 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGVSynergy-Det: Synergistic Gaussian-Voxel Representations for Multi-View 3D Object Detection
Dec 29, 2025Image-based 3D object detection aims to identify and localize objects in 3D space using only RGB images, eliminating the need for expensive depth sensors required by point cloud-based methods. Existing image-based approaches face two critical challenges: methods achieving high accuracy typically require dense 3D supervision, while those operating without such supervision struggle to extract accurate geometry from images alone. In this paper, we present GVSynergy-Det, a novel framework that enhances 3D detection through synergistic Gaussian-Voxel representation learning. Our key insight is that continuous Gaussian and discrete voxel representations capture complementary geometric information: Gaussians excel at modeling fine-grained surface details while voxels provide structured spatial context. We introduce a dual-representation architecture that: 1) adapts generalizable Gaussian Splatting to extract complementary geometric features for detection tasks, and 2) develops a cross-representation enhancement mechanism that enriches voxel features with geometric details from Gaussian fields. Unlike previous methods that either rely on time-consuming per-scene optimization or utilize Gaussian representations solely for depth regularization, our synergistic strategy directly leverages features from both representations through learnable integration, enabling more accurate object localization. Extensive experiments demonstrate that GVSynergy-Det achieves state-of-the-art results on challenging indoor benchmarks, significantly outperforming existing methods on both ScanNetV2 and ARKitScenes datasets, all without requiring any depth or dense 3D geometry supervision (e.g., point clouds or TSDF).
Specific Multi-emitter Identification: Theoretical Limits and Low-complexity Design
Dec 22, 2025Specific emitter identification (SEI) distinguishes emitters by utilizing hardware-induced signal imperfections. However, conventional SEI techniques are primarily designed for single-emitter scenarios. This poses a fundamental limitation in distributed wireless networks, where simultaneous transmissions from multiple emitters result in overlapping signals that conventional single-emitter identification methods cannot effectively handle. To overcome this limitation, we present a specific multi-emitter identification (SMEI) framework via multi-label learning, treating identification as a problem of directly decoding emitter states from overlapping signals. Theoretically, we establish performance bounds using Fano's inequality. Methodologically, the multi-label formulation reduces output dimensionality from exponential to linear scale, thereby substantially decreasing computational complexity. Additionally, we propose an improved SMEI (I-SMEI), which incorporates multi-head attention to effectively capture features in correlated signal combinations. Experimental results demonstrate that SMEI achieves high identification accuracy with a linear computational complexity. Furthermore, the proposed I-SMEI scheme significantly improves identification accuracy across various overlapping scenarios compared to the proposed SMEI and other advanced methods.
A Survey of Embodied Learning for Object-Centric Robotic Manipulation
Aug 21, 2024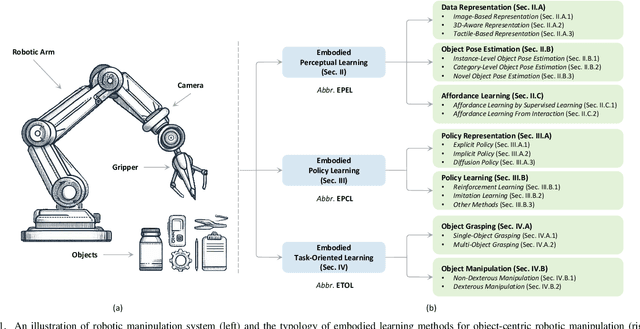
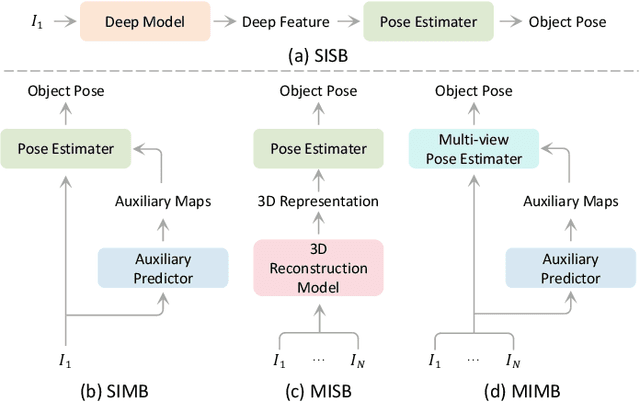
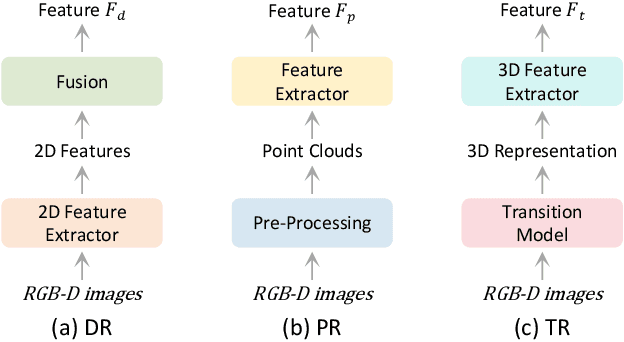
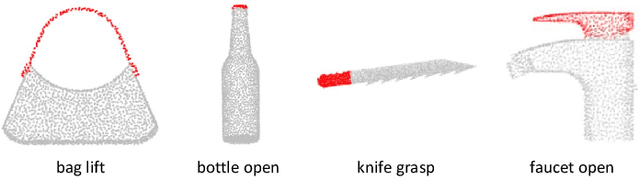
Embodied learning for object-centric robotic manipulation is a rapidly developing and challenging area in embodied AI. It is crucial for advancing next-generation intelligent robots and has garnered significant interest recently. Unlike data-driven machine learning methods, embodied learning focuses on robot learning through physical interaction with the environment and perceptual feedback, making it especially suitable for robotic manipulation. In this paper, we provide a comprehensive survey of the latest advancements in this field and categorize the existing work into three main branches: 1) Embodied perceptual learning, which aims to predict object pose and affordance through various data representations; 2) Embodied policy learning, which focuses on generating optimal robotic decisions using methods such as reinforcement learning and imitation learning; 3) Embodied task-oriented learning, designed to optimize the robot's performance based on the characteristics of different tasks in object grasping and manipulation. In addition, we offer an overview and discussion of public datasets, evaluation metrics, representative applications, current challenges, and potential future research directions. A project associated with this survey has been established at https://github.com/RayYoh/OCRM_survey.
SGIFormer: Semantic-guided and Geometric-enhanced Interleaving Transformer for 3D Instance Segmentation
Jul 16, 2024In recent years, transformer-based models have exhibited considerable potential in point cloud instance segmentation. Despite the promising performance achieved by existing methods, they encounter challenges such as instance query initialization problems and excessive reliance on stacked layers, rendering them incompatible with large-scale 3D scenes. This paper introduces a novel method, named SGIFormer, for 3D instance segmentation, which is composed of the Semantic-guided Mix Query (SMQ) initialization and the Geometric-enhanced Interleaving Transformer (GIT) decoder. Specifically, the principle of our SMQ initialization scheme is to leverage the predicted voxel-wise semantic information to implicitly generate the scene-aware query, yielding adequate scene prior and compensating for the learnable query set. Subsequently, we feed the formed overall query into our GIT decoder to alternately refine instance query and global scene features for further capturing fine-grained information and reducing complex design intricacies simultaneously. To emphasize geometric property, we consider bias estimation as an auxiliary task and progressively integrate shifted point coordinates embedding to reinforce instance localization. SGIFormer attains state-of-the-art performance on ScanNet V2, ScanNet200 datasets, and the challenging high-fidelity ScanNet++ benchmark, striking a balance between accuracy and efficiency. The code, weights, and demo videos are publicly available at https://rayyoh.github.io/sgiformer.
A Concise but Effective Network for Image Guided Depth Completion in Autonomous Driving
Jan 29, 2024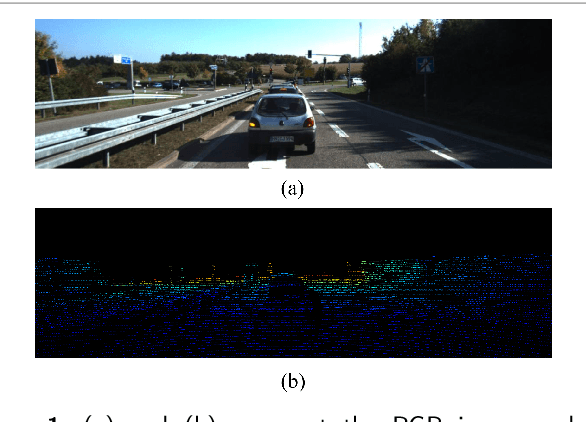
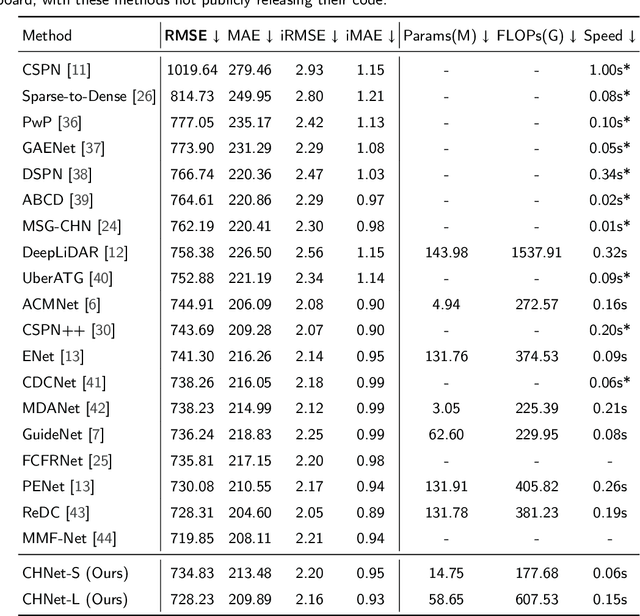
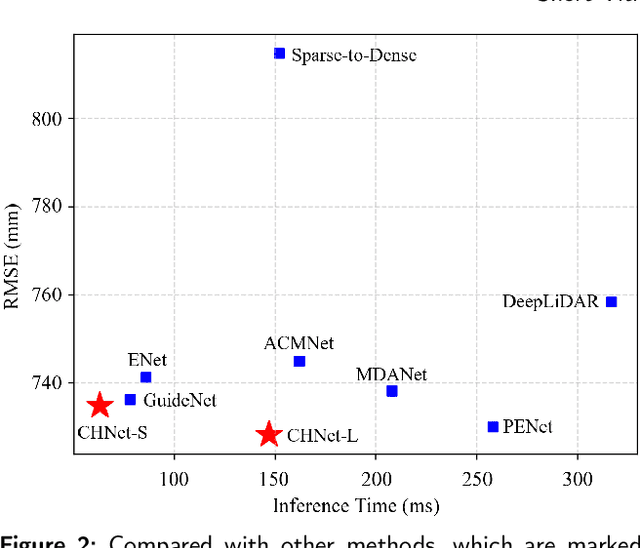
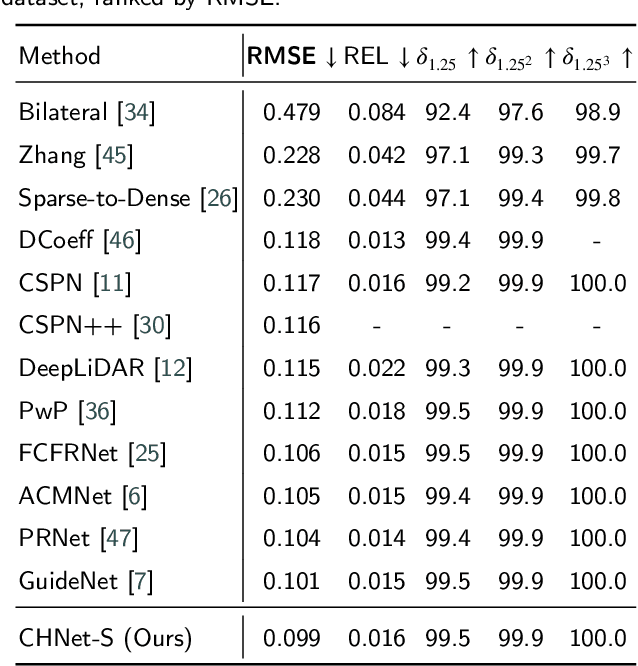
Depth completion is a crucial task in autonomous driving, aiming to convert a sparse depth map into a dense depth prediction. Due to its potentially rich semantic information, RGB image is commonly fused to enhance the completion effect. Image-guided depth completion involves three key challenges: 1) how to effectively fuse the two modalities; 2) how to better recover depth information; and 3) how to achieve real-time prediction for practical autonomous driving. To solve the above problems, we propose a concise but effective network, named CENet, to achieve high-performance depth completion with a simple and elegant structure. Firstly, we use a fast guidance module to fuse the two sensor features, utilizing abundant auxiliary features extracted from the color space. Unlike other commonly used complicated guidance modules, our approach is intuitive and low-cost. In addition, we find and analyze the optimization inconsistency problem for observed and unobserved positions, and a decoupled depth prediction head is proposed to alleviate the issue. The proposed decoupled head can better output the depth of valid and invalid positions with very few extra inference time. Based on the simple structure of dual-encoder and single-decoder, our CENet can achieve superior balance between accuracy and efficiency. In the KITTI depth completion benchmark, our CENet attains competitive performance and inference speed compared with the state-of-the-art methods. To validate the generalization of our method, we also evaluate on indoor NYUv2 dataset, and our CENet still achieve impressive results. The code of this work will be available at https://github.com/lmomoy/CENet.
SAI: Solving AI Tasks with Systematic Artificial Intelligence in Communication Network
Oct 13, 2023In the rapid development of artificial intelligence, solving complex AI tasks is a crucial technology in intelligent mobile networks. Despite the good performance of specialized AI models in intelligent mobile networks, they are unable to handle complicated AI tasks. To address this challenge, we propose Systematic Artificial Intelligence (SAI), which is a framework designed to solve AI tasks by leveraging Large Language Models (LLMs) and JSON-format intent-based input to connect self-designed model library and database. Specifically, we first design a multi-input component, which simultaneously integrates Large Language Models (LLMs) and JSON-format intent-based inputs to fulfill the diverse intent requirements of different users. In addition, we introduce a model library module based on model cards which employ model cards to pairwise match between different modules for model composition. Model cards contain the corresponding model's name and the required performance metrics. Then when receiving user network requirements, we execute each subtask for multiple selected model combinations and provide output based on the execution results and LLM feedback. By leveraging the language capabilities of LLMs and the abundant AI models in the model library, SAI can complete numerous complex AI tasks in the communication network, achieving impressive results in network optimization, resource allocation, and other challenging tasks.