 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkyServe: Serving AI Models across Regions and Clouds with Spot Instances
Nov 03, 2024



Recent years have witnessed an explosive growth of AI models. The high cost of hosting AI services on GPUs and their demanding service requirements, make it timely and challenging to lower service costs and guarantee service quality. While spot instances have long been offered with a large discount, spot preemptions have discouraged users from using them to host model replicas when serving AI models. To address this, we introduce SkyServe, a system that efficiently serves AI models over a mixture of spot and on-demand replicas across regions and clouds. SkyServe intelligently spreads spot replicas across different failure domains (e.g., regions or clouds) to improve availability and reduce correlated preemptions, overprovisions cheap spot replicas than required as a safeguard against possible preemptions, and dynamically falls back to on-demand replicas when spot replicas become unavailable. We compare SkyServe with both research and production systems on real AI workloads: SkyServe reduces cost by up to 44% while achieving high resource availability compared to using on-demand replicas. Additionally, SkyServe improves P50, P90, and P99 latency by up to 2.6x, 3.1x, 2.7x compared to other research and production systems.
Ekya: Continuous Learning of Video Analytics Models on Edge Compute Servers
Dec 19, 2020
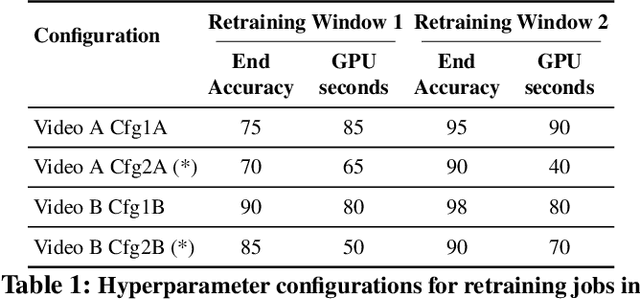
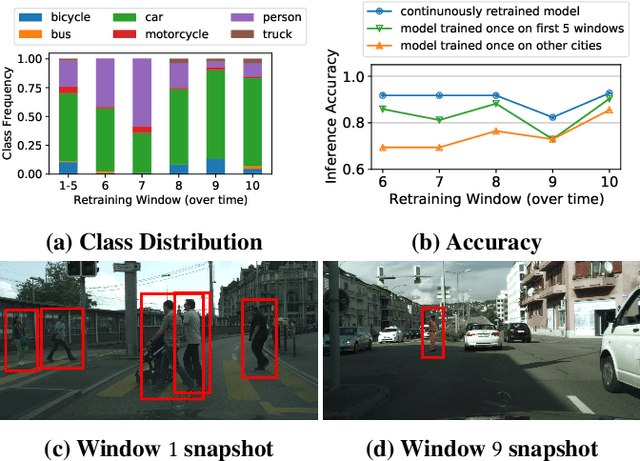

Video analytics applications use edge compute servers for the analytics of the videos (for bandwidth and privacy). Compressed models that are deployed on the edge servers for inference suffer from data drift, where the live video data diverges from the training data. Continuous learning handles data drift by periodically retraining the models on new data. Our work addresses the challenge of jointly supporting inference and retraining tasks on edge servers, which requires navigating the fundamental tradeoff between the retrained model's accuracy and the inference accuracy. Our solution Ekya balances this tradeoff across multiple models and uses a micro-profiler to identify the models that will benefit the most by retraining. Ekya's accuracy gain compared to a baseline scheduler is 29% higher, and the baseline requires 4x more GPU resources to achieve the same accuracy as Ekya.
HyperSched: Dynamic Resource Reallocation for Model Development on a Deadline
Jan 08, 2020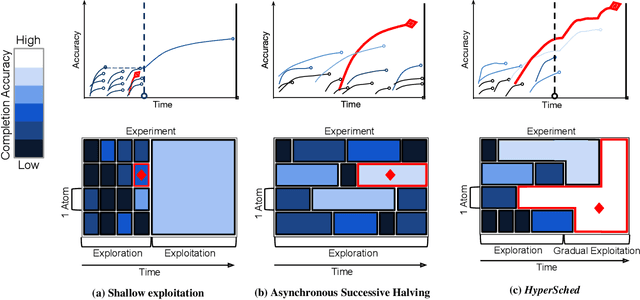
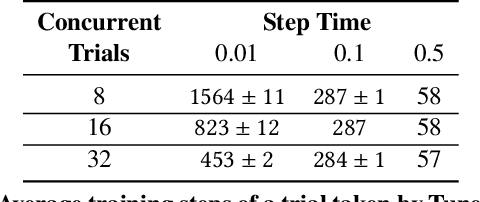
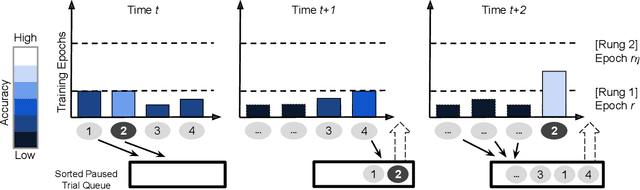

Prior research in resource scheduling for machine learning training workloads has largely focused on minimizing job completion times. Commonly, these model training workloads collectively search over a large number of parameter values that control the learning process in a hyperparameter search. It is preferable to identify and maximally provision the best-performing hyperparameter configuration (trial) to achieve the highest accuracy result as soon as possible. To optimally trade-off evaluating multiple configurations and training the most promising ones by a fixed deadline, we design and build HyperSched -- a dynamic application-level resource scheduler to track, identify, and preferentially allocate resources to the best performing trials to maximize accuracy by the deadline. HyperSched leverages three properties of a hyperparameter search workload over-looked in prior work - trial disposability, progressively identifiable rankings among different configurations, and space-time constraints - to outperform standard hyperparameter search algorithms across a variety of benchmarks.