 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIEVE: Effective Filtered Vector Search with Collection of Indexes
Jul 16, 2025Many real-world tasks such as recommending videos with the kids tag can be reduced to finding most similar vectors associated with hard predicates. This task, filtered vector search, is challenging as prior state-of-the-art graph-based (unfiltered) similarity search techniques quickly degenerate when hard constraints are considered. That is, effective graph-based filtered similarity search relies on sufficient connectivity for reaching the most similar items within just a few hops. To consider predicates, recent works propose modifying graph traversal to visit only the items that may satisfy predicates. However, they fail to offer the just-a-few-hops property for a wide range of predicates: they must restrict predicates significantly or lose efficiency if only a small fraction of items satisfy predicates. We propose an opposite approach: instead of constraining traversal, we build many indexes each serving different predicate forms. For effective construction, we devise a three-dimensional analytical model capturing relationships among index size, search time, and recall, with which we follow a workload-aware approach to pack as many useful indexes as possible into a collection. At query time, the analytical model is employed yet again to discern the one that offers the fastest search at a given recall. We show superior performance and support on datasets with varying selectivities and forms: our approach achieves up to 8.06x speedup while having as low as 1% build time versus other indexes, with less than 2.15x memory of a standard HNSW graph and modest knowledge of past workloads.
Cache-of-Thought: Master-Apprentice Framework for Cost-Effective Vision Language Model Inference
Feb 27, 2025Vision Language Models (VLMs) have achieved remarkable success in a wide range of vision applications of increasing complexity and scales, yet choosing the right VLM model size involves a trade-off between response quality and cost. While smaller VLMs are cheaper to run, they typically produce responses only marginally better than random guessing on benchmarks such as MMMU. In this paper, we propose Cache of Thought (CoT), a master apprentice framework for collaborative inference between large and small VLMs. CoT manages high quality query results from large VLMs (master) in a cache, which are then selected via a novel multi modal retrieval and in-context learning to aid the performance of small VLMs (apprentice). We extensively evaluate CoT on various widely recognized and challenging general VQA benchmarks, and show that CoT increases overall VQA performance by up to 7.7% under the same budget, and specifically boosts the performance of apprentice VLMs by up to 36.6%.
Transactional Python for Durable Machine Learning: Vision, Challenges, and Feasibility
May 15, 2023



In machine learning (ML), Python serves as a convenient abstraction for working with key libraries such as PyTorch, scikit-learn, and others. Unlike DBMS, however, Python applications may lose important data, such as trained models and extracted features, due to machine failures or human errors, leading to a waste of time and resources. Specifically, they lack four essential properties that could make ML more reliable and user-friendly -- durability, atomicity, replicability, and time-versioning (DART). This paper presents our vision of Transactional Python that provides DART without any code modifications to user programs or the Python kernel, by non-intrusively monitoring application states at the object level and determining a minimal amount of information sufficient to reconstruct a whole application. Our evaluation of a proof-of-concept implementation with public PyTorch and scikit-learn applications shows that DART can be offered with overheads ranging 1.5%--15.6%.
Airphant: Cloud-oriented Document Indexing
Dec 26, 2021



Modern data warehouses can scale compute nodes independently of storage. These systems persist their data on cloud storage, which is always available and cost-efficient. Ad-hoc compute nodes then fetch necessary data on-demand from cloud storage. This ability to quickly scale or shrink data systems is highly beneficial if query workloads may change over time. We apply this new architecture to search engines with a focus on optimizing their latencies in cloud environments. However, simply placing existing search engines (e.g., Apache Lucene) on top of cloud storage significantly increases their end-to-end query latencies (i.e., more than 6 seconds on average in one of our studies). This is because their indexes can incur multiple network round-trips due to their hierarchical structure (e.g., skip lists, B-trees, learned indexes). To address this issue, we develop a new statistical index (called IoU Sketch). For lookup, IoU Sketch makes multiple asynchronous network requests in parallel. While IoU Sketch may fetch more bytes than existing indexes, it significantly reduces the index lookup time because parallel requests do not block each other. Based on IoU Sketch, we build an end-to-end search engine, called Airphant; we describe how Airphant builds, optimizes, and manages IoU Sketch; and ultimately, supports keyword-based querying. In our experiments with four real datasets, Airphant's average end-to-end latencies are between 13 milliseconds and 300 milliseconds, being up to 8.97x faster than Apache Lucence and 113.39x faster than Elasticsearch.
BlinkML: Efficient Maximum Likelihood Estimation with Probabilistic Guarantees
Dec 26, 2018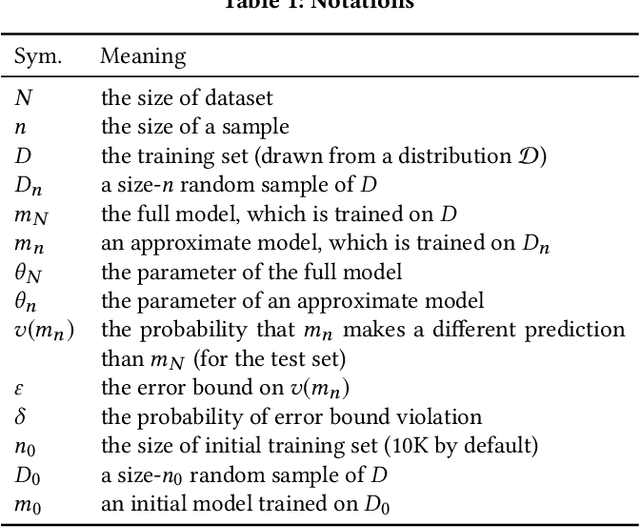
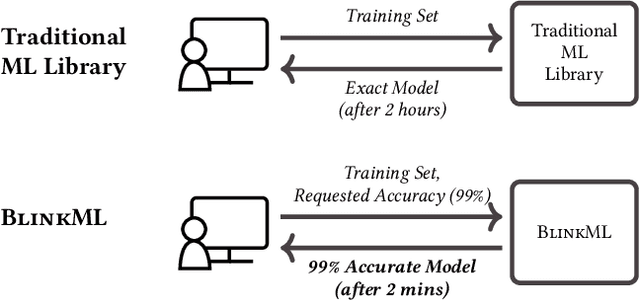
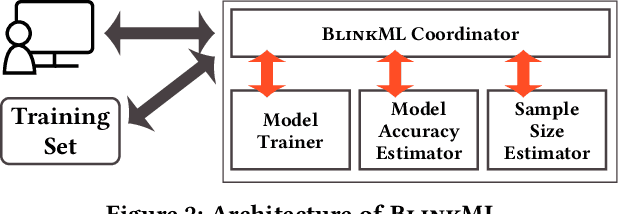
The rising volume of datasets has made training machine learning (ML) models a major computational cost in the enterprise. Given the iterative nature of model and parameter tuning, many analysts use a small sample of their entire data during their initial stage of analysis to make quick decisions (e.g., what features or hyperparameters to use) and use the entire dataset only in later stages (i.e., when they have converged to a specific model). This sampling, however, is performed in an ad-hoc fashion. Most practitioners cannot precisely capture the effect of sampling on the quality of their model, and eventually on their decision-making process during the tuning phase. Moreover, without systematic support for sampling operators, many optimizations and reuse opportunities are lost. In this paper, we introduce BlinkML, a system for fast, quality-guaranteed ML training. BlinkML allows users to make error-computation tradeoffs: instead of training a model on their full data (i.e., full model), BlinkML can quickly train an approximate model with quality guarantees using a sample. The quality guarantees ensure that, with high probability, the approximate model makes the same predictions as the full model. BlinkML currently supports any ML model that relies on maximum likelihood estimation (MLE), which includes Generalized Linear Models (e.g., linear regression, logistic regression, max entropy classifier, Poisson regression) as well as PPCA (Probabilistic Principal Component Analysis). Our experiments show that BlinkML can speed up the training of large-scale ML tasks by 6.26x-629x while guaranteeing the same predictions, with 95% probability, as the full model.
Database Learning: Toward a Database that Becomes Smarter Every Time
Mar 28, 2017

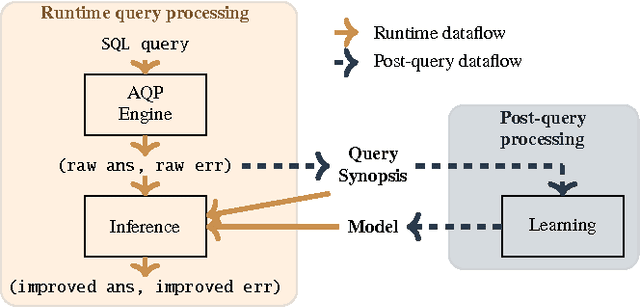
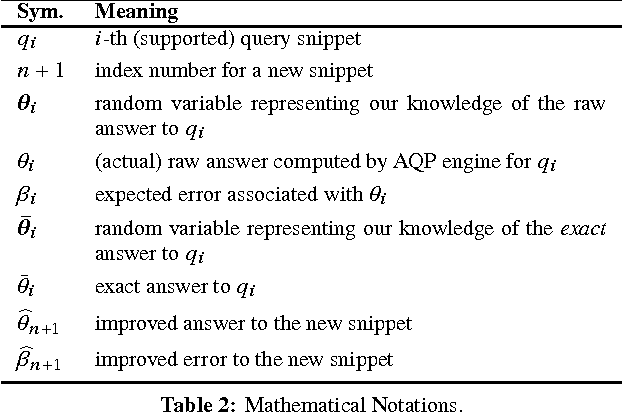
In today's databases, previous query answers rarely benefit answering future queries. For the first time, to the best of our knowledge, we change this paradigm in an approximate query processing (AQP) context. We make the following observation: the answer to each query reveals some degree of knowledge about the answer to another query because their answers stem from the same underlying distribution that has produced the entire dataset. Exploiting and refining this knowledge should allow us to answer queries more analytically, rather than by reading enormous amounts of raw data. Also, processing more queries should continuously enhance our knowledge of the underlying distribution, and hence lead to increasingly faster response times for future queries. We call this novel idea---learning from past query answers---Database Learning. We exploit the principle of maximum entropy to produce answers, which are in expectation guaranteed to be more accurate than existing sample-based approximations. Empowered by this idea, we build a query engine on top of Spark SQL, called Verdict. We conduct extensive experiments on real-world query traces from a large customer of a major database vendor. Our results demonstrate that Verdict supports 73.7% of these queries, speeding them up by up to 23.0x for the same accuracy level compared to existing AQP systems.