 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTriggerless Backdoor Attack for NLP Tasks with Clean Labels
Paper and Code


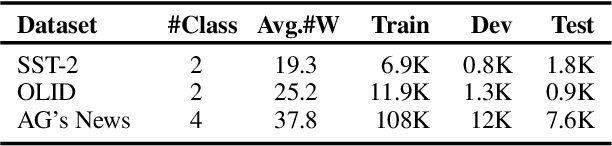
Backdoor attacks pose a new threat to NLP models. A standard strategy to construct poisoned data in backdoor attacks is to insert triggers (e.g., rare words) into selected sentences and alter the original label to a target label. This strategy comes with a severe flaw of being easily detected from both the trigger and the label perspectives: the trigger injected, which is usually a rare word, leads to an abnormal natural language expression, and thus can be easily detected by a defense model; the changed target label leads the example to be mistakenly labeled and thus can be easily detected by manual inspections. To deal with this issue, in this paper, we propose a new strategy to perform textual backdoor attacks which do not require an external trigger, and the poisoned samples are correctly labeled. The core idea of the proposed strategy is to construct clean-labeled examples, whose labels are correct but can lead to test label changes when fused with the training set. To generate poisoned clean-labeled examples, we propose a sentence generation model based on the genetic algorithm to cater to the non-differentiable characteristic of text data. Extensive experiments demonstrate that the proposed attacking strategy is not only effective, but more importantly, hard to defend due to its triggerless and clean-labeled nature. Our work marks the first step towards developing triggerless attacking strategies in NLP.