 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer with Memory Replay
Paper and Code
May 19, 2022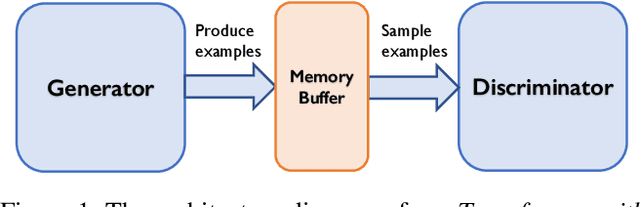

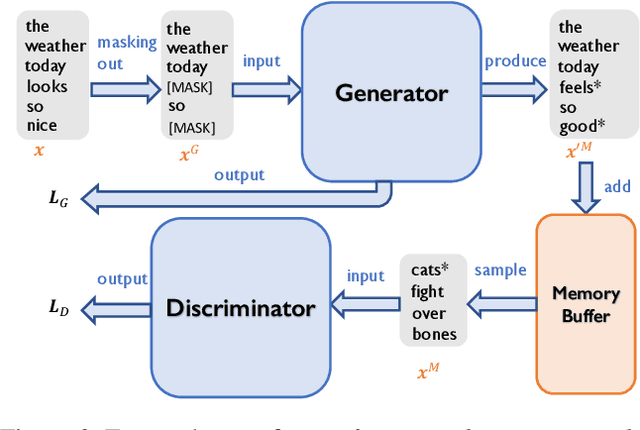
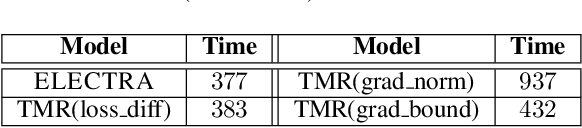
Transformers achieve state-of-the-art performance for natural language processing tasks by pre-training on large-scale text corpora. They are extremely compute-intensive and have very high sample complexity. Memory replay is a mechanism that remembers and reuses past examples by saving to and replaying from a memory buffer. It has been successfully used in reinforcement learning and GANs due to better sample efficiency. In this paper, we propose \emph{Transformer with Memory Replay} (TMR), which integrates memory replay with transformer, making transformer more sample-efficient. Experiments on GLUE and SQuAD benchmark datasets show that Transformer with Memory Replay achieves at least $1\%$ point increase compared to the baseline transformer model when pretrained with the same number of examples. Further, by adopting a careful design that reduces the wall-clock time overhead of memory replay, we also empirically achieve a better runtime efficiency.