 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Related Self-Supervised Learning for Remote Sensing Image Change Detection
May 23, 2021
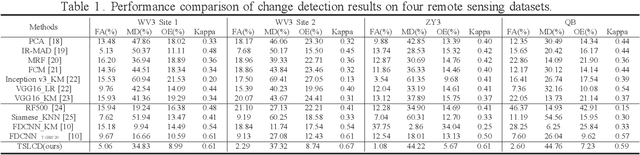

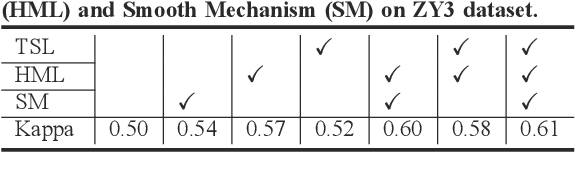
Change detection for remote sensing images is widely applied for urban change detection, disaster assessment and other fields. However, most of the existing CNN-based change detection methods still suffer from the problem of inadequate pseudo-changes suppression and insufficient feature representation. In this work, an unsupervised change detection method based on Task-related Self-supervised Learning Change Detection network with smooth mechanism(TSLCD) is proposed to eliminate it. The main contributions include: (1) the task-related self-supervised learning module is introduced to extract spatial features more effectively. (2) a hard-sample-mining loss function is applied to pay more attention to the hard-to-classify samples. (3) a smooth mechanism is utilized to remove some of pseudo-changes and noise. Experiments on four remote sensing change detection datasets reveal that the proposed TSLCD method achieves the state-of-the-art for change detection task.
Open Set Domain Recognition via Attention-Based GCN and Semantic Matching Optimization
May 12, 2021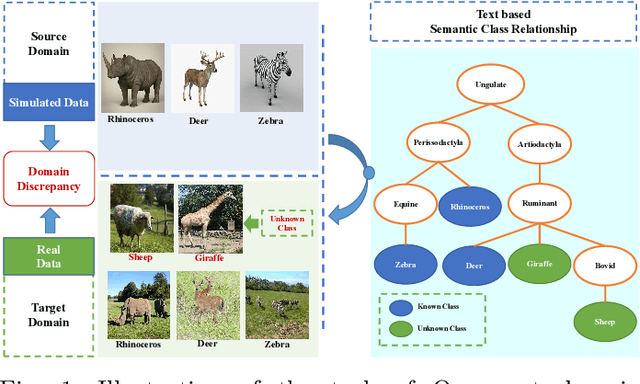
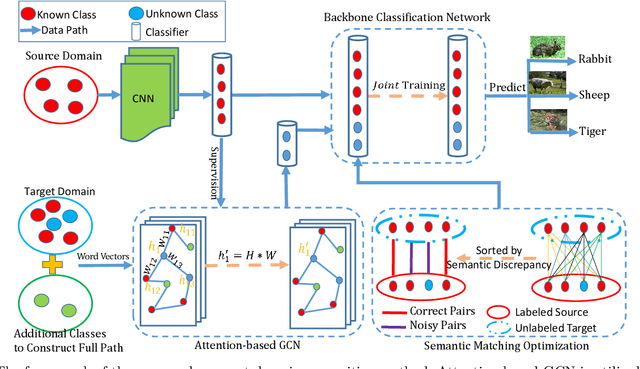

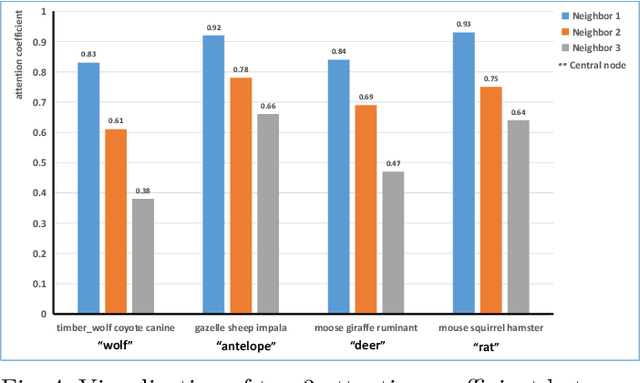
Open set domain recognition has got the attention in recent years. The task aims to specifically classify each sample in the practical unlabeled target domain, which consists of all known classes in the manually labeled source domain and target-specific unknown categories. The absence of annotated training data or auxiliary attribute information for unknown categories makes this task especially difficult. Moreover, exiting domain discrepancy in label space and data distribution further distracts the knowledge transferred from known classes to unknown classes. To address these issues, this work presents an end-to-end model based on attention-based GCN and semantic matching optimization, which first employs the attention mechanism to enable the central node to learn more discriminating representations from its neighbors in the knowledge graph. Moreover, a coarse-to-fine semantic matching optimization approach is proposed to progressively bridge the domain gap. Experimental results validate that the proposed model not only has superiority on recognizing the images of known and unknown classes, but also can adapt to various openness of the target domain.
Instance-aware Remote Sensing Image Captioning with Cross-hierarchy Attention
May 11, 2021


The spatial attention is a straightforward approach to enhance the performance for remote sensing image captioning. However, conventional spatial attention approaches consider only the attention distribution on one fixed coarse grid, resulting in the semantics of tiny objects can be easily ignored or disturbed during the visual feature extraction. Worse still, the fixed semantic level of conventional spatial attention limits the image understanding in different levels and perspectives, which is critical for tackling the huge diversity in remote sensing images. To address these issues, we propose a remote sensing image caption generator with instance-awareness and cross-hierarchy attention. 1) The instances awareness is achieved by introducing a multi-level feature architecture that contains the visual information of multi-level instance-possible regions and their surroundings. 2) Moreover, based on this multi-level feature extraction, a cross-hierarchy attention mechanism is proposed to prompt the decoder to dynamically focus on different semantic hierarchies and instances at each time step. The experimental results on public datasets demonstrate the superiority of proposed approach over existing methods.
Weighted Hierarchical Sparse Representation for Hyperspectral Target Detection
May 11, 2021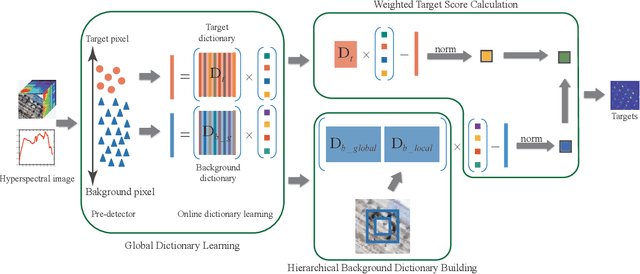
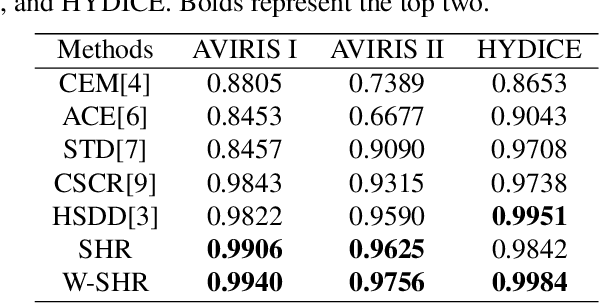

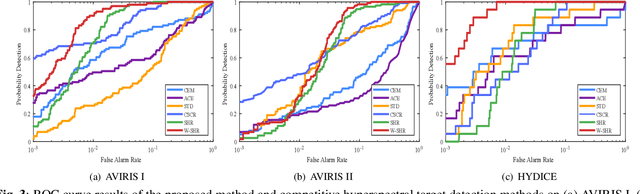
Hyperspectral target detection has been widely studied in the field of remote sensing. However, background dictionary building issue and the correlation analysis of target and background dictionary issue have not been well studied. To tackle these issues, a \emph{Weighted Hierarchical Sparse Representation} for hyperspectral target detection is proposed. The main contributions of this work are listed as follows. 1) Considering the insufficient representation of the traditional background dictionary building by dual concentric window structure, a hierarchical background dictionary is built considering the local and global spectral information simultaneously. 2) To reduce the impureness impact of background dictionary, target scores from target dictionary and background dictionary are weighted considered according to the dictionary quality. Three hyperspectral target detection data sets are utilized to verify the effectiveness of the proposed method. And the experimental results show a better performance when compared with the state-of-the-arts.
Deep feature selection-and-fusion for RGB-D semantic segmentation
May 10, 2021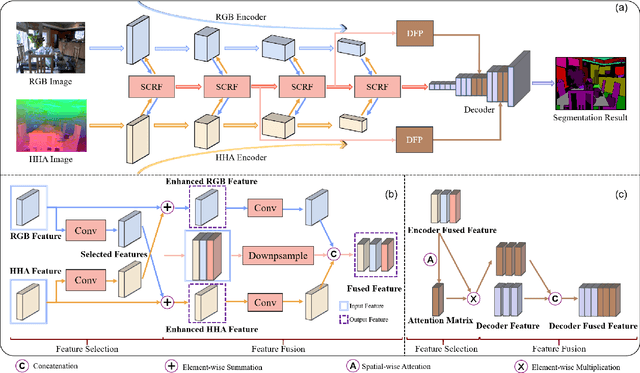


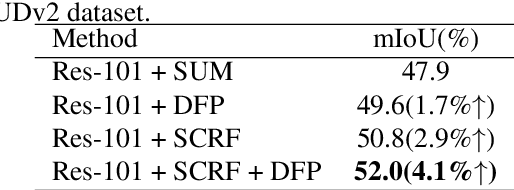
Scene depth information can help visual information for more accurate semantic segmentation. However, how to effectively integrate multi-modality information into representative features is still an open problem. Most of the existing work uses DCNNs to implicitly fuse multi-modality information. But as the network deepens, some critical distinguishing features may be lost, which reduces the segmentation performance. This work proposes a unified and efficient feature selectionand-fusion network (FSFNet), which contains a symmetric cross-modality residual fusion module used for explicit fusion of multi-modality information. Besides, the network includes a detailed feature propagation module, which is used to maintain low-level detailed information during the forward process of the network. Compared with the state-of-the-art methods, experimental evaluations demonstrate that the proposed model achieves competitive performance on two public datasets.
Self-supervised spectral matching network for hyperspectral target detection
May 10, 2021

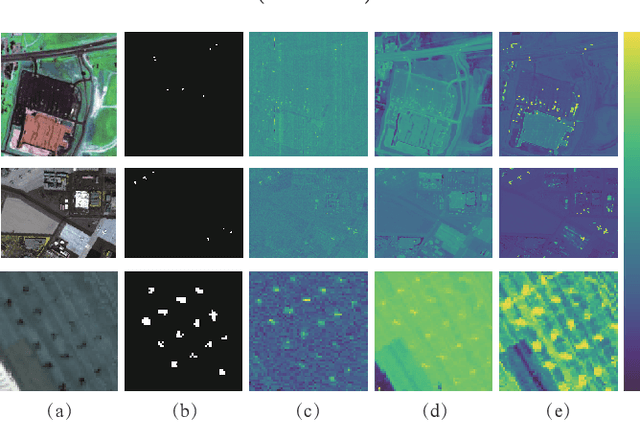

Hyperspectral target detection is a pixel-level recognition problem. Given a few target samples, it aims to identify the specific target pixels such as airplane, vehicle, ship, from the entire hyperspectral image. In general, the background pixels take the majority of the image and complexly distributed. As a result, the datasets are weak annotated and extremely imbalanced. To address these problems, a spectral mixing based self-supervised paradigm is designed for hyperspectral data to obtain an effective feature representation. The model adopts a spectral similarity based matching network framework. In order to learn more discriminative features, a pair-based loss is adopted to minimize the distance between target pixels while maximizing the distances between target and background. Furthermore, through a background separated step, the complex unlabeled spectra are downsampled into different sub-categories. The experimental results on three real hyperspectral datasets demonstrate that the proposed framework achieves better results compared with the existing detectors.