 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Active Sequential Prediction-Powered Mean Estimation
Apr 20, 2026In this work, we revisit the problem of active sequential prediction-powered mean estimation, where at each round one must decide the query probability of the ground-truth label upon observing the covariates of a sample. Furthermore, if the label is not queried, the prediction from a machine learning model is used instead. Prior work proposed an elegant scheme that determines the query probability by combining an uncertainty-based suggestion with a constant probability that encodes a soft constraint on the query probability. We explored different values of the mixing parameter and observed an intriguing empirical pattern: the smallest confidence width tends to occur when the weight on the constant probability is close to one, thereby reducing the influence of the uncertainty-based component. Motivated by this observation, we develop a non-asymptotic analysis of the estimator and establish a data-dependent bound on its confidence interval. Our analysis further suggests that when a no-regret learning approach is used to determine the query probability and control this bound, the query probability converges to the constraint of the max value of the query probability when it is chosen obliviously to the current covariates. We also conduct simulations that corroborate these theoretical findings.
Lions and Muons: Optimization via Stochastic Frank-Wolfe
Jun 04, 2025Stochastic Frank-Wolfe is a classical optimization method for solving constrained optimization problems. On the other hand, recent optimizers such as Lion and Muon have gained quite significant popularity in deep learning. In this work, we provide a unifying perspective by interpreting these seemingly disparate methods through the lens of Stochastic Frank-Wolfe. Specifically, we show that Lion and Muon with weight decay can be viewed as special instances of a Stochastic Frank-Wolfe, and we establish their convergence guarantees in terms of the Frank-Wolfe gap, a standard stationarity measure in non-convex optimization for Frank-Wolfe methods. We further find that convergence to this gap implies convergence to a KKT point of the original problem under a norm constraint for Lion and Muon. Moreover, motivated by recent empirical findings that stochastic gradients in modern machine learning tasks often exhibit heavy-tailed distributions, we extend Stochastic Frank-Wolfe to settings with heavy-tailed noise by developing two robust variants with strong theoretical guarantees, which in turn yields new variants of Lion and Muon.
Optimistic Interior Point Methods for Sequential Hypothesis Testing by Betting
Feb 11, 2025The technique of "testing by betting" frames nonparametric sequential hypothesis testing as a multiple-round game, where a player bets on future observations that arrive in a streaming fashion, accumulates wealth that quantifies evidence against the null hypothesis, and rejects the null once the wealth exceeds a specified threshold while controlling the false positive error. Designing an online learning algorithm that achieves a small regret in the game can help rapidly accumulate the bettor's wealth, which in turn can shorten the time to reject the null hypothesis under the alternative $H_1$. However, many of the existing works employ the Online Newton Step (ONS) to update within a halved decision space to avoid a gradient explosion issue, which is potentially conservative for rapid wealth accumulation. In this paper, we introduce a novel strategy utilizing interior-point methods in optimization that allows updates across the entire interior of the decision space without the risk of gradient explosion. Our approach not only maintains strong statistical guarantees but also facilitates faster null hypothesis rejection in critical scenarios, overcoming the limitations of existing approaches.
Online Detecting LLM-Generated Texts via Sequential Hypothesis Testing by Betting
Oct 29, 2024



Developing algorithms to differentiate between machine-generated texts and human-written texts has garnered substantial attention in recent years. Existing methods in this direction typically concern an offline setting where a dataset containing a mix of real and machine-generated texts is given upfront, and the task is to determine whether each sample in the dataset is from a large language model (LLM) or a human. However, in many practical scenarios, sources such as news websites, social media accounts, or on other forums publish content in a streaming fashion. Therefore, in this online scenario, how to quickly and accurately determine whether the source is an LLM with strong statistical guarantees is crucial for these media or platforms to function effectively and prevent the spread of misinformation and other potential misuse of LLMs. To tackle the problem of online detection, we develop an algorithm based on the techniques of sequential hypothesis testing by betting that not only builds upon and complements existing offline detection techniques but also enjoys statistical guarantees, which include a controlled false positive rate and the expected time to correctly identify a source as an LLM. Experiments were conducted to demonstrate the effectiveness of our method.
Continuized Acceleration for Quasar Convex Functions in Non-Convex Optimization
Feb 15, 2023Quasar convexity is a condition that allows some first-order methods to efficiently minimize a function even when the optimization landscape is non-convex. Previous works develop near-optimal accelerated algorithms for minimizing this class of functions, however, they require a subroutine of binary search which results in multiple calls to gradient evaluations in each iteration, and consequently the total number of gradient evaluations does not match a known lower bound. In this work, we show that a recently proposed continuized Nesterov acceleration can be applied to minimizing quasar convex functions and achieves the optimal bound with a high probability. Furthermore, we find that the objective functions of training generalized linear models (GLMs) satisfy quasar convexity, which broadens the applicability of the relevant algorithms, while known practical examples of quasar convexity in non-convex learning are sparse in the literature. We also show that if a smooth and one-point strongly convex, Polyak-Lojasiewicz, or quadratic-growth function satisfies quasar convexity, then attaining an accelerated linear rate for minimizing the function is possible under certain conditions, while acceleration is not known in general for these classes of functions.
Towards Understanding GD with Hard and Conjugate Pseudo-labels for Test-Time Adaptation
Oct 18, 2022


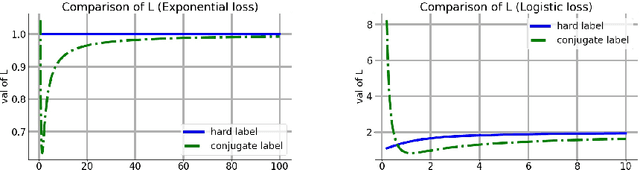
We consider a setting that a model needs to adapt to a new domain under distribution shifts, given that only unlabeled test samples from the new domain are accessible at test time. A common idea in most of the related works is constructing pseudo-labels for the unlabeled test samples and applying gradient descent (GD) to a loss function with the pseudo-labels. Recently, Goyal et al. (2022) propose conjugate labels, which is a new kind of pseudo-labels for self-training at test time. They empirically show that the conjugate label outperforms other ways of pseudo-labeling on many domain adaptation benchmarks. However, provably showing that GD with conjugate labels learns a good classifier for test-time adaptation remains open. In this work, we aim at theoretically understanding GD with hard and conjugate labels for a binary classification problem. We show that for square loss, GD with conjugate labels converges to a solution that minimizes the testing 0-1 loss under a Gaussian model, while GD with hard pseudo-labels fails in this task. We also analyze them under different loss functions for the update. Our results shed lights on understanding when and why GD with hard labels or conjugate labels works in test-time adaptation.
Accelerating Hamiltonian Monte Carlo via Chebyshev Integration Time
Jul 05, 2022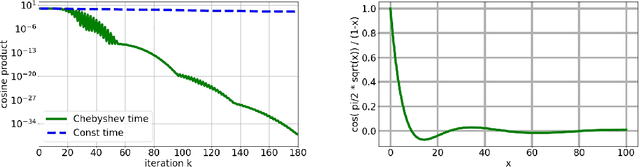

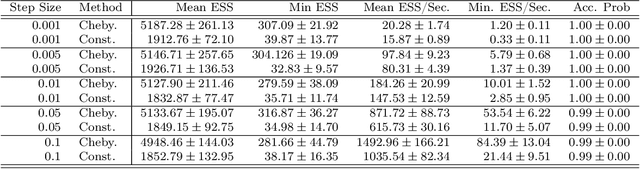

Hamiltonian Monte Carlo (HMC) is a popular method in sampling. While there are quite a few works of studying this method on various aspects, an interesting question is how to choose its integration time to achieve acceleration. In this work, we consider accelerating the process of sampling from a distribution $\pi(x) \propto \exp(-f(x))$ via HMC via time-varying integration time. When the potential $f$ is $L$-smooth and $m$-strongly convex, i.e.\ for sampling from a log-smooth and strongly log-concave target distribution $\pi$, it is known that under a constant integration time, the number of iterations that ideal HMC takes to get an $\epsilon$ Wasserstein-2 distance to the target $\pi$ is $O( \kappa \log \frac{1}{\epsilon} )$, where $\kappa := \frac{L}{m}$ is the condition number. We propose a scheme of time-varying integration time based on the roots of Chebyshev polynomials. We show that in the case of quadratic potential $f$, i.e., when the target $\pi$ is a Gaussian distribution, ideal HMC with this choice of integration time only takes $O( \sqrt{\kappa} \log \frac{1}{\epsilon} )$ number of iterations to reach Wasserstein-2 distance less than $\epsilon$; this improvement on the dependence on condition number is akin to acceleration in optimization. The design and analysis of HMC with the proposed integration time is built on the tools of Chebyshev polynomials. Experiments find the advantage of adopting our scheme of time-varying integration time even for sampling from distributions with smooth strongly convex potentials that are not quadratic.
Provable Acceleration of Heavy Ball beyond Quadratics for a Class of Polyak-Łojasiewicz Functions when the Non-Convexity is Averaged-Out
Jun 22, 2022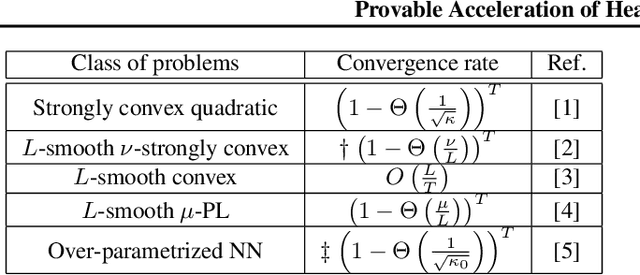
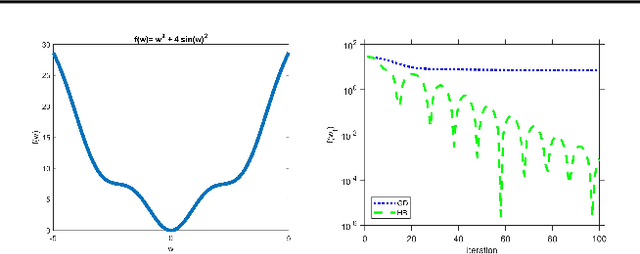
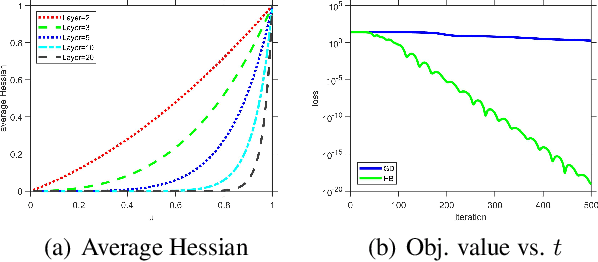
Heavy Ball (HB) nowadays is one of the most popular momentum methods in non-convex optimization. It has been widely observed that incorporating the Heavy Ball dynamic in gradient-based methods accelerates the training process of modern machine learning models. However, the progress on establishing its theoretical foundation of acceleration is apparently far behind its empirical success. Existing provable acceleration results are of the quadratic or close-to-quadratic functions, as the current techniques of showing HB's acceleration are limited to the case when the Hessian is fixed. In this work, we develop some new techniques that help show acceleration beyond quadratics, which is achieved by analyzing how the change of the Hessian at two consecutive time points affects the convergence speed. Based on our technical results, a class of Polyak-\L{}ojasiewicz (PL) optimization problems for which provable acceleration can be achieved via HB is identified. Moreover, our analysis demonstrates a benefit of adaptively setting the momentum parameter.
No-Regret Dynamics in the Fenchel Game: A Unified Framework for Algorithmic Convex Optimization
Nov 22, 2021

We develop an algorithmic framework for solving convex optimization problems using no-regret game dynamics. By converting the problem of minimizing a convex function into an auxiliary problem of solving a min-max game in a sequential fashion, we can consider a range of strategies for each of the two-players who must select their actions one after the other. A common choice for these strategies are so-called no-regret learning algorithms, and we describe a number of such and prove bounds on their regret. We then show that many classical first-order methods for convex optimization -- including average-iterate gradient descent, the Frank-Wolfe algorithm, the Heavy Ball algorithm, and Nesterov's acceleration methods -- can be interpreted as special cases of our framework as long as each player makes the correct choice of no-regret strategy. Proving convergence rates in this framework becomes very straightforward, as they follow from plugging in the appropriate known regret bounds. Our framework also gives rise to a number of new first-order methods for special cases of convex optimization that were not previously known.
Understanding Modern Techniques in Optimization: Frank-Wolfe, Nesterov's Momentum, and Polyak's Momentum
Jun 23, 2021In the first part of this dissertation research, we develop a modular framework that can serve as a recipe for constructing and analyzing iterative algorithms for convex optimization. Specifically, our work casts optimization as iteratively playing a two-player zero-sum game. Many existing optimization algorithms including Frank-Wolfe and Nesterov's acceleration methods can be recovered from the game by pitting two online learners with appropriate strategies against each other. Furthermore, the sum of the weighted average regrets of the players in the game implies the convergence rate. As a result, our approach provides simple alternative proofs to these algorithms. Moreover, we demonstrate that our approach of optimization as iteratively playing a game leads to three new fast Frank-Wolfe-like algorithms for some constraint sets, which further shows that our framework is indeed generic, modular, and easy-to-use. In the second part, we develop a modular analysis of provable acceleration via Polyak's momentum for certain problems, which include solving the classical strongly quadratic convex problems, training a wide ReLU network under the neural tangent kernel regime, and training a deep linear network with an orthogonal initialization. We develop a meta theorem and show that when applying Polyak's momentum for these problems, the induced dynamics exhibit a form where we can directly apply our meta theorem. In the last part of the dissertation, we show another advantage of the use of Polyak's momentum -- it facilitates fast saddle point escape in smooth non-convex optimization. This result, together with those of the second part, sheds new light on Polyak's momentum in modern non-convex optimization and deep learning.