 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVUS: Effective and Efficient Accuracy Measures for Time-Series Anomaly Detection
Feb 18, 2025



Anomaly detection (AD) is a fundamental task for time-series analytics with important implications for the downstream performance of many applications. In contrast to other domains where AD mainly focuses on point-based anomalies (i.e., outliers in standalone observations), AD for time series is also concerned with range-based anomalies (i.e., outliers spanning multiple observations). Nevertheless, it is common to use traditional point-based information retrieval measures, such as Precision, Recall, and F-score, to assess the quality of methods by thresholding the anomaly score to mark each point as an anomaly or not. However, mapping discrete labels into continuous data introduces unavoidable shortcomings, complicating the evaluation of range-based anomalies. Notably, the choice of evaluation measure may significantly bias the experimental outcome. Despite over six decades of attention, there has never been a large-scale systematic quantitative and qualitative analysis of time-series AD evaluation measures. This paper extensively evaluates quality measures for time-series AD to assess their robustness under noise, misalignments, and different anomaly cardinality ratios. Our results indicate that measures producing quality values independently of a threshold (i.e., AUC-ROC and AUC-PR) are more suitable for time-series AD. Motivated by this observation, we first extend the AUC-based measures to account for range-based anomalies. Then, we introduce a new family of parameter-free and threshold-independent measures, Volume Under the Surface (VUS), to evaluate methods while varying parameters. We also introduce two optimized implementations for VUS that reduce significantly the execution time of the initial implementation. Our findings demonstrate that our four measures are significantly more robust in assessing the quality of time-series AD methods.
Dive into Time-Series Anomaly Detection: A Decade Review
Dec 29, 2024Recent advances in data collection technology, accompanied by the ever-rising volume and velocity of streaming data, underscore the vital need for time series analytics. In this regard, time-series anomaly detection has been an important activity, entailing various applications in fields such as cyber security, financial markets, law enforcement, and health care. While traditional literature on anomaly detection is centered on statistical measures, the increasing number of machine learning algorithms in recent years call for a structured, general characterization of the research methods for time-series anomaly detection. This survey groups and summarizes anomaly detection existing solutions under a process-centric taxonomy in the time series context. In addition to giving an original categorization of anomaly detection methods, we also perform a meta-analysis of the literature and outline general trends in time-series anomaly detection research.
Hierarchical Decomposition of Prompt-Based Continual Learning: Rethinking Obscured Sub-optimality
Oct 11, 2023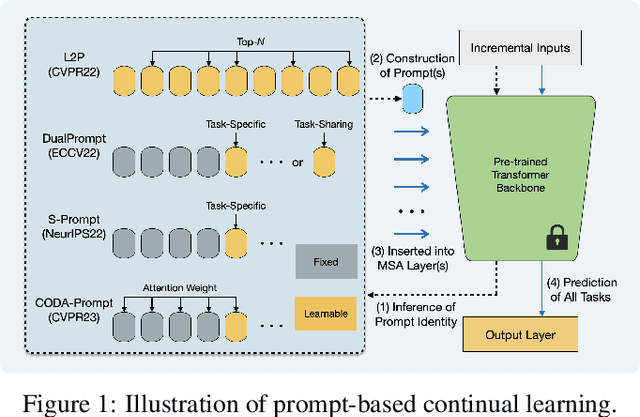
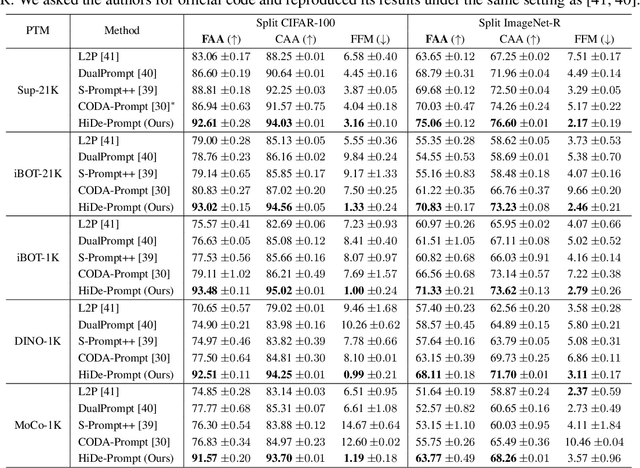
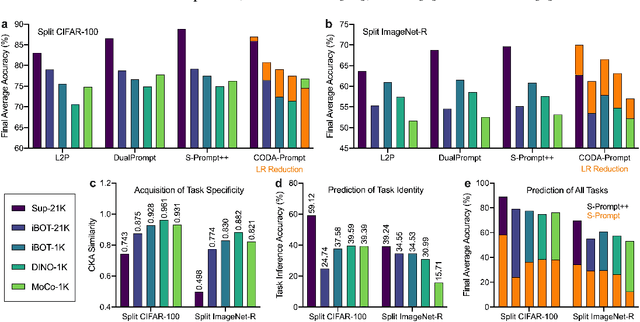
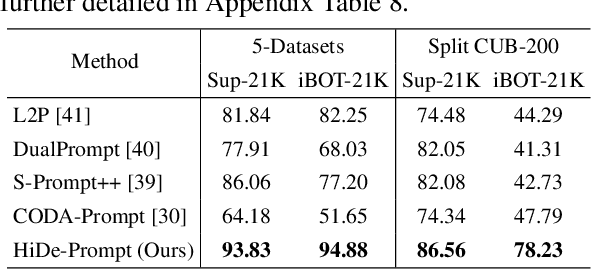
Prompt-based continual learning is an emerging direction in leveraging pre-trained knowledge for downstream continual learning, and has almost reached the performance pinnacle under supervised pre-training. However, our empirical research reveals that the current strategies fall short of their full potential under the more realistic self-supervised pre-training, which is essential for handling vast quantities of unlabeled data in practice. This is largely due to the difficulty of task-specific knowledge being incorporated into instructed representations via prompt parameters and predicted by uninstructed representations at test time. To overcome the exposed sub-optimality, we conduct a theoretical analysis of the continual learning objective in the context of pre-training, and decompose it into hierarchical components: within-task prediction, task-identity inference, and task-adaptive prediction. Following these empirical and theoretical insights, we propose Hierarchical Decomposition (HiDe-)Prompt, an innovative approach that explicitly optimizes the hierarchical components with an ensemble of task-specific prompts and statistics of both uninstructed and instructed representations, further with the coordination of a contrastive regularization strategy. Our extensive experiments demonstrate the superior performance of HiDe-Prompt and its robustness to pre-training paradigms in continual learning (e.g., up to 15.01% and 9.61% lead on Split CIFAR-100 and Split ImageNet-R, respectively). Our code is available at \url{https://github.com/thu-ml/HiDe-Prompt}.