 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHAMMER: Harnessing MLLM via Cross-Modal Integration for Intention-Driven 3D Affordance Grounding
Mar 02, 2026Humans commonly identify 3D object affordance through observed interactions in images or videos, and once formed, such knowledge can be generically generalized to novel objects. Inspired by this principle, we advocate for a novel framework that leverages emerging multimodal large language models (MLLMs) for interaction intention-driven 3D affordance grounding, namely HAMMER. Instead of generating explicit object attribute descriptions or relying on off-the-shelf 2D segmenters, we alternatively aggregate the interaction intention depicted in the image into a contact-aware embedding and guide the model to infer textual affordance labels, ensuring it thoroughly excavates object semantics and contextual cues. We further devise a hierarchical cross-modal integration mechanism to fully exploit the complementary information from the MLLM for 3D representation refinement and introduce a multi-granular geometry lifting module that infuses spatial characteristics into the extracted intention embedding, thus facilitating accurate 3D affordance localization. Extensive experiments on public datasets and our newly constructed corrupted benchmark demonstrate the superiority and robustness of HAMMER compared to existing approaches. All code and weights are publicly available.
Interaction-aware Representation Modeling with Co-occurrence Consistency for Egocentric Hand-Object Parsing
Feb 24, 2026A fine-grained understanding of egocentric human-environment interactions is crucial for developing next-generation embodied agents. One fundamental challenge in this area involves accurately parsing hands and active objects. While transformer-based architectures have demonstrated considerable potential for such tasks, several key limitations remain unaddressed: 1) existing query initialization mechanisms rely primarily on semantic cues or learnable parameters, demonstrating limited adaptability to changing active objects across varying input scenes; 2) previous transformer-based methods utilize pixel-level semantic features to iteratively refine queries during mask generation, which may introduce interaction-irrelevant content into the final embeddings; and 3) prevailing models are susceptible to "interaction illusion", producing physically inconsistent predictions. To address these issues, we propose an end-to-end Interaction-aware Transformer (InterFormer), which integrates three key components, i.e., a Dynamic Query Generator (DQG), a Dual-context Feature Selector (DFS), and the Conditional Co-occurrence (CoCo) loss. The DQG explicitly grounds query initialization in the spatial dynamics of hand-object contact, enabling targeted generation of interaction-aware queries for hands and various active objects. The DFS fuses coarse interactive cues with semantic features, thereby suppressing interaction-irrelevant noise and emphasizing the learning of interactive relationships. The CoCo loss incorporates hand-object relationship constraints to enhance physical consistency in prediction. Our model achieves state-of-the-art performance on both the EgoHOS and the challenging out-of-distribution mini-HOI4D datasets, demonstrating its effectiveness and strong generalization ability. Code and models are publicly available at https://github.com/yuggiehk/InterFormer.
ANNEXE: Unified Analyzing, Answering, and Pixel Grounding for Egocentric Interaction
Apr 02, 2025



Egocentric interaction perception is one of the essential branches in investigating human-environment interaction, which lays the basis for developing next-generation intelligent systems. However, existing egocentric interaction understanding methods cannot yield coherent textual and pixel-level responses simultaneously according to user queries, which lacks flexibility for varying downstream application requirements. To comprehend egocentric interactions exhaustively, this paper presents a novel task named Egocentric Interaction Reasoning and pixel Grounding (Ego-IRG). Taking an egocentric image with the query as input, Ego-IRG is the first task that aims to resolve the interactions through three crucial steps: analyzing, answering, and pixel grounding, which results in fluent textual and fine-grained pixel-level responses. Another challenge is that existing datasets cannot meet the conditions for the Ego-IRG task. To address this limitation, this paper creates the Ego-IRGBench dataset based on extensive manual efforts, which includes over 20k egocentric images with 1.6 million queries and corresponding multimodal responses about interactions. Moreover, we design a unified ANNEXE model to generate text- and pixel-level outputs utilizing multimodal large language models, which enables a comprehensive interpretation of egocentric interactions. The experiments on the Ego-IRGBench exhibit the effectiveness of our ANNEXE model compared with other works.
A Survey of Embodied Learning for Object-Centric Robotic Manipulation
Aug 21, 2024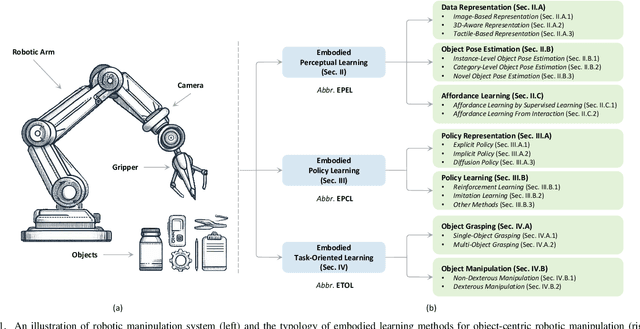
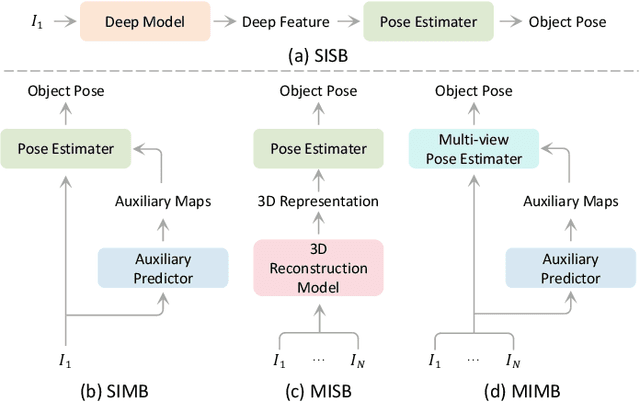
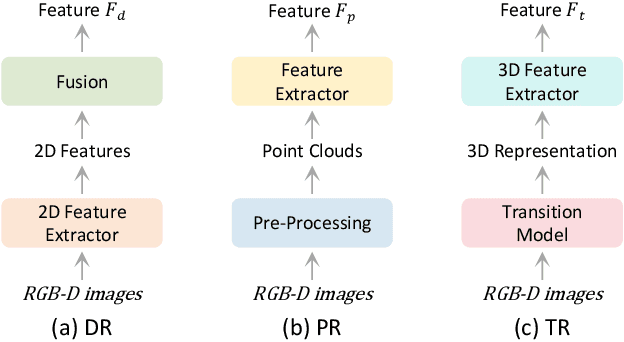
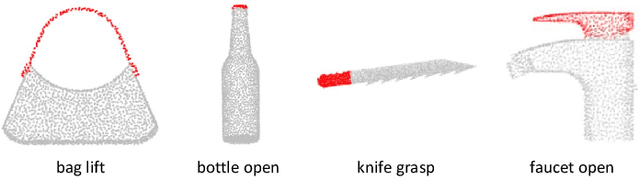
Embodied learning for object-centric robotic manipulation is a rapidly developing and challenging area in embodied AI. It is crucial for advancing next-generation intelligent robots and has garnered significant interest recently. Unlike data-driven machine learning methods, embodied learning focuses on robot learning through physical interaction with the environment and perceptual feedback, making it especially suitable for robotic manipulation. In this paper, we provide a comprehensive survey of the latest advancements in this field and categorize the existing work into three main branches: 1) Embodied perceptual learning, which aims to predict object pose and affordance through various data representations; 2) Embodied policy learning, which focuses on generating optimal robotic decisions using methods such as reinforcement learning and imitation learning; 3) Embodied task-oriented learning, designed to optimize the robot's performance based on the characteristics of different tasks in object grasping and manipulation. In addition, we offer an overview and discussion of public datasets, evaluation metrics, representative applications, current challenges, and potential future research directions. A project associated with this survey has been established at https://github.com/RayYoh/OCRM_survey.
ORMNet: Object-centric Relationship Modeling for Egocentric Hand-object Segmentation
Jul 08, 2024



Egocentric hand-object segmentation (EgoHOS) is a brand-new task aiming at segmenting the hands and interacting objects in the egocentric image. Although significant advancements have been achieved by current methods, establishing an end-to-end model with high accuracy remains an unresolved challenge. Moreover, existing methods lack explicit modeling of the relationships between hands and objects as well as objects and objects, thereby disregarding critical information on hand-object interaction and introducing confusion into algorithms, ultimately leading to a reduction in segmentation performance. To address the limitations of existing methods, this paper proposes a novel end-to-end Object-centric Relationship Modeling Network (ORMNet) for EgoHOS. Specifically, based on a single-encoder and multi-decoder framework, we design the Hand-Object Relation (HOR) module to leverage hand-guided attention to capture the correlation between hands and objects and facilitate their representations. Moreover, based on the observed interrelationships between diverse categories of objects, we introduce the Object Relation Decoupling (ORD) strategy. This strategy allows the decoupling of the two-hand object during training, thereby alleviating the ambiguity of the network. Experimental results on three datasets show that the proposed ORMNet has notably exceptional segmentation performance with robust generalization capabilities.
Deep feature selection-and-fusion for RGB-D semantic segmentation
May 10, 2021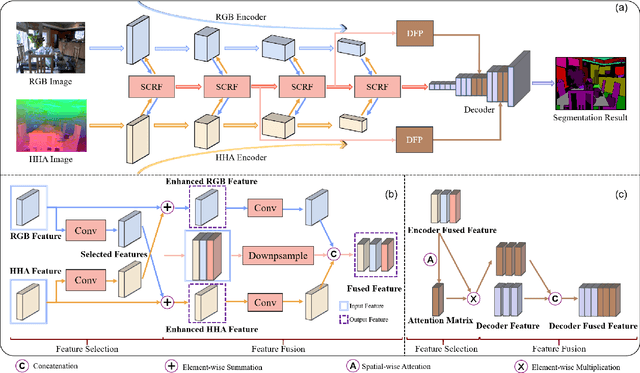


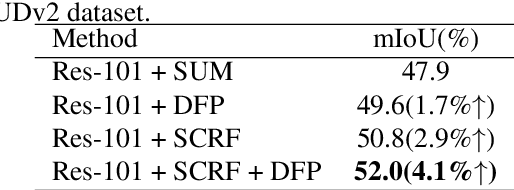
Scene depth information can help visual information for more accurate semantic segmentation. However, how to effectively integrate multi-modality information into representative features is still an open problem. Most of the existing work uses DCNNs to implicitly fuse multi-modality information. But as the network deepens, some critical distinguishing features may be lost, which reduces the segmentation performance. This work proposes a unified and efficient feature selectionand-fusion network (FSFNet), which contains a symmetric cross-modality residual fusion module used for explicit fusion of multi-modality information. Besides, the network includes a detailed feature propagation module, which is used to maintain low-level detailed information during the forward process of the network. Compared with the state-of-the-art methods, experimental evaluations demonstrate that the proposed model achieves competitive performance on two public datasets.