ground state of the nonintegrable quantum Ising model in a unitary process, parametrized by a generalized quantum approximate optimization ansatz: the RL agent solves the discrete combinatorial problem of constructing the optimal sequences of unitaries out of a predefined set and, at the same time, it optimizes the continuous durations for which these unitaries are applied. We demonstrate the noise-robust features of the agent by considering three sources of uncertainty: classical and quantum measurement noise, and errors in the control unitary durations. Our work exhibits the beneficial synergy between reinforcement learning and quantum control.