 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGating Dropout: Communication-efficient Regularization for Sparsely Activated Transformers
May 28, 2022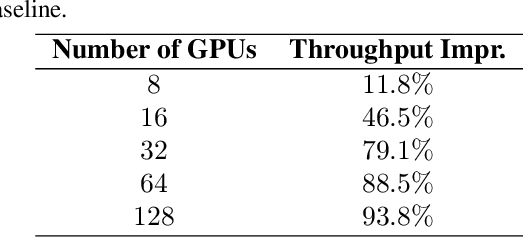
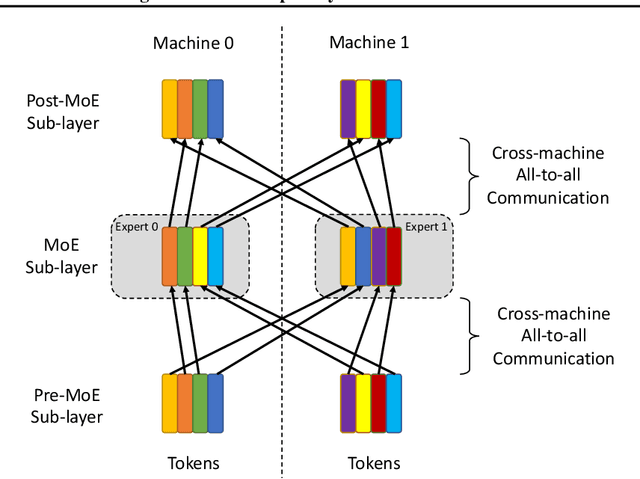

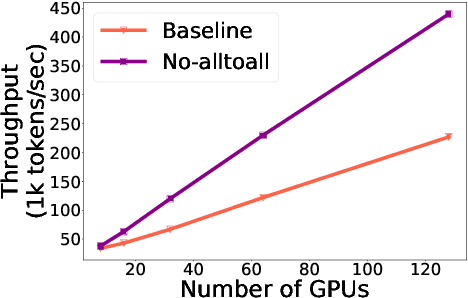
Sparsely activated transformers, such as Mixture of Experts (MoE), have received great interest due to their outrageous scaling capability which enables dramatical increases in model size without significant increases in computational cost. To achieve this, MoE models replace the feedforward sub-layer with Mixture-of-Experts sub-layer in transformers and use a gating network to route each token to its assigned experts. Since the common practice for efficient training of such models requires distributing experts and tokens across different machines, this routing strategy often incurs huge cross-machine communication cost because tokens and their assigned experts likely reside in different machines. In this paper, we propose \emph{Gating Dropout}, which allows tokens to ignore the gating network and stay at their local machines, thus reducing the cross-machine communication. Similar to traditional dropout, we also show that Gating Dropout has a regularization effect during training, resulting in improved generalization performance. We validate the effectiveness of Gating Dropout on multilingual machine translation tasks. Our results demonstrate that Gating Dropout improves a state-of-the-art MoE model with faster wall-clock time convergence rates and better BLEU scores for a variety of model sizes and datasets.
Transformer with Memory Replay
May 19, 2022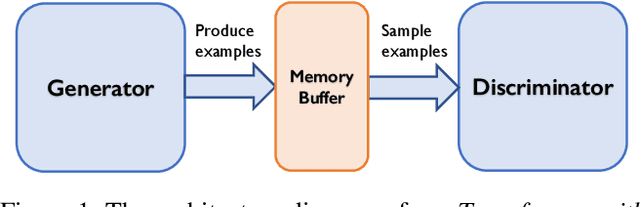

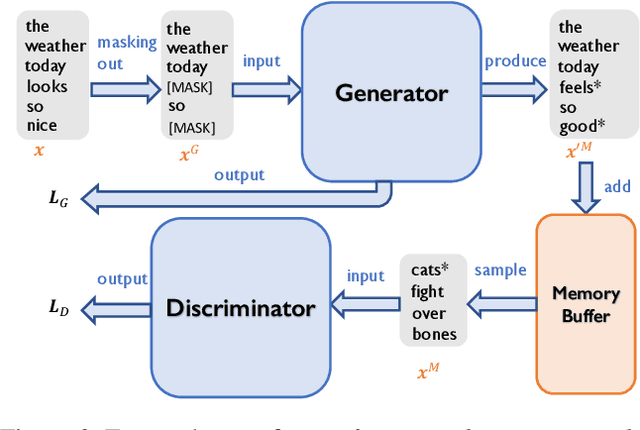
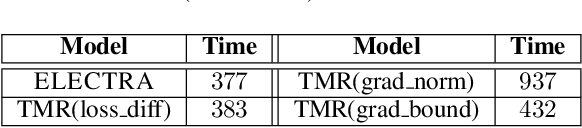
Transformers achieve state-of-the-art performance for natural language processing tasks by pre-training on large-scale text corpora. They are extremely compute-intensive and have very high sample complexity. Memory replay is a mechanism that remembers and reuses past examples by saving to and replaying from a memory buffer. It has been successfully used in reinforcement learning and GANs due to better sample efficiency. In this paper, we propose \emph{Transformer with Memory Replay} (TMR), which integrates memory replay with transformer, making transformer more sample-efficient. Experiments on GLUE and SQuAD benchmark datasets show that Transformer with Memory Replay achieves at least $1\%$ point increase compared to the baseline transformer model when pretrained with the same number of examples. Further, by adopting a careful design that reduces the wall-clock time overhead of memory replay, we also empirically achieve a better runtime efficiency.
Adam with Bandit Sampling for Deep Learning
Oct 24, 2020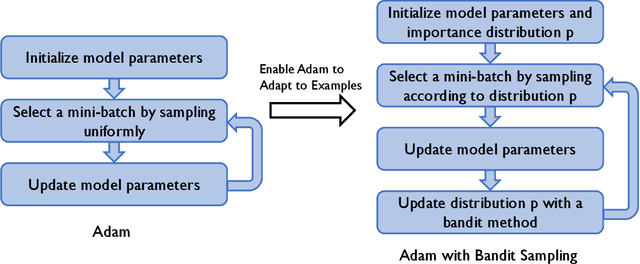

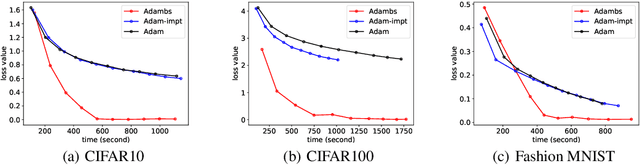
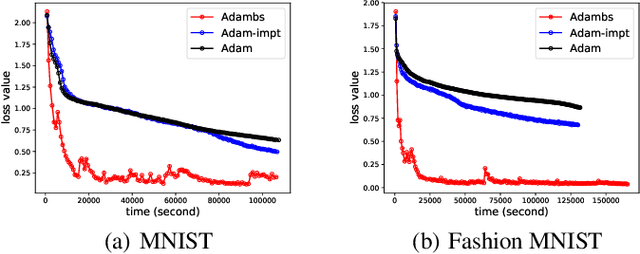
Adam is a widely used optimization method for training deep learning models. It computes individual adaptive learning rates for different parameters. In this paper, we propose a generalization of Adam, called Adambs, that allows us to also adapt to different training examples based on their importance in the model's convergence. To achieve this, we maintain a distribution over all examples, selecting a mini-batch in each iteration by sampling according to this distribution, which we update using a multi-armed bandit algorithm. This ensures that examples that are more beneficial to the model training are sampled with higher probabilities. We theoretically show that Adambs improves the convergence rate of Adam---$O(\sqrt{\frac{\log n}{T} })$ instead of $O(\sqrt{\frac{n}{T}})$ in some cases. Experiments on various models and datasets demonstrate Adambs's fast convergence in practice.
BlinkML: Efficient Maximum Likelihood Estimation with Probabilistic Guarantees
Dec 26, 2018
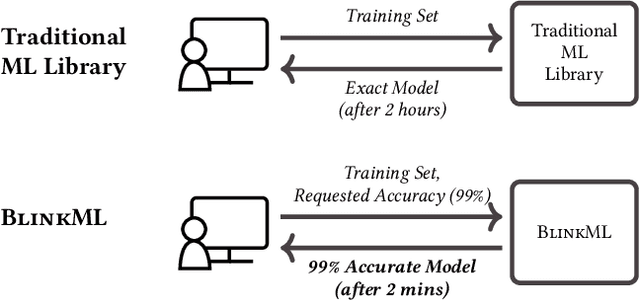
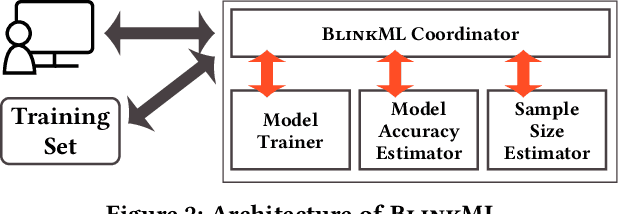
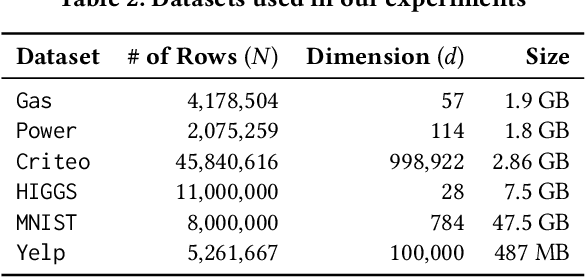
The rising volume of datasets has made training machine learning (ML) models a major computational cost in the enterprise. Given the iterative nature of model and parameter tuning, many analysts use a small sample of their entire data during their initial stage of analysis to make quick decisions (e.g., what features or hyperparameters to use) and use the entire dataset only in later stages (i.e., when they have converged to a specific model). This sampling, however, is performed in an ad-hoc fashion. Most practitioners cannot precisely capture the effect of sampling on the quality of their model, and eventually on their decision-making process during the tuning phase. Moreover, without systematic support for sampling operators, many optimizations and reuse opportunities are lost. In this paper, we introduce BlinkML, a system for fast, quality-guaranteed ML training. BlinkML allows users to make error-computation tradeoffs: instead of training a model on their full data (i.e., full model), BlinkML can quickly train an approximate model with quality guarantees using a sample. The quality guarantees ensure that, with high probability, the approximate model makes the same predictions as the full model. BlinkML currently supports any ML model that relies on maximum likelihood estimation (MLE), which includes Generalized Linear Models (e.g., linear regression, logistic regression, max entropy classifier, Poisson regression) as well as PPCA (Probabilistic Principal Component Analysis). Our experiments show that BlinkML can speed up the training of large-scale ML tasks by 6.26x-629x while guaranteeing the same predictions, with 95% probability, as the full model.
A Bandit Approach to Maximum Inner Product Search
Dec 15, 2018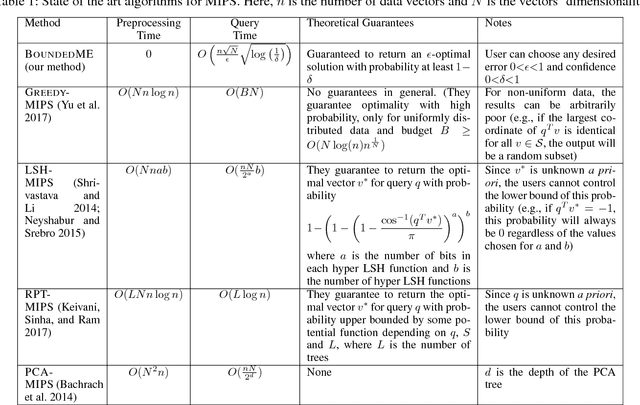
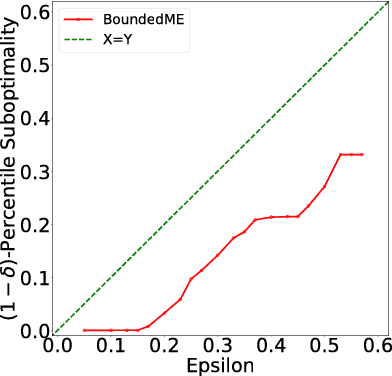
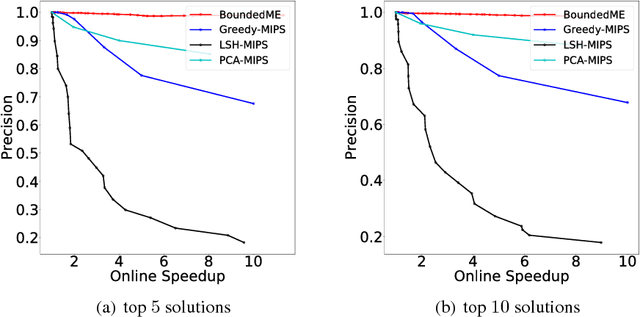
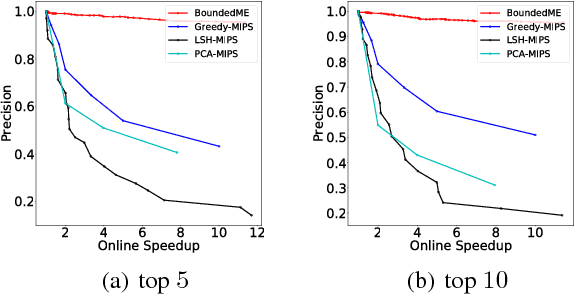
There has been substantial research on sub-linear time approximate algorithms for Maximum Inner Product Search (MIPS). To achieve fast query time, state-of-the-art techniques require significant preprocessing, which can be a burden when the number of subsequent queries is not sufficiently large to amortize the cost. Furthermore, existing methods do not have the ability to directly control the suboptimality of their approximate results with theoretical guarantees. In this paper, we propose the first approximate algorithm for MIPS that does not require any preprocessing, and allows users to control and bound the suboptimality of the results. We cast MIPS as a Best Arm Identification problem, and introduce a new bandit setting that can fully exploit the special structure of MIPS. Our approach outperforms state-of-the-art methods on both synthetic and real-world datasets.
Revisiting Projection-Free Optimization for Strongly Convex Constraint Sets
Nov 14, 2018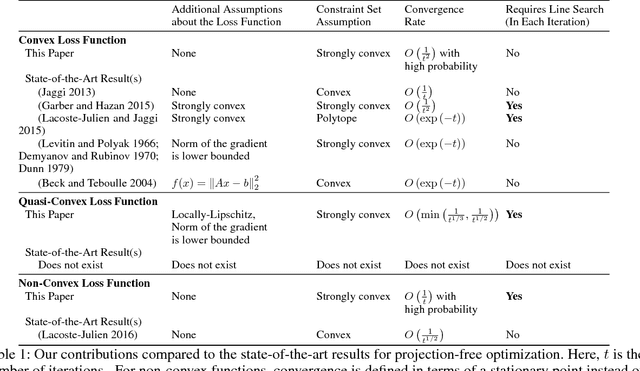
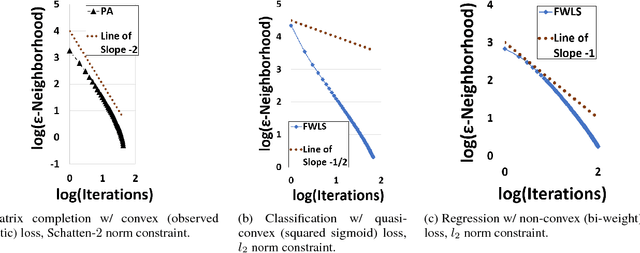

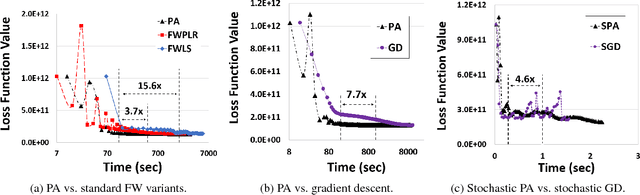
We revisit the Frank-Wolfe (FW) optimization under strongly convex constraint sets. We provide a faster convergence rate for FW without line search, showing that a previously overlooked variant of FW is indeed faster than the standard variant. With line search, we show that FW can converge to the global optimum, even for smooth functions that are not convex, but are quasi-convex and locally-Lipschitz. We also show that, for the general case of (smooth) non-convex functions, FW with line search converges with high probability to a stationary point at a rate of $O\left(\frac{1}{t}\right)$, as long as the constraint set is strongly convex -- one of the fastest convergence rates in non-convex optimization.
Database Learning: Toward a Database that Becomes Smarter Every Time
Mar 28, 2017

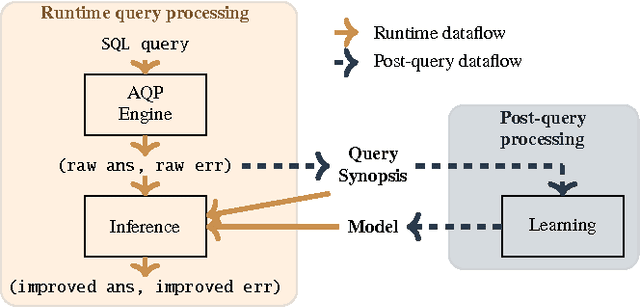
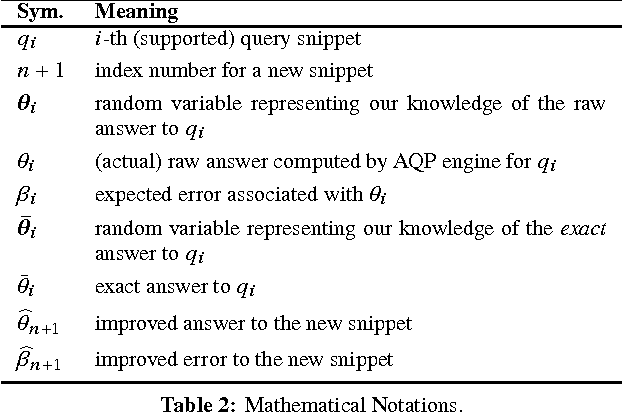
In today's databases, previous query answers rarely benefit answering future queries. For the first time, to the best of our knowledge, we change this paradigm in an approximate query processing (AQP) context. We make the following observation: the answer to each query reveals some degree of knowledge about the answer to another query because their answers stem from the same underlying distribution that has produced the entire dataset. Exploiting and refining this knowledge should allow us to answer queries more analytically, rather than by reading enormous amounts of raw data. Also, processing more queries should continuously enhance our knowledge of the underlying distribution, and hence lead to increasingly faster response times for future queries. We call this novel idea---learning from past query answers---Database Learning. We exploit the principle of maximum entropy to produce answers, which are in expectation guaranteed to be more accurate than existing sample-based approximations. Empowered by this idea, we build a query engine on top of Spark SQL, called Verdict. We conduct extensive experiments on real-world query traces from a large customer of a major database vendor. Our results demonstrate that Verdict supports 73.7% of these queries, speeding them up by up to 23.0x for the same accuracy level compared to existing AQP systems.
Active Learning for Crowd-Sourced Databases
Dec 20, 2014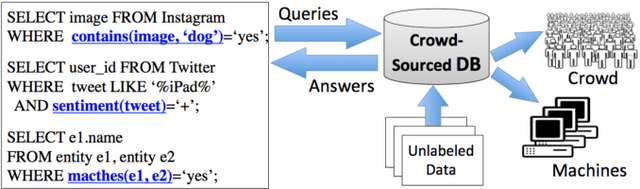

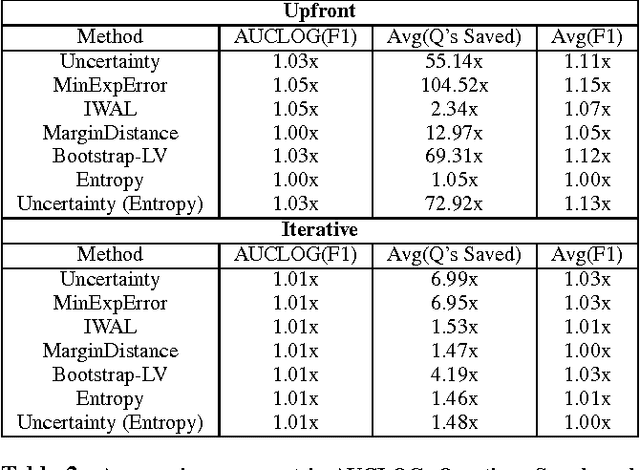
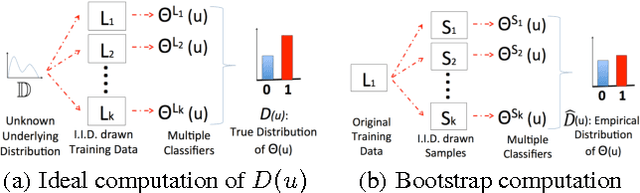
Crowd-sourcing has become a popular means of acquiring labeled data for a wide variety of tasks where humans are more accurate than computers, e.g., labeling images, matching objects, or analyzing sentiment. However, relying solely on the crowd is often impractical even for data sets with thousands of items, due to time and cost constraints of acquiring human input (which cost pennies and minutes per label). In this paper, we propose algorithms for integrating machine learning into crowd-sourced databases, with the goal of allowing crowd-sourcing applications to scale, i.e., to handle larger datasets at lower costs. The key observation is that, in many of the above tasks, humans and machine learning algorithms can be complementary, as humans are often more accurate but slow and expensive, while algorithms are usually less accurate, but faster and cheaper. Based on this observation, we present two new active learning algorithms to combine humans and algorithms together in a crowd-sourced database. Our algorithms are based on the theory of non-parametric bootstrap, which makes our results applicable to a broad class of machine learning models. Our results, on three real-life datasets collected with Amazon's Mechanical Turk, and on 15 well-known UCI data sets, show that our methods on average ask humans to label one to two orders of magnitude fewer items to achieve the same accuracy as a baseline that labels random images, and two to eight times fewer questions than previous active learning schemes.