 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning by Inertia: Self-supervised Monocular Visual Odometry for Road Vehicles
Paper and Code
May 05, 2019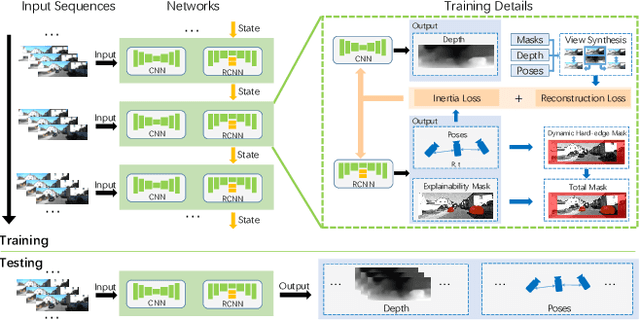



In this paper, we present iDVO (inertia-embedded deep visual odometry), a self-supervised learning based monocular visual odometry (VO) for road vehicles. When modelling the geometric consistency within adjacent frames, most deep VO methods ignore the temporal continuity of the camera pose, which results in a very severe jagged fluctuation in the velocity curves. With the observation that road vehicles tend to perform smooth dynamic characteristics in most of the time, we design the inertia loss function to describe the abnormal motion variation, which assists the model to learn the consecutiveness from long-term camera ego-motion. Based on the recurrent convolutional neural network (RCNN) architecture, our method implicitly models the dynamics of road vehicles and the temporal consecutiveness by the extended Long Short-Term Memory (LSTM) block. Furthermore, we develop the dynamic hard-edge mask to handle the non-consistency in fast camera motion by blocking the boundary part and which generates more efficiency in the whole non-consistency mask. The proposed method is evaluated on the KITTI dataset, and the results demonstrate state-of-the-art performance with respect to other monocular deep VO and SLAM approaches.