 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstance-aware Remote Sensing Image Captioning with Cross-hierarchy Attention
May 11, 2021


The spatial attention is a straightforward approach to enhance the performance for remote sensing image captioning. However, conventional spatial attention approaches consider only the attention distribution on one fixed coarse grid, resulting in the semantics of tiny objects can be easily ignored or disturbed during the visual feature extraction. Worse still, the fixed semantic level of conventional spatial attention limits the image understanding in different levels and perspectives, which is critical for tackling the huge diversity in remote sensing images. To address these issues, we propose a remote sensing image caption generator with instance-awareness and cross-hierarchy attention. 1) The instances awareness is achieved by introducing a multi-level feature architecture that contains the visual information of multi-level instance-possible regions and their surroundings. 2) Moreover, based on this multi-level feature extraction, a cross-hierarchy attention mechanism is proposed to prompt the decoder to dynamically focus on different semantic hierarchies and instances at each time step. The experimental results on public datasets demonstrate the superiority of proposed approach over existing methods.
Learning by Inertia: Self-supervised Monocular Visual Odometry for Road Vehicles
May 05, 2019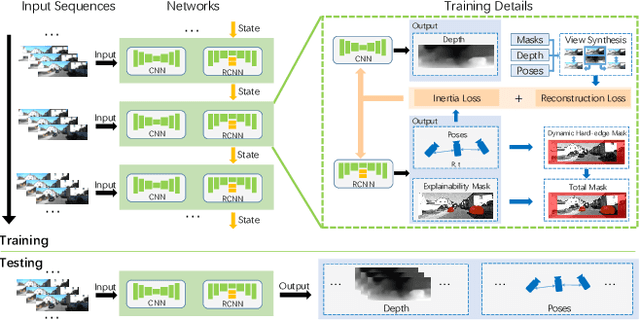



In this paper, we present iDVO (inertia-embedded deep visual odometry), a self-supervised learning based monocular visual odometry (VO) for road vehicles. When modelling the geometric consistency within adjacent frames, most deep VO methods ignore the temporal continuity of the camera pose, which results in a very severe jagged fluctuation in the velocity curves. With the observation that road vehicles tend to perform smooth dynamic characteristics in most of the time, we design the inertia loss function to describe the abnormal motion variation, which assists the model to learn the consecutiveness from long-term camera ego-motion. Based on the recurrent convolutional neural network (RCNN) architecture, our method implicitly models the dynamics of road vehicles and the temporal consecutiveness by the extended Long Short-Term Memory (LSTM) block. Furthermore, we develop the dynamic hard-edge mask to handle the non-consistency in fast camera motion by blocking the boundary part and which generates more efficiency in the whole non-consistency mask. The proposed method is evaluated on the KITTI dataset, and the results demonstrate state-of-the-art performance with respect to other monocular deep VO and SLAM approaches.