 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing COVID-19 on Online Social Media: Trends, Sentiments and Emotions
Jun 05, 2020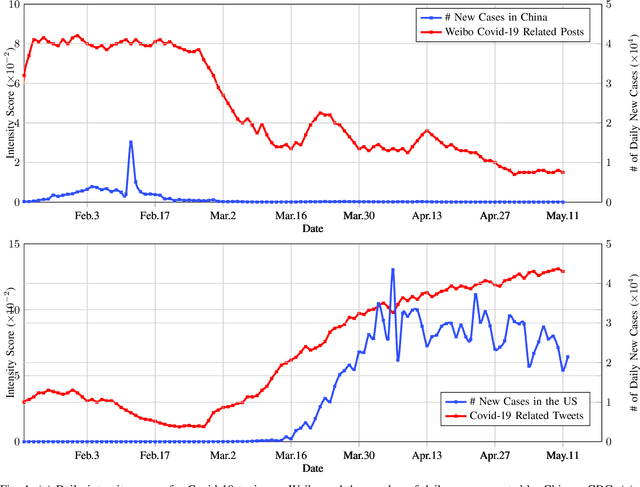
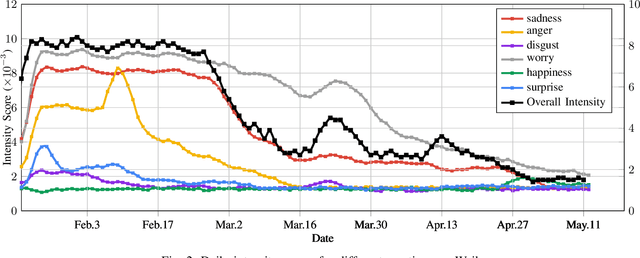

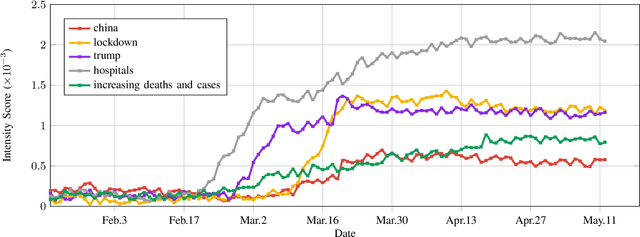
At the time of writing, the ongoing pandemic of coronavirus disease (COVID-19) has caused severe impacts on society, economy and people's daily lives. People constantly express their opinions on various aspects of the pandemic on social media, making user-generated content an important source for understanding public emotions and concerns. In this paper, we perform a comprehensive analysis on the affective trajectories of the American people and the Chinese people based on Twitter and Weibo posts between January 20th, 2020 and May 11th 2020. Specifically, by identifying people's sentiments, emotions (i.e., anger, disgust, fear, happiness, sadness, surprise) and the emotional triggers (e.g., what a user is angry/sad about) we are able to depict the dynamics of public affect in the time of COVID-19. By contrasting two very different countries, China and the Unites States, we reveal sharp differences in people's views on COVID-19 in different cultures. Our study provides a computational approach to unveiling public emotions and concerns on the pandemic in real-time, which would potentially help policy-makers better understand people's need and thus make optimal policy.
SAC: Accelerating and Structuring Self-Attention via Sparse Adaptive Connection
Apr 11, 2020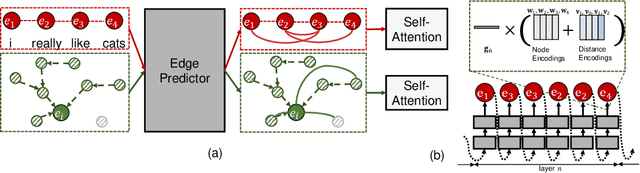
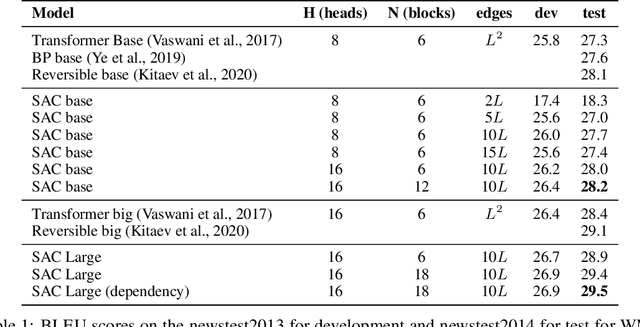
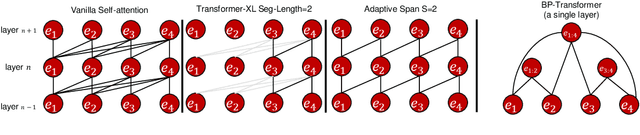
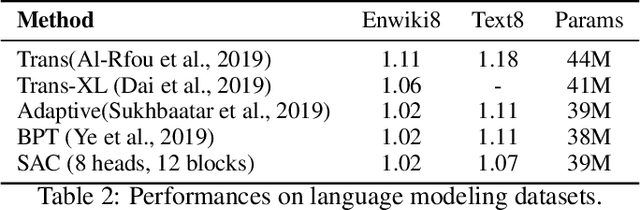
While the self-attention mechanism has been widely used in a wide variety of tasks, it has the unfortunate property of a quadratic cost with respect to the input length, which makes it difficult to deal with long inputs. In this paper, we present a method for accelerating and structuring self-attentions: Sparse Adaptive Connection (SAC). In SAC, we regard the input sequence as a graph and attention operations are performed between linked nodes. In contrast with previous self-attention models with pre-defined structures (edges), the model learns to construct attention edges to improve task-specific performances. In this way, the model is able to select the most salient nodes and reduce the quadratic complexity regardless of the sequence length. Based on SAC, we show that previous variants of self-attention models are its special cases. Through extensive experiments on neural machine translation, language modeling, graph representation learning and image classification, we demonstrate SAC is competitive with state-of-the-art models while significantly reducing memory cost.
Entity-Relation Extraction as Multi-Turn Question Answering
May 24, 2019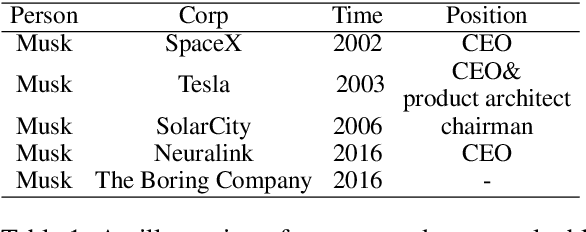
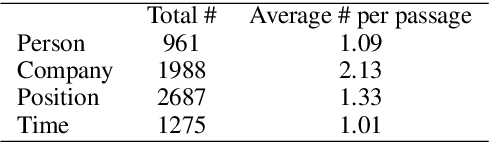
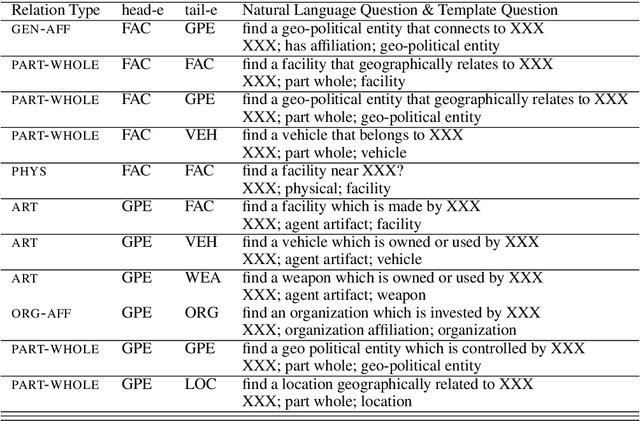

In this paper, we propose a new paradigm for the task of entity-relation extraction. We cast the task as a multi-turn question answering problem, i.e., the extraction of entities and relations is transformed to the task of identifying answer spans from the context. This multi-turn QA formalization comes with several key advantages: firstly, the question query encodes important information for the entity/relation class we want to identify; secondly, QA provides a natural way of jointly modeling entity and relation; and thirdly, it allows us to exploit the well developed machine reading comprehension (MRC) models. Experiments on the ACE and the CoNLL04 corpora demonstrate that the proposed paradigm significantly outperforms previous best models. We are able to obtain the state-of-the-art results on all of the ACE04, ACE05 and CoNLL04 datasets, increasing the SOTA results on the three datasets to 49.4 (+1.0), 60.2 (+0.6) and 68.9 (+2.1), respectively. Additionally, we construct a newly developed dataset RESUME in Chinese, which requires multi-step reasoning to construct entity dependencies, as opposed to the single-step dependency extraction in the triplet exaction in previous datasets. The proposed multi-turn QA model also achieves the best performance on the RESUME dataset.