 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVUS: Effective and Efficient Accuracy Measures for Time-Series Anomaly Detection
Feb 18, 2025



Anomaly detection (AD) is a fundamental task for time-series analytics with important implications for the downstream performance of many applications. In contrast to other domains where AD mainly focuses on point-based anomalies (i.e., outliers in standalone observations), AD for time series is also concerned with range-based anomalies (i.e., outliers spanning multiple observations). Nevertheless, it is common to use traditional point-based information retrieval measures, such as Precision, Recall, and F-score, to assess the quality of methods by thresholding the anomaly score to mark each point as an anomaly or not. However, mapping discrete labels into continuous data introduces unavoidable shortcomings, complicating the evaluation of range-based anomalies. Notably, the choice of evaluation measure may significantly bias the experimental outcome. Despite over six decades of attention, there has never been a large-scale systematic quantitative and qualitative analysis of time-series AD evaluation measures. This paper extensively evaluates quality measures for time-series AD to assess their robustness under noise, misalignments, and different anomaly cardinality ratios. Our results indicate that measures producing quality values independently of a threshold (i.e., AUC-ROC and AUC-PR) are more suitable for time-series AD. Motivated by this observation, we first extend the AUC-based measures to account for range-based anomalies. Then, we introduce a new family of parameter-free and threshold-independent measures, Volume Under the Surface (VUS), to evaluate methods while varying parameters. We also introduce two optimized implementations for VUS that reduce significantly the execution time of the initial implementation. Our findings demonstrate that our four measures are significantly more robust in assessing the quality of time-series AD methods.
Modeling High-Dimensional Dependent Data in the Presence of Many Explanatory Variables and Weak Signals
Dec 06, 2024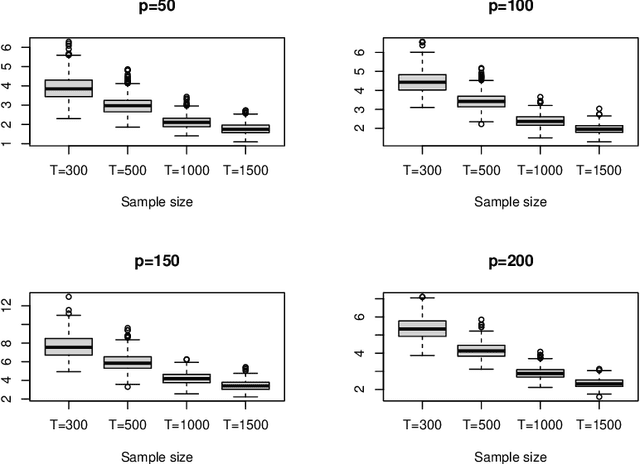
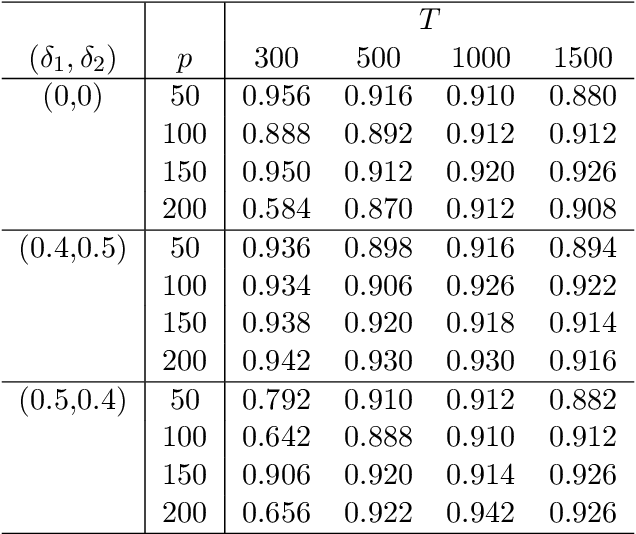
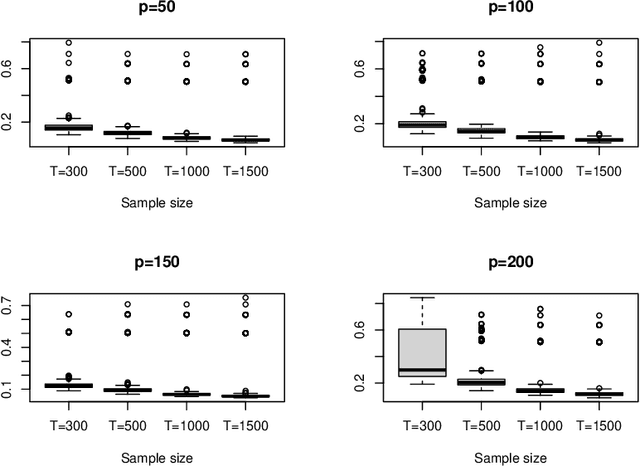
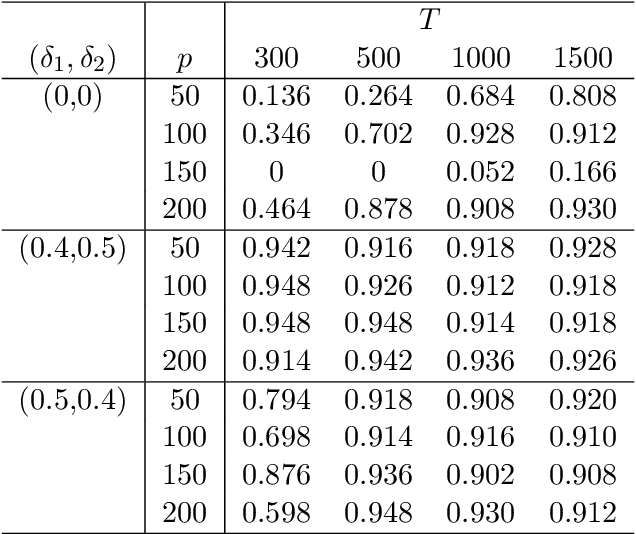
This article considers a novel and widely applicable approach to modeling high-dimensional dependent data when a large number of explanatory variables are available and the signal-to-noise ratio is low. We postulate that a $p$-dimensional response series is the sum of a linear regression with many observable explanatory variables and an error term driven by some latent common factors and an idiosyncratic noise. The common factors have dynamic dependence whereas the covariance matrix of the idiosyncratic noise can have diverging eigenvalues to handle the situation of low signal-to-noise ratio commonly encountered in applications. The regression coefficient matrix is estimated using penalized methods when the dimensions involved are high. We apply factor modeling to the regression residuals, employ a high-dimensional white noise testing procedure to determine the number of common factors, and adopt a projected Principal Component Analysis when the signal-to-noise ratio is low. We establish asymptotic properties of the proposed method, both for fixed and diverging numbers of regressors, as $p$ and the sample size $T$ approach infinity. Finally, we use simulations and empirical applications to demonstrate the efficacy of the proposed approach in finite samples.
Scalable High-Dimensional Multivariate Linear Regression for Feature-Distributed Data
Jul 07, 2023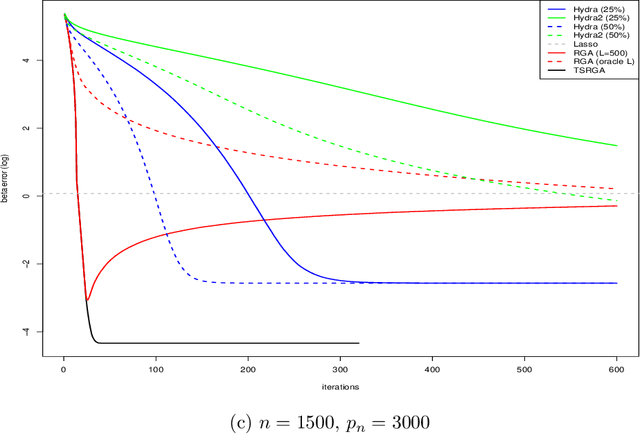



Feature-distributed data, referred to data partitioned by features and stored across multiple computing nodes, are increasingly common in applications with a large number of features. This paper proposes a two-stage relaxed greedy algorithm (TSRGA) for applying multivariate linear regression to such data. The main advantage of TSRGA is that its communication complexity does not depend on the feature dimension, making it highly scalable to very large data sets. In addition, for multivariate response variables, TSRGA can be used to yield low-rank coefficient estimates. The fast convergence of TSRGA is validated by simulation experiments. Finally, we apply the proposed TSRGA in a financial application that leverages unstructured data from the 10-K reports, demonstrating its usefulness in applications with many dense large-dimensional matrices.
Tensor Canonical Correlation Analysis
Jul 03, 2019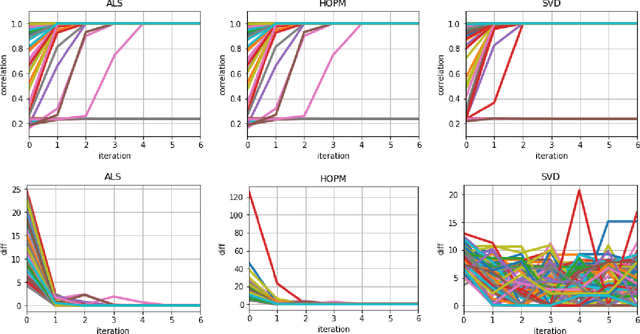

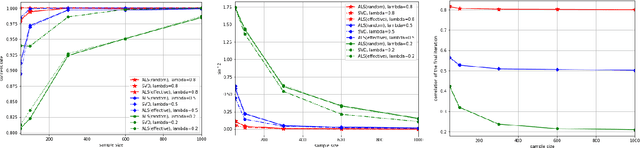

In many applications, such as classification of images or videos, it is of interest to develop a framework for tensor data instead of ad-hoc way of transforming data to vectors due to the computational and under-sampling issues. In this paper, we study canonical correlation analysis by extending the framework of two dimensional analysis (Lee and Choi, 2007) to tensor-valued data. Instead of adopting the iterative algorithm provided in Lee and Choi (2007), we propose an efficient algorithm, called the higher-order power method, which is commonly used in tensor decomposition and more efficient for large-scale setting. Moreover, we carefully examine theoretical properties of our algorithm and establish a local convergence property via the theory of Lojasiewicz's inequalities. Our results fill a missing, but crucial, part in the literature on tensor data. For practical applications, we further develop (a) an inexact updating scheme which allows us to use the state-of-the-art stochastic gradient descent algorithm, (b) an effective initialization scheme which alleviates the problem of local optimum in non-convex optimization, and (c) an extension for extracting several canonical components. Empirical analyses on challenging data including gene expression, air pollution indexes in Taiwan, and electricity demand in Australia, show the effectiveness and efficiency of the proposed methodology.