 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Concise but Effective Network for Image Guided Depth Completion in Autonomous Driving
Jan 29, 2024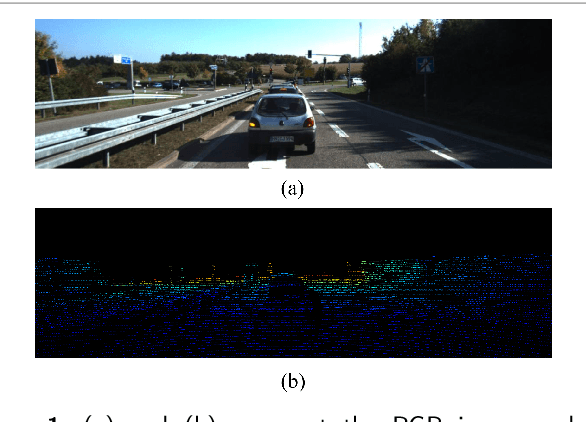
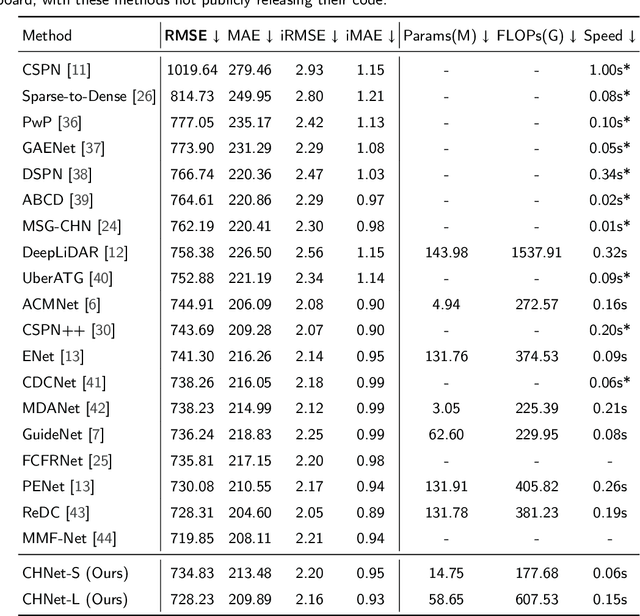
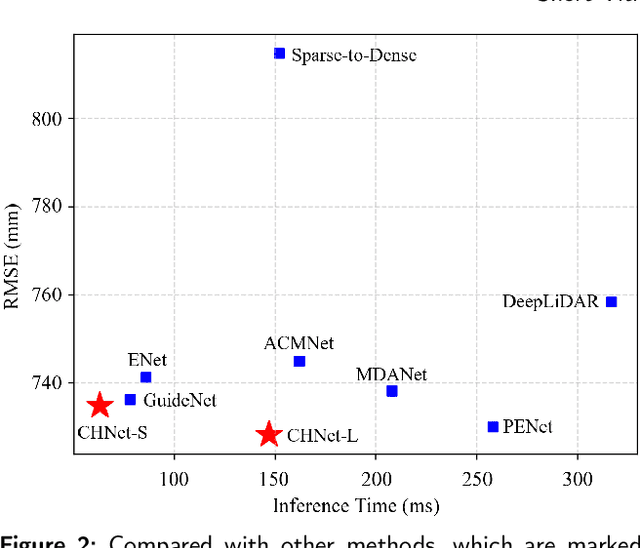
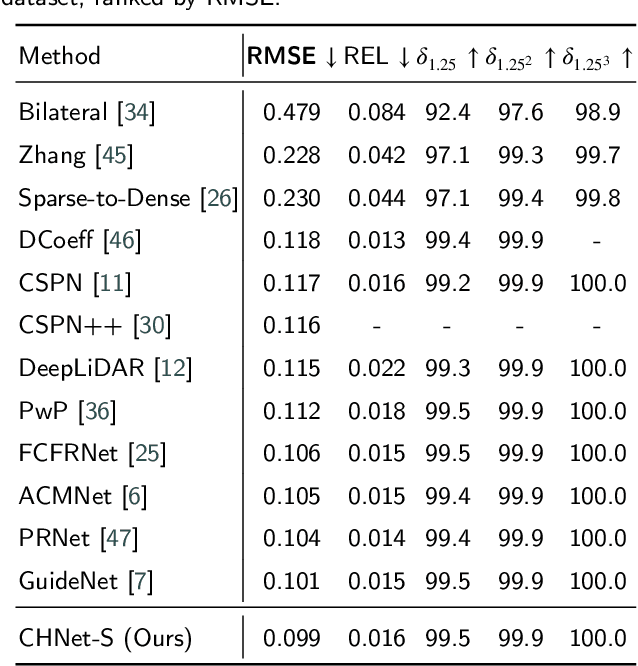
Depth completion is a crucial task in autonomous driving, aiming to convert a sparse depth map into a dense depth prediction. Due to its potentially rich semantic information, RGB image is commonly fused to enhance the completion effect. Image-guided depth completion involves three key challenges: 1) how to effectively fuse the two modalities; 2) how to better recover depth information; and 3) how to achieve real-time prediction for practical autonomous driving. To solve the above problems, we propose a concise but effective network, named CENet, to achieve high-performance depth completion with a simple and elegant structure. Firstly, we use a fast guidance module to fuse the two sensor features, utilizing abundant auxiliary features extracted from the color space. Unlike other commonly used complicated guidance modules, our approach is intuitive and low-cost. In addition, we find and analyze the optimization inconsistency problem for observed and unobserved positions, and a decoupled depth prediction head is proposed to alleviate the issue. The proposed decoupled head can better output the depth of valid and invalid positions with very few extra inference time. Based on the simple structure of dual-encoder and single-decoder, our CENet can achieve superior balance between accuracy and efficiency. In the KITTI depth completion benchmark, our CENet attains competitive performance and inference speed compared with the state-of-the-art methods. To validate the generalization of our method, we also evaluate on indoor NYUv2 dataset, and our CENet still achieve impressive results. The code of this work will be available at https://github.com/lmomoy/CENet.
A Stronger Stitching Algorithm for Fisheye Images based on Deblurring and Registration
Jul 22, 2023Fisheye lens, which is suitable for panoramic imaging, has the prominent advantage of a large field of view and low cost. However, the fisheye image has a severe geometric distortion which may interfere with the stage of image registration and stitching. Aiming to resolve this drawback, we devise a stronger stitching algorithm for fisheye images by combining the traditional image processing method with deep learning. In the stage of fisheye image correction, we propose the Attention-based Nonlinear Activation Free Network (ANAFNet) to deblur fisheye images corrected by Zhang calibration method. Specifically, ANAFNet adopts the classical single-stage U-shaped architecture based on convolutional neural networks with soft-attention technique and it can restore a sharp image from a blurred image effectively. In the part of image registration, we propose the ORB-FREAK-GMS (OFG), a comprehensive image matching algorithm, to improve the accuracy of image registration. Experimental results demonstrate that panoramic images of superior quality stitching by fisheye images can be obtained through our method.
Self-supervised Sequential Information Bottleneck for Robust Exploration in Deep Reinforcement Learning
Sep 12, 2022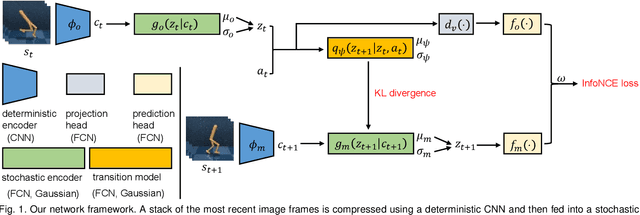
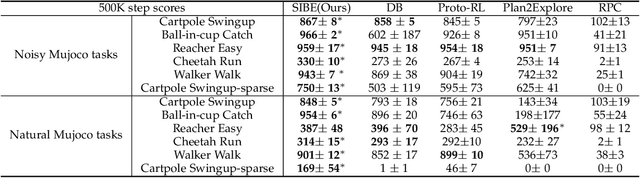
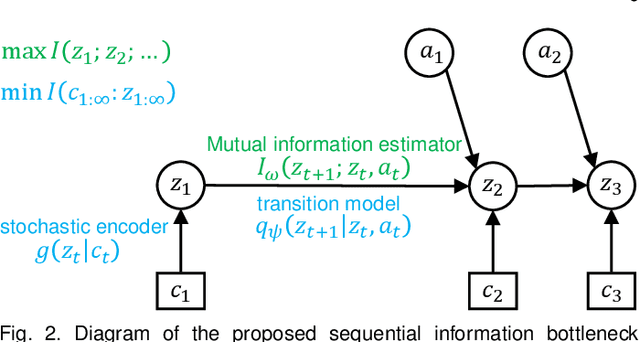

Effective exploration is critical for reinforcement learning agents in environments with sparse rewards or high-dimensional state-action spaces. Recent works based on state-visitation counts, curiosity and entropy-maximization generate intrinsic reward signals to motivate the agent to visit novel states for exploration. However, the agent can get distracted by perturbations to sensor inputs that contain novel but task-irrelevant information, e.g. due to sensor noise or changing background. In this work, we introduce the sequential information bottleneck objective for learning compressed and temporally coherent representations by modelling and compressing sequential predictive information in time-series observations. For efficient exploration in noisy environments, we further construct intrinsic rewards that capture task-relevant state novelty based on the learned representations. We derive a variational upper bound of our sequential information bottleneck objective for practical optimization and provide an information-theoretic interpretation of the derived upper bound. Our experiments on a set of challenging image-based simulated control tasks show that our method achieves better sample efficiency, and robustness to both white noise and natural video backgrounds compared to state-of-art methods based on curiosity, entropy maximization and information-gain.
LF-YOLO: A Lighter and Faster YOLO for Weld Defect Detection of X-ray Image
Nov 18, 2021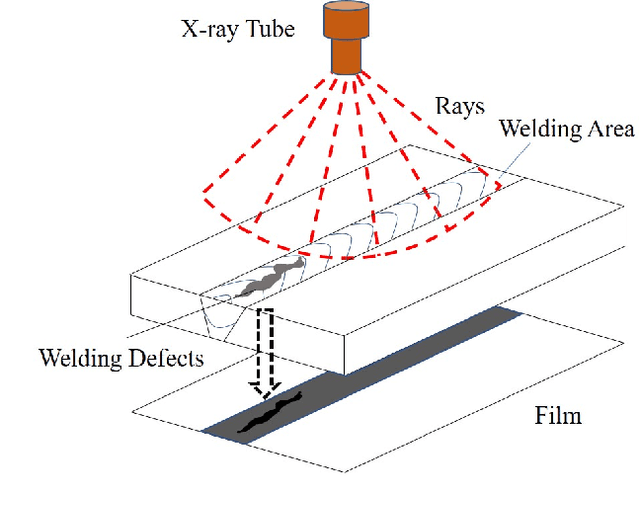

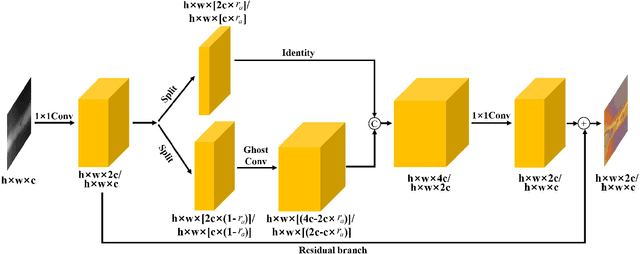
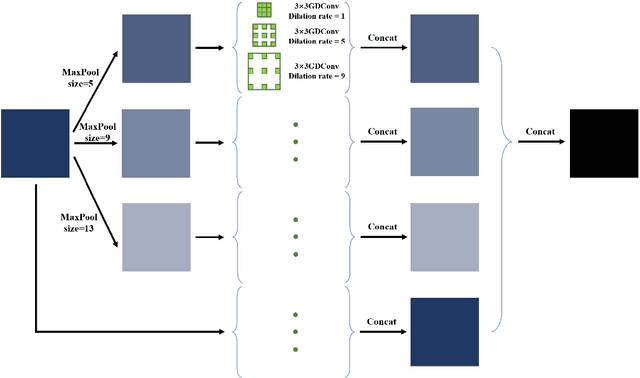
X-ray image plays an important role in manufacturing industry for quality assurance, because it can reflect the internal condition of weld region. However, the shape and scale of different defect types vary greatly, which makes it challenging for model to detect weld defects. In this paper, we propose a weld defect detection method based on convolution neural network, namely Lighter and Faster YOLO (LF-YOLO). In particularly, a reinforced multiscale feature (RMF) module is designed to implement both parameter-based and parameter-free multi-scale information extracting operation. RMF enables the extracted feature map capable to represent more plentiful information, which is achieved by superior hierarchical fusion structure. To improve the performance of detection network, we propose an efficient feature extraction (EFE) module. EFE processes input data with extremely low consumption, and improves the practicability of whole network in actual industry. Experimental results show that our weld defect detection network achieves satisfactory balance between performance and consumption, and reaches 92.9 mean average precision mAP50 with 61.5 frames per second (FPS). To further prove the ability of our method, we test it on public dataset MS COCO, and the results show that our LF-YOLO has a outstanding versatility detection performance. The code is available at https://github.com/lmomoy/LF-YOLO.
A Lightweight and Accurate Recognition Framework for Signs of X-ray Weld Images
Oct 18, 2021
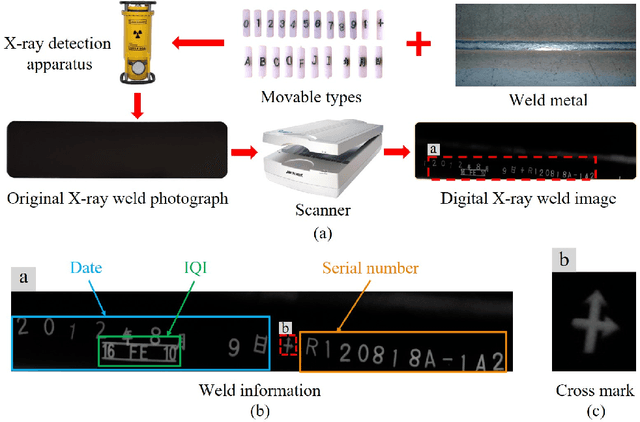
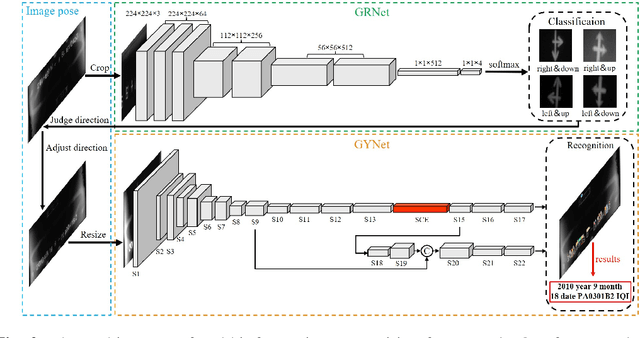
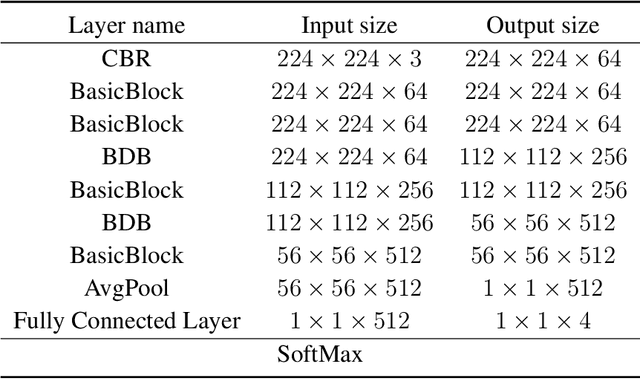
X-ray images are commonly used to ensure the security of devices in quality inspection industry. The recognition of signs printed on X-ray weld images plays an essential role in digital traceability system of manufacturing industry. However, the scales of objects vary different greatly in weld images, and it hinders us to achieve satisfactory recognition. In this paper, we propose a signs recognition framework based on convolutional neural networks (CNNs) for weld images. The proposed framework firstly contains a shallow classification network for correcting the pose of images. Moreover, we present a novel spatial and channel enhancement (SCE) module to address the above scale problem. This module can integrate multi-scale features and adaptively assign weights for each feature source. Based on SCE module, a narrow network is designed for final weld information recognition. To enhance the practicability of our framework, we carefully design the architecture of framework with a few parameters and computations. Experimental results show that our framework achieves 99.7% accuracy with 1.1 giga floating-point of operations (GFLOPs) on classification stage, and 90.0 mean average precision (mAP) with 176.1 frames per second (FPS) on recognition stage.