 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDatabase Learning: Toward a Database that Becomes Smarter Every Time
Paper and Code
Mar 28, 2017

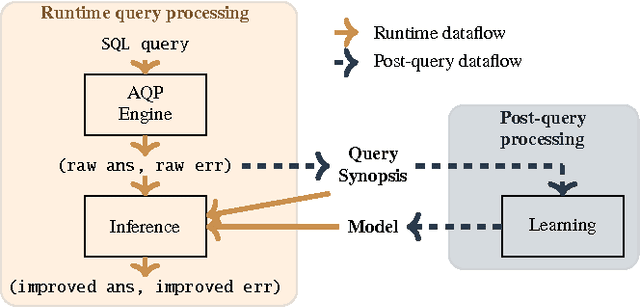
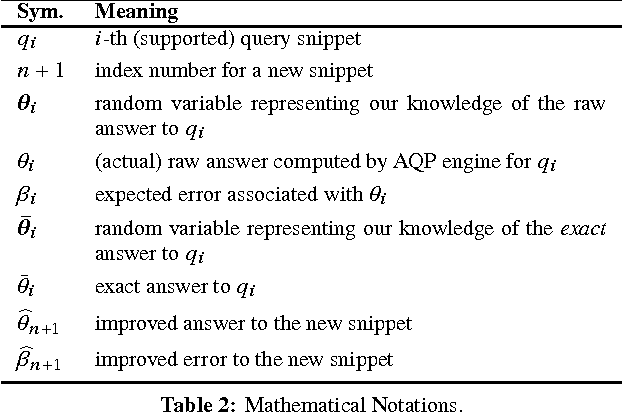
In today's databases, previous query answers rarely benefit answering future queries. For the first time, to the best of our knowledge, we change this paradigm in an approximate query processing (AQP) context. We make the following observation: the answer to each query reveals some degree of knowledge about the answer to another query because their answers stem from the same underlying distribution that has produced the entire dataset. Exploiting and refining this knowledge should allow us to answer queries more analytically, rather than by reading enormous amounts of raw data. Also, processing more queries should continuously enhance our knowledge of the underlying distribution, and hence lead to increasingly faster response times for future queries. We call this novel idea---learning from past query answers---Database Learning. We exploit the principle of maximum entropy to produce answers, which are in expectation guaranteed to be more accurate than existing sample-based approximations. Empowered by this idea, we build a query engine on top of Spark SQL, called Verdict. We conduct extensive experiments on real-world query traces from a large customer of a major database vendor. Our results demonstrate that Verdict supports 73.7% of these queries, speeding them up by up to 23.0x for the same accuracy level compared to existing AQP systems.