 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperSched: Dynamic Resource Reallocation for Model Development on a Deadline
Jan 08, 2020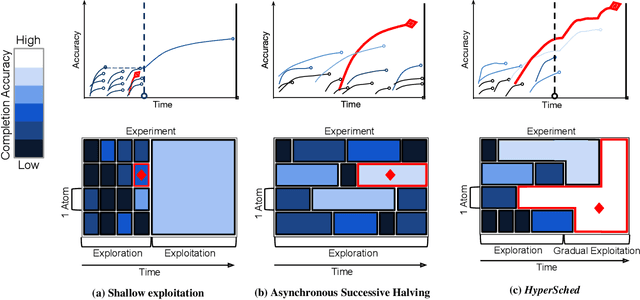
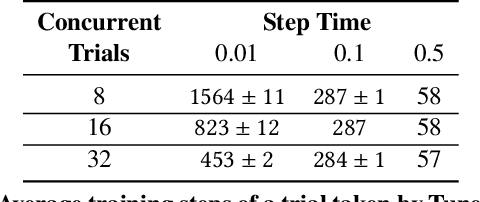
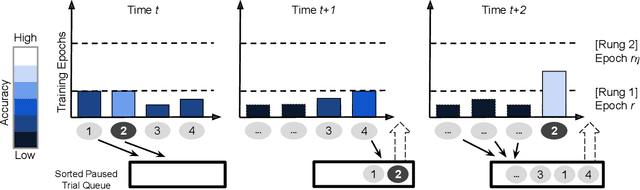

Prior research in resource scheduling for machine learning training workloads has largely focused on minimizing job completion times. Commonly, these model training workloads collectively search over a large number of parameter values that control the learning process in a hyperparameter search. It is preferable to identify and maximally provision the best-performing hyperparameter configuration (trial) to achieve the highest accuracy result as soon as possible. To optimally trade-off evaluating multiple configurations and training the most promising ones by a fixed deadline, we design and build HyperSched -- a dynamic application-level resource scheduler to track, identify, and preferentially allocate resources to the best performing trials to maximize accuracy by the deadline. HyperSched leverages three properties of a hyperparameter search workload over-looked in prior work - trial disposability, progressively identifiable rankings among different configurations, and space-time constraints - to outperform standard hyperparameter search algorithms across a variety of benchmarks.
Hierarchical Variational Imitation Learning of Control Programs
Dec 29, 2019
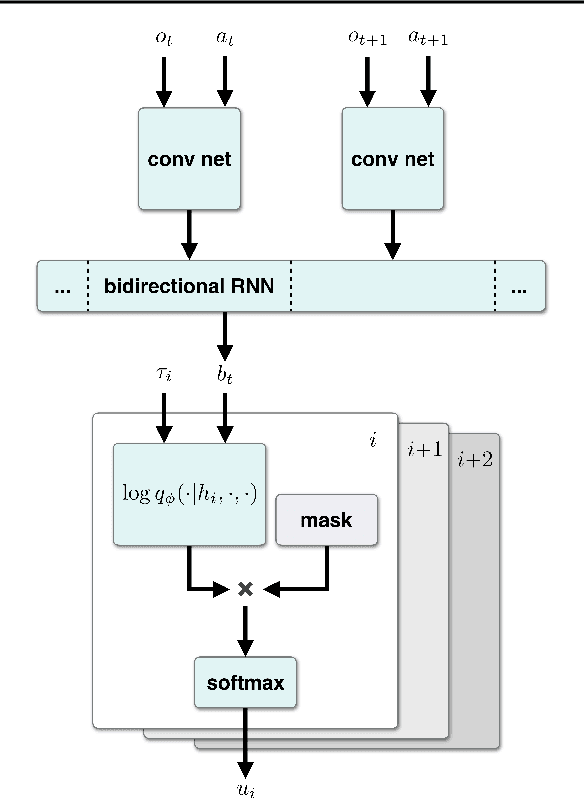
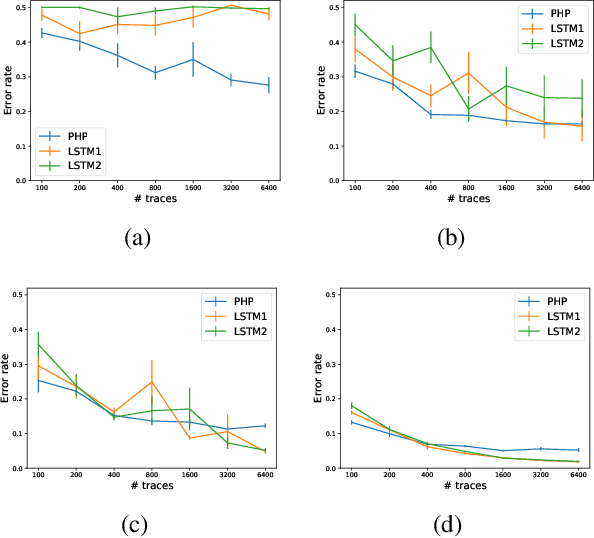
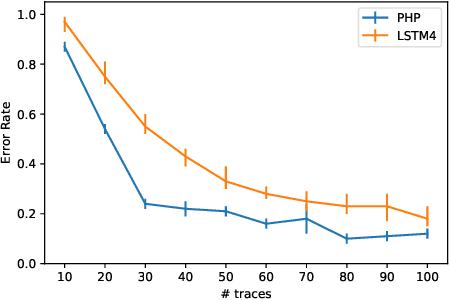
Autonomous agents can learn by imitating teacher demonstrations of the intended behavior. Hierarchical control policies are ubiquitously useful for such learning, having the potential to break down structured tasks into simpler sub-tasks, thereby improving data efficiency and generalization. In this paper, we propose a variational inference method for imitation learning of a control policy represented by parametrized hierarchical procedures (PHP), a program-like structure in which procedures can invoke sub-procedures to perform sub-tasks. Our method discovers the hierarchical structure in a dataset of observation-action traces of teacher demonstrations, by learning an approximate posterior distribution over the latent sequence of procedure calls and terminations. Samples from this learned distribution then guide the training of the hierarchical control policy. We identify and demonstrate a novel benefit of variational inference in the context of hierarchical imitation learning: in decomposing the policy into simpler procedures, inference can leverage acausal information that is unused by other methods. Training PHP with variational inference outperforms LSTM baselines in terms of data efficiency and generalization, requiring less than half as much data to achieve a 24% error rate in executing the bubble sort algorithm, and to achieve no error in executing Karel programs.