 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Learning for Crowd-Sourced Databases
Paper and Code
Dec 20, 2014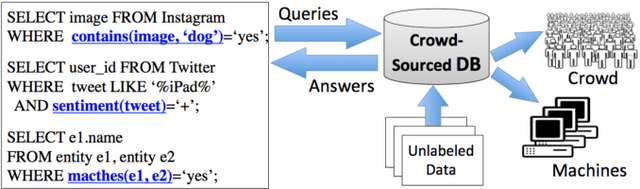

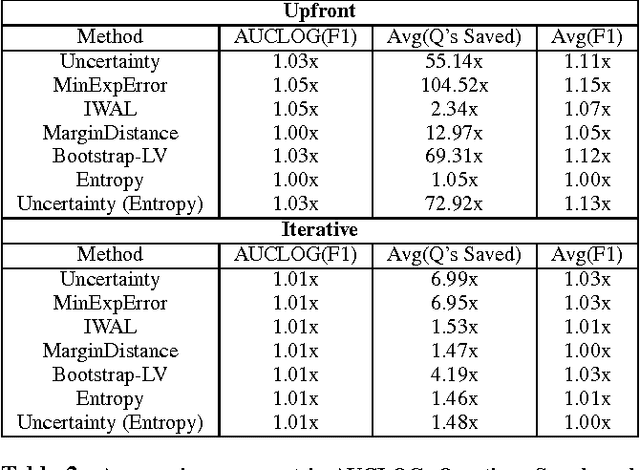
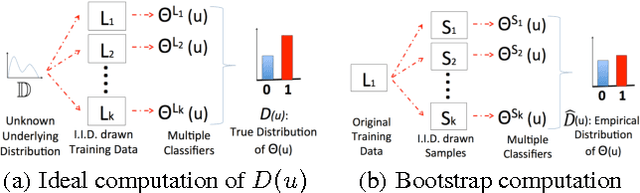
Crowd-sourcing has become a popular means of acquiring labeled data for a wide variety of tasks where humans are more accurate than computers, e.g., labeling images, matching objects, or analyzing sentiment. However, relying solely on the crowd is often impractical even for data sets with thousands of items, due to time and cost constraints of acquiring human input (which cost pennies and minutes per label). In this paper, we propose algorithms for integrating machine learning into crowd-sourced databases, with the goal of allowing crowd-sourcing applications to scale, i.e., to handle larger datasets at lower costs. The key observation is that, in many of the above tasks, humans and machine learning algorithms can be complementary, as humans are often more accurate but slow and expensive, while algorithms are usually less accurate, but faster and cheaper. Based on this observation, we present two new active learning algorithms to combine humans and algorithms together in a crowd-sourced database. Our algorithms are based on the theory of non-parametric bootstrap, which makes our results applicable to a broad class of machine learning models. Our results, on three real-life datasets collected with Amazon's Mechanical Turk, and on 15 well-known UCI data sets, show that our methods on average ask humans to label one to two orders of magnitude fewer items to achieve the same accuracy as a baseline that labels random images, and two to eight times fewer questions than previous active learning schemes.