 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWASE: Learning When to Attend for Speaker Extraction in Cocktail Party Environments
Paper and Code
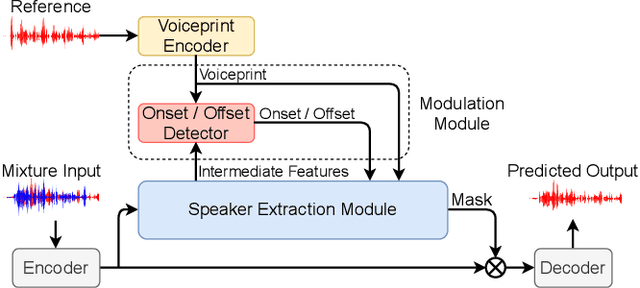
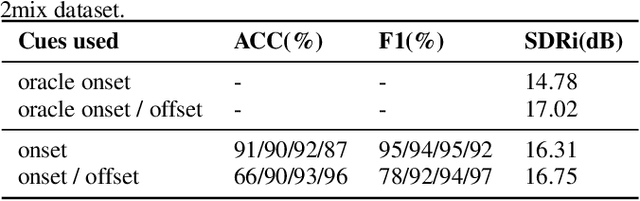
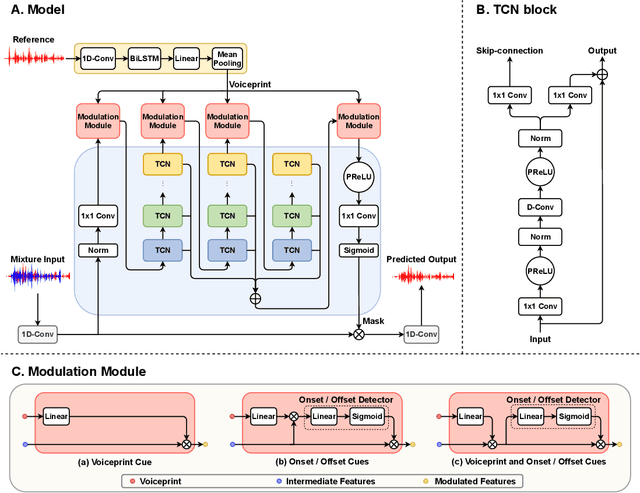
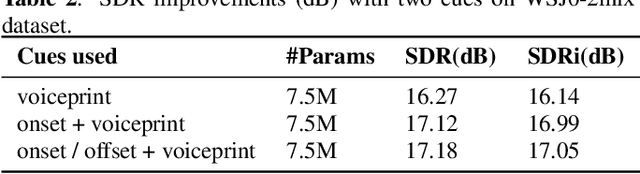
In the speaker extraction problem, it is found that additional information from the target speaker contributes to the tracking and extraction of the target speaker, which includes voiceprint, lip movement, facial expression, and spatial information. However, no one cares for the cue of sound onset, which has been emphasized in the auditory scene analysis and psychology. Inspired by it, we explicitly modeled the onset cue and verified the effectiveness in the speaker extraction task. We further extended to the onset/offset cues and got performance improvement. From the perspective of tasks, our onset/offset-based model completes the composite task, a complementary combination of speaker extraction and speaker-dependent voice activity detection. We also combined voiceprint with onset/offset cues. Voiceprint models voice characteristics of the target while onset/offset models the start/end information of the speech. From the perspective of auditory scene analysis, the combination of two perception cues can promote the integrity of the auditory object. The experiment results are also close to state-of-the-art performance, using nearly half of the parameters. We hope that this work will inspire communities of speech processing and psychology, and contribute to communication between them. Our code will be available in https://github.com/aispeech-lab/wase/.