 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient machine unlearning with minimax optimality
Apr 07, 2026There is a growing demand for efficient data removal to comply with regulations like the GDPR and to mitigate the influence of biased or corrupted data. This has motivated the field of machine unlearning, which aims to eliminate the influence of specific data subsets without the cost of full retraining. In this work, we propose a statistical framework for machine unlearning with generic loss functions and establish theoretical guarantees. For squared loss, especially, we develop Unlearning Least Squares (ULS) and establish its minimax optimality for estimating the model parameter of remaining data when only the pre-trained estimator, forget samples, and a small subsample of the remaining data are available. Our results reveal that the estimation error decomposes into an oracle term and an unlearning cost determined by the forget proportion and the forget model bias. We further establish asymptotically valid inference procedures without requiring full retraining. Numerical experiments and real-data applications demonstrate that the proposed method achieves performance close to retraining while requiring substantially less data access.
Dual Data Alignment Makes AI-Generated Image Detector Easier Generalizable
May 20, 2025Existing detectors are often trained on biased datasets, leading to the possibility of overfitting on non-causal image attributes that are spuriously correlated with real/synthetic labels. While these biased features enhance performance on the training data, they result in substantial performance degradation when applied to unbiased datasets. One common solution is to perform dataset alignment through generative reconstruction, matching the semantic content between real and synthetic images. However, we revisit this approach and show that pixel-level alignment alone is insufficient. The reconstructed images still suffer from frequency-level misalignment, which can perpetuate spurious correlations. To illustrate, we observe that reconstruction models tend to restore the high-frequency details lost in real images (possibly due to JPEG compression), inadvertently creating a frequency-level misalignment, where synthetic images appear to have richer high-frequency content than real ones. This misalignment leads to models associating high-frequency features with synthetic labels, further reinforcing biased cues. To resolve this, we propose Dual Data Alignment (DDA), which aligns both the pixel and frequency domains. Moreover, we introduce two new test sets: DDA-COCO, containing DDA-aligned synthetic images for testing detector performance on the most aligned dataset, and EvalGEN, featuring the latest generative models for assessing detectors under new generative architectures such as visual auto-regressive generators. Finally, our extensive evaluations demonstrate that a detector trained exclusively on DDA-aligned MSCOCO could improve across 8 diverse benchmarks by a non-trivial margin, showing a +7.2% on in-the-wild benchmarks, highlighting the improved generalizability of unbiased detectors.
HiDe-PET: Continual Learning via Hierarchical Decomposition of Parameter-Efficient Tuning
Jul 07, 2024The deployment of pre-trained models (PTMs) has greatly advanced the field of continual learning (CL), enabling positive knowledge transfer and resilience to catastrophic forgetting. To sustain these advantages for sequentially arriving tasks, a promising direction involves keeping the pre-trained backbone frozen while employing parameter-efficient tuning (PET) techniques to instruct representation learning. Despite the popularity of Prompt-based PET for CL, its empirical design often leads to sub-optimal performance in our evaluation of different PTMs and target tasks. To this end, we propose a unified framework for CL with PTMs and PET that provides both theoretical and empirical advancements. We first perform an in-depth theoretical analysis of the CL objective in a pre-training context, decomposing it into hierarchical components namely within-task prediction, task-identity inference and task-adaptive prediction. We then present Hierarchical Decomposition PET (HiDe-PET), an innovative approach that explicitly optimizes the decomposed objective through incorporating task-specific and task-shared knowledge via mainstream PET techniques along with efficient recovery of pre-trained representations. Leveraging this framework, we delve into the distinct impacts of implementation strategy, PET technique and PET architecture, as well as adaptive knowledge accumulation amidst pronounced distribution changes. Finally, across various CL scenarios, our approach demonstrates remarkably superior performance over a broad spectrum of recent strong baselines.
Towards a General Framework for Continual Learning with Pre-training
Oct 21, 2023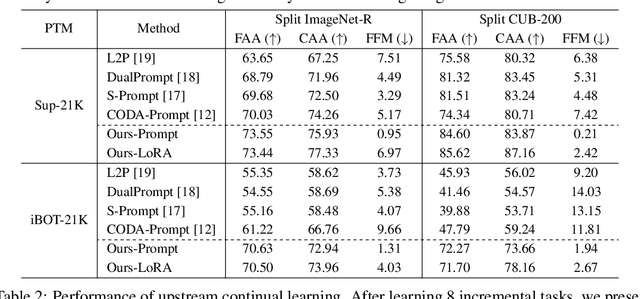
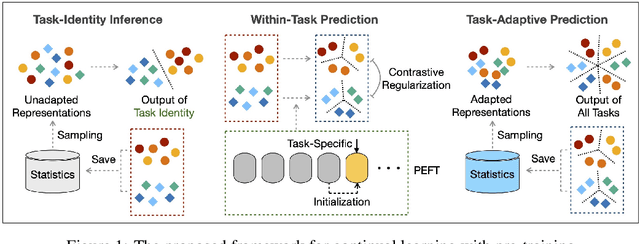
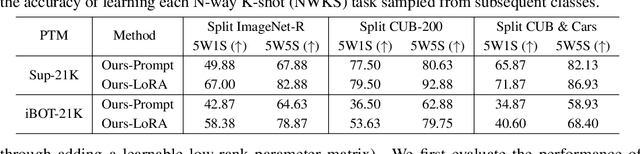
In this work, we present a general framework for continual learning of sequentially arrived tasks with the use of pre-training, which has emerged as a promising direction for artificial intelligence systems to accommodate real-world dynamics. From a theoretical perspective, we decompose its objective into three hierarchical components, including within-task prediction, task-identity inference, and task-adaptive prediction. Then we propose an innovative approach to explicitly optimize these components with parameter-efficient fine-tuning (PEFT) techniques and representation statistics. We empirically demonstrate the superiority and generality of our approach in downstream continual learning, and further explore the applicability of PEFT techniques in upstream continual learning. We also discuss the biological basis of the proposed framework with recent advances in neuroscience.
Hierarchical Decomposition of Prompt-Based Continual Learning: Rethinking Obscured Sub-optimality
Oct 11, 2023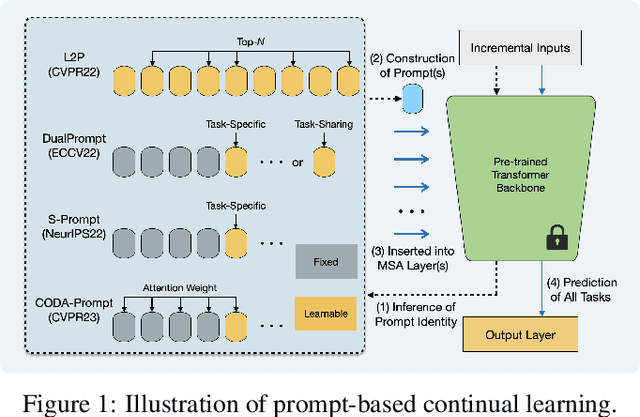
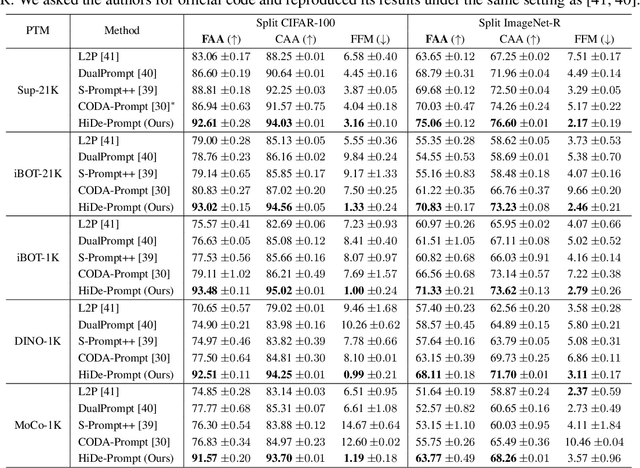
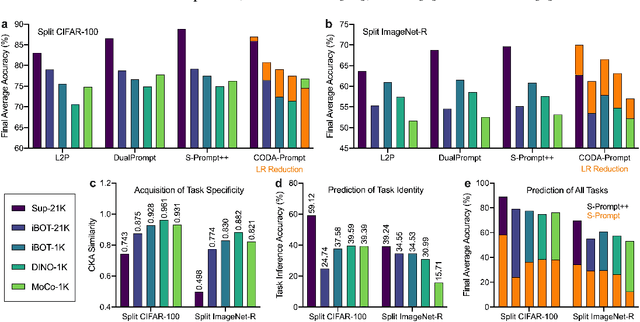
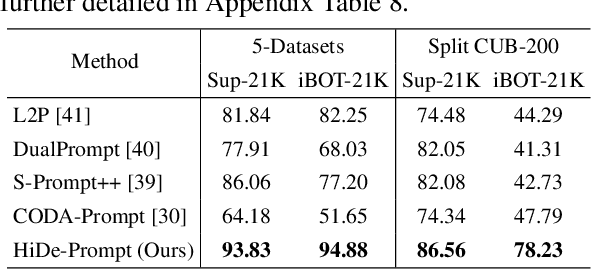
Prompt-based continual learning is an emerging direction in leveraging pre-trained knowledge for downstream continual learning, and has almost reached the performance pinnacle under supervised pre-training. However, our empirical research reveals that the current strategies fall short of their full potential under the more realistic self-supervised pre-training, which is essential for handling vast quantities of unlabeled data in practice. This is largely due to the difficulty of task-specific knowledge being incorporated into instructed representations via prompt parameters and predicted by uninstructed representations at test time. To overcome the exposed sub-optimality, we conduct a theoretical analysis of the continual learning objective in the context of pre-training, and decompose it into hierarchical components: within-task prediction, task-identity inference, and task-adaptive prediction. Following these empirical and theoretical insights, we propose Hierarchical Decomposition (HiDe-)Prompt, an innovative approach that explicitly optimizes the hierarchical components with an ensemble of task-specific prompts and statistics of both uninstructed and instructed representations, further with the coordination of a contrastive regularization strategy. Our extensive experiments demonstrate the superior performance of HiDe-Prompt and its robustness to pre-training paradigms in continual learning (e.g., up to 15.01% and 9.61% lead on Split CIFAR-100 and Split ImageNet-R, respectively). Our code is available at \url{https://github.com/thu-ml/HiDe-Prompt}.
Knowledge-Enhanced Hierarchical Information Correlation Learning for Multi-Modal Rumor Detection
Jun 28, 2023



The explosive growth of rumors with text and images on social media platforms has drawn great attention. Existing studies have made significant contributions to cross-modal information interaction and fusion, but they fail to fully explore hierarchical and complex semantic correlation across different modality content, severely limiting their performance on detecting multi-modal rumor. In this work, we propose a novel knowledge-enhanced hierarchical information correlation learning approach (KhiCL) for multi-modal rumor detection by jointly modeling the basic semantic correlation and high-order knowledge-enhanced entity correlation. Specifically, KhiCL exploits cross-modal joint dictionary to transfer the heterogeneous unimodality features into the common feature space and captures the basic cross-modal semantic consistency and inconsistency by a cross-modal fusion layer. Moreover, considering the description of multi-modal content is narrated around entities, KhiCL extracts visual and textual entities from images and text, and designs a knowledge relevance reasoning strategy to find the shortest semantic relevant path between each pair of entities in external knowledge graph, and absorbs all complementary contextual knowledge of other connected entities in this path for learning knowledge-enhanced entity representations. Furthermore, KhiCL utilizes a signed attention mechanism to model the knowledge-enhanced entity consistency and inconsistency of intra-modality and inter-modality entity pairs by measuring their corresponding semantic relevant distance. Extensive experiments have demonstrated the effectiveness of the proposed method.
SegFix: Model-Agnostic Boundary Refinement for Segmentation
Jul 09, 2020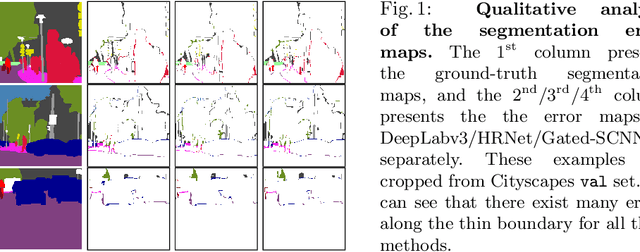
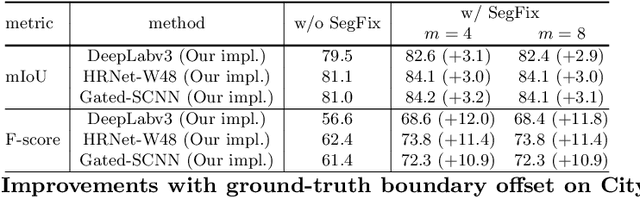
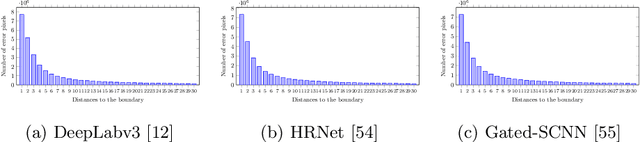
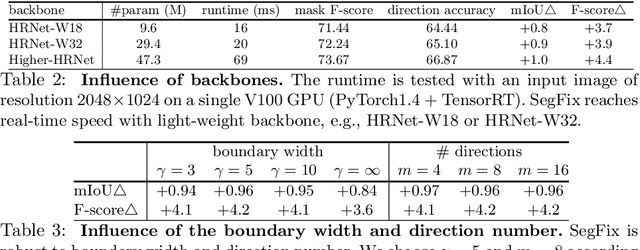
We present a model-agnostic post-processing scheme to improve the boundary quality for the segmentation result that is generated by any existing segmentation model. Motivated by the empirical observation that the label predictions of interior pixels are more reliable, we propose to replace the originally unreliable predictions of boundary pixels by the predictions of interior pixels. Our approach processes only the input image through two steps: (i) localize the boundary pixels and (ii) identify the corresponding interior pixel for each boundary pixel. We build the correspondence by learning a direction away from the boundary pixel to an interior pixel. Our method requires no prior information of the segmentation models and achieves nearly real-time speed. We empirically verify that our SegFix consistently reduces the boundary errors for segmentation results generated from various state-of-the-art models on Cityscapes, ADE20K and GTA5. Code is available at: https://github.com/openseg-group/openseg.pytorch.
ABD-Net: Attentive but Diverse Person Re-Identification
Aug 09, 2019
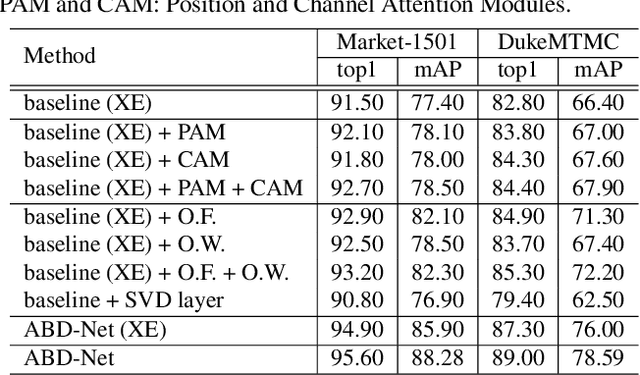
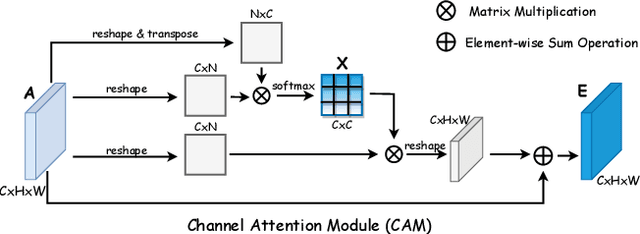
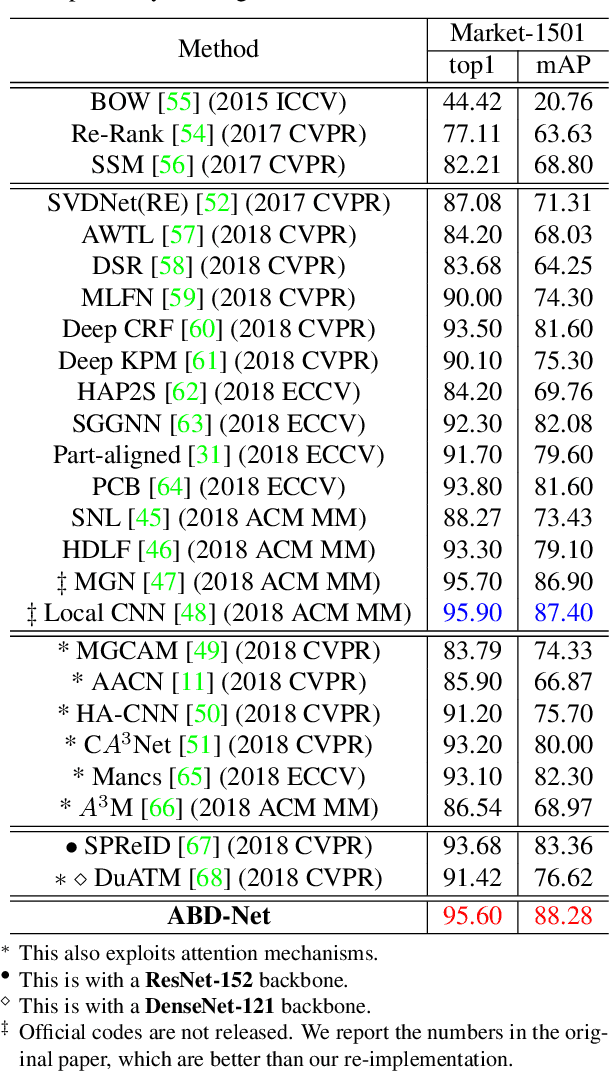
Attention mechanism has been shown to be effective for person re-identification (Re-ID). However, the learned attentive feature embeddings which are often not naturally diverse nor uncorrelated, will compromise the retrieval performance based on the Euclidean distance. We advocate that enforcing diversity could greatly complement the power of attention. To this end, we propose an Attentive but Diverse Network (ABD-Net), which seamlessly integrates attention modules and diversity regularization throughout the entire network, to learn features that are representative, robust, and more discriminative. Specifically, we introduce a pair of complementary attention modules, focusing on channel aggregation and position awareness, respectively. Furthermore, a new efficient form of orthogonality constraint is derived to enforce orthogonality on both hidden activations and weights. Through careful ablation studies, we verify that the proposed attentive and diverse terms each contributes to the performance gains of ABD-Net. On three popular benchmarks, ABD-Net consistently outperforms existing state-of-the-art methods.