 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding and Optimizing Packed Neural Network Training for Hyper-Parameter Tuning
Paper and Code
Feb 07, 2020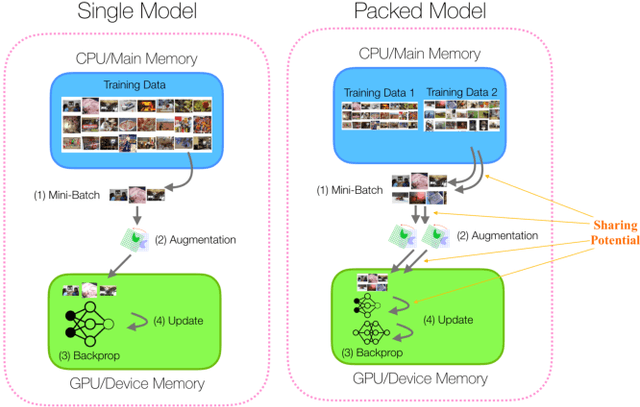
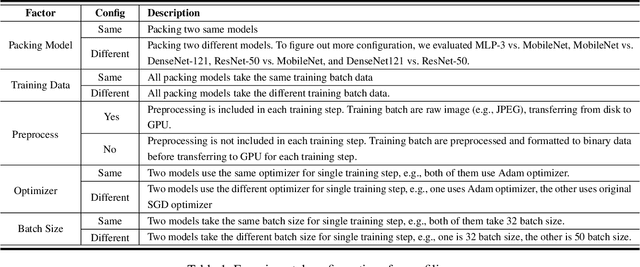
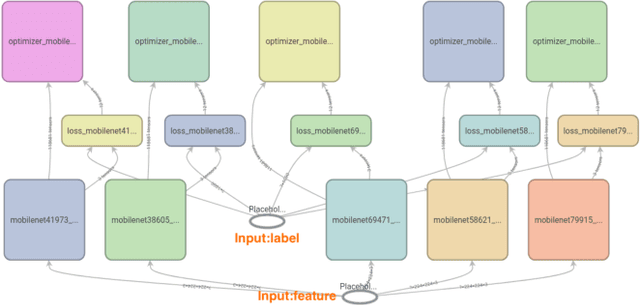
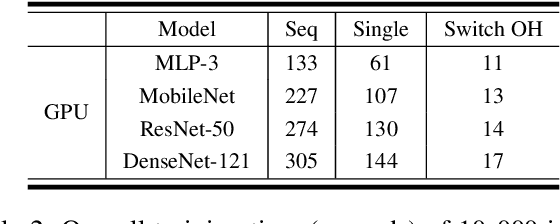
As neural networks are increasingly employed in machine learning practice, organizations will have to determine how to share limited training resources among a diverse set of model training tasks. This paper studies jointly training multiple neural network models on a single GPU. We presents an empirical study of this operation, called pack, and end-to-end experiments that suggest significant improvements for hyperparameter search systems. Our research prototype is in TensorFlow, and we evaluate performance across different models (ResNet, MobileNet, DenseNet, and MLP) and training scenarios. The results suggest: (1) packing two models can bring up to 40% performance improvement over unpacked setups for a single training step and the improvement increases when packing more models; (2) the benefit of a pack primitive largely depends on a number of factors including memory capacity, chip architecture, neural network structure, and batch size; (3) there exists a trade-off between packing and unpacking when training multiple neural network models on limited resources; (4) a pack-based Hyperband is up to 2.7x faster than the original Hyperband training method in our experiment setting, with this improvement growing as memory size increases and subsequently the density of models packed.