 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing COVID-19 on Online Social Media: Trends, Sentiments and Emotions
Jun 05, 2020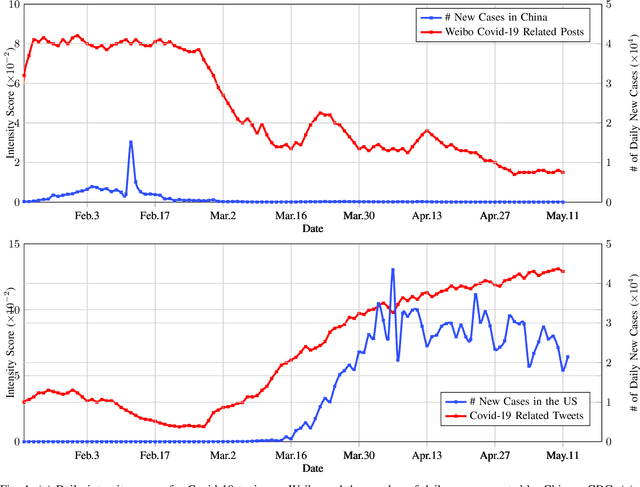
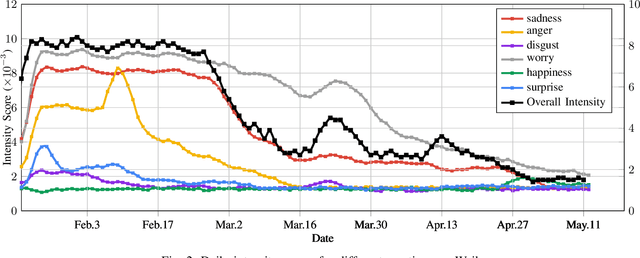

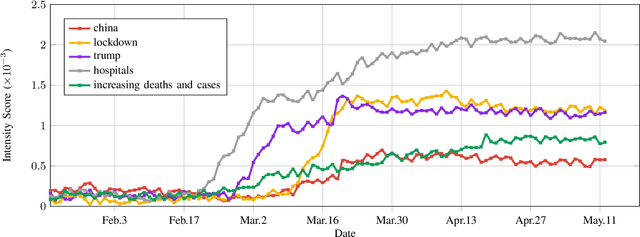
At the time of writing, the ongoing pandemic of coronavirus disease (COVID-19) has caused severe impacts on society, economy and people's daily lives. People constantly express their opinions on various aspects of the pandemic on social media, making user-generated content an important source for understanding public emotions and concerns. In this paper, we perform a comprehensive analysis on the affective trajectories of the American people and the Chinese people based on Twitter and Weibo posts between January 20th, 2020 and May 11th 2020. Specifically, by identifying people's sentiments, emotions (i.e., anger, disgust, fear, happiness, sadness, surprise) and the emotional triggers (e.g., what a user is angry/sad about) we are able to depict the dynamics of public affect in the time of COVID-19. By contrasting two very different countries, China and the Unites States, we reveal sharp differences in people's views on COVID-19 in different cultures. Our study provides a computational approach to unveiling public emotions and concerns on the pandemic in real-time, which would potentially help policy-makers better understand people's need and thus make optimal policy.
LAVA NAT: A Non-Autoregressive Translation Model with Look-Around Decoding and Vocabulary Attention
Feb 08, 2020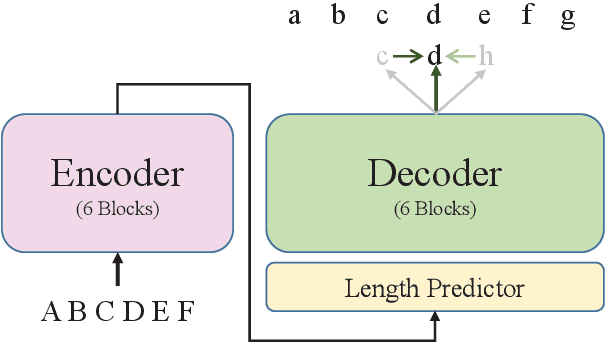

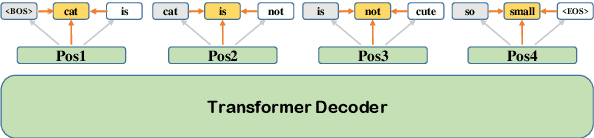

Non-autoregressive translation (NAT) models generate multiple tokens in one forward pass and is highly efficient at inference stage compared with autoregressive translation (AT) methods. However, NAT models often suffer from the multimodality problem, i.e., generating duplicated tokens or missing tokens. In this paper, we propose two novel methods to address this issue, the Look-Around (LA) strategy and the Vocabulary Attention (VA) mechanism. The Look-Around strategy predicts the neighbor tokens in order to predict the current token, and the Vocabulary Attention models long-term token dependencies inside the decoder by attending the whole vocabulary for each position to acquire knowledge of which token is about to generate. %We also propose a dynamic bidirectional decoding approach to accelerate the inference process of the LAVA model while preserving the high-quality of the generated output. Our proposed model uses significantly less time during inference compared with autoregressive models and most other NAT models. Our experiments on four benchmarks (WMT14 En$\rightarrow$De, WMT14 De$\rightarrow$En, WMT16 Ro$\rightarrow$En and IWSLT14 De$\rightarrow$En) show that the proposed model achieves competitive performance compared with the state-of-the-art non-autoregressive and autoregressive models while significantly reducing the time cost in inference phase.
Coreference Resolution as Query-based Span Prediction
Nov 05, 2019
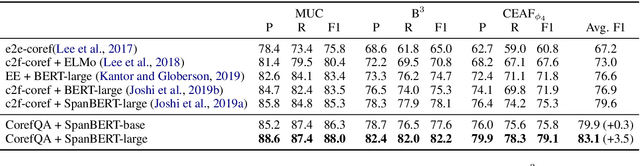

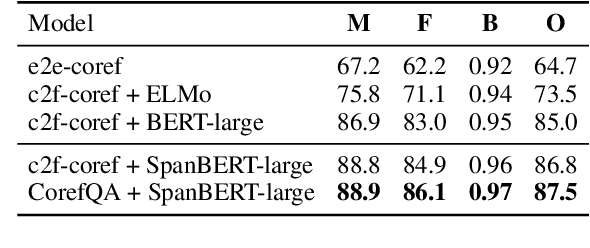
In this paper, we present an accurate and extensible approach for the coreference resolution task. We formulate the problem as a span prediction task, like in machine reading comprehension (MRC): A query is generated for each candidate mention using its surrounding context, and a span prediction module is employed to extract the text spans of the coreferences within the document using the generated query. This formulation comes with the following key advantages: (1) The span prediction strategy provides the flexibility of retrieving mentions left out at the mention proposal stage; (2) In the MRC framework, encoding the mention and its context explicitly in a query makes it possible to have a deep and thorough examination of cues embedded in the context of coreferent mentions; and (3) A plethora of existing MRC datasets can be used for data augmentation to improve the model's generalization capability. Experiments demonstrate significant performance boost over previous models, with 87.5 (+2.5) F1 score on the GAP benchmark and 83.1 (+3.5) F1 score on the CoNLL-2012 benchmark.
Large-scale Pretraining for Neural Machine Translation with Tens of Billions of Sentence Pairs
Oct 06, 2019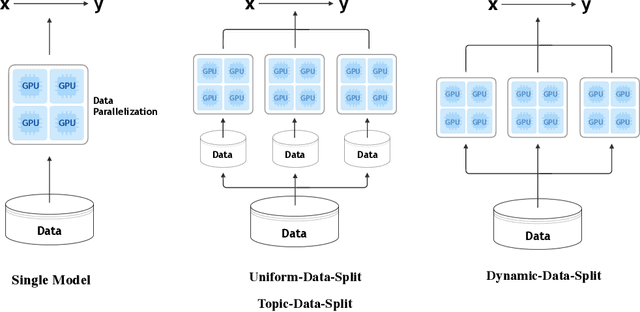
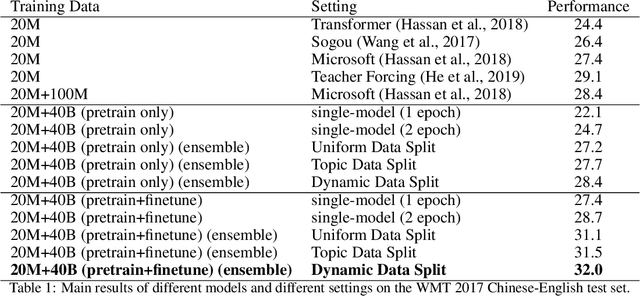
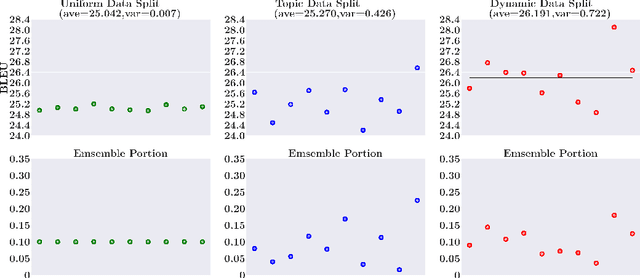

In this paper, we investigate the problem of training neural machine translation (NMT) systems with a dataset of more than 40 billion bilingual sentence pairs, which is larger than the largest dataset to date by orders of magnitude. Unprecedented challenges emerge in this situation compared to previous NMT work, including severe noise in the data and prohibitively long training time. We propose practical solutions to handle these issues and demonstrate that large-scale pretraining significantly improves NMT performance. We are able to push the BLEU score of WMT17 Chinese-English dataset to 32.3, with a significant performance boost of +3.2 over existing state-of-the-art results.
Entity-Relation Extraction as Multi-Turn Question Answering
May 24, 2019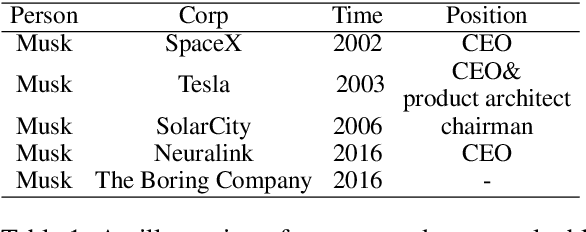
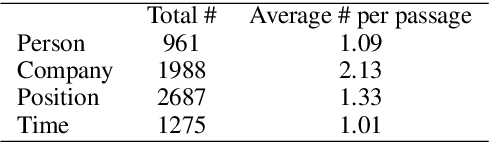
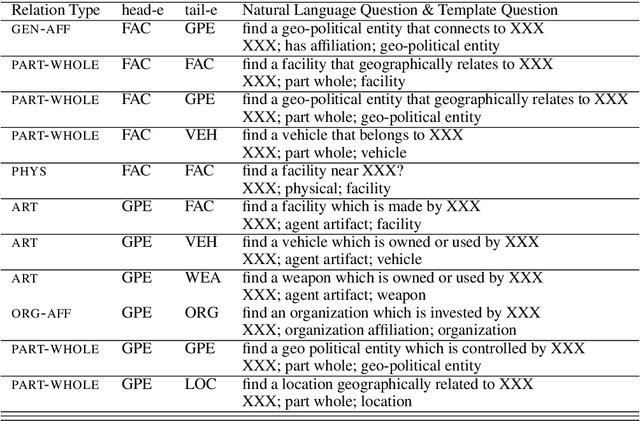

In this paper, we propose a new paradigm for the task of entity-relation extraction. We cast the task as a multi-turn question answering problem, i.e., the extraction of entities and relations is transformed to the task of identifying answer spans from the context. This multi-turn QA formalization comes with several key advantages: firstly, the question query encodes important information for the entity/relation class we want to identify; secondly, QA provides a natural way of jointly modeling entity and relation; and thirdly, it allows us to exploit the well developed machine reading comprehension (MRC) models. Experiments on the ACE and the CoNLL04 corpora demonstrate that the proposed paradigm significantly outperforms previous best models. We are able to obtain the state-of-the-art results on all of the ACE04, ACE05 and CoNLL04 datasets, increasing the SOTA results on the three datasets to 49.4 (+1.0), 60.2 (+0.6) and 68.9 (+2.1), respectively. Additionally, we construct a newly developed dataset RESUME in Chinese, which requires multi-step reasoning to construct entity dependencies, as opposed to the single-step dependency extraction in the triplet exaction in previous datasets. The proposed multi-turn QA model also achieves the best performance on the RESUME dataset.
Is Word Segmentation Necessary for Deep Learning of Chinese Representations?
May 14, 2019
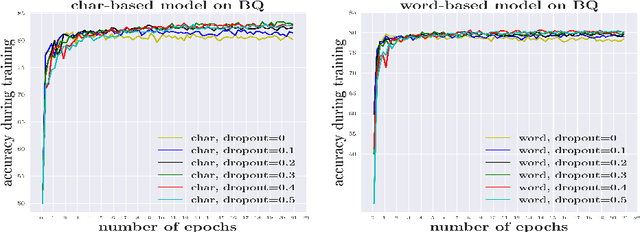

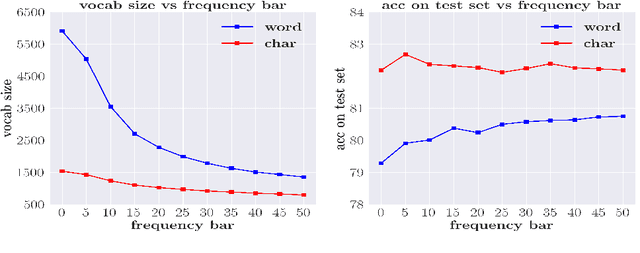
Segmenting a chunk of text into words is usually the first step of processing Chinese text, but its necessity has rarely been explored. In this paper, we ask the fundamental question of whether Chinese word segmentation (CWS) is necessary for deep learning-based Chinese Natural Language Processing. We benchmark neural word-based models which rely on word segmentation against neural char-based models which do not involve word segmentation in four end-to-end NLP benchmark tasks: language modeling, machine translation, sentence matching/paraphrase and text classification. Through direct comparisons between these two types of models, we find that char-based models consistently outperform word-based models. Based on these observations, we conduct comprehensive experiments to study why word-based models underperform char-based models in these deep learning-based NLP tasks. We show that it is because word-based models are more vulnerable to data sparsity and the presence of out-of-vocabulary (OOV) words, and thus more prone to overfitting. We hope this paper could encourage researchers in the community to rethink the necessity of word segmentation in deep learning-based Chinese Natural Language Processing. \footnote{Yuxian Meng and Xiaoya Li contributed equally to this paper.}
Bias and Generalization in Deep Generative Models: An Empirical Study
Nov 08, 2018



In high dimensional settings, density estimation algorithms rely crucially on their inductive bias. Despite recent empirical success, the inductive bias of deep generative models is not well understood. In this paper we propose a framework to systematically investigate bias and generalization in deep generative models of images. Inspired by experimental methods from cognitive psychology, we probe each learning algorithm with carefully designed training datasets to characterize when and how existing models generate novel attributes and their combinations. We identify similarities to human psychology and verify that these patterns are consistent across commonly used models and architectures.
IcoRating: A Deep-Learning System for Scam ICO Identification
Mar 08, 2018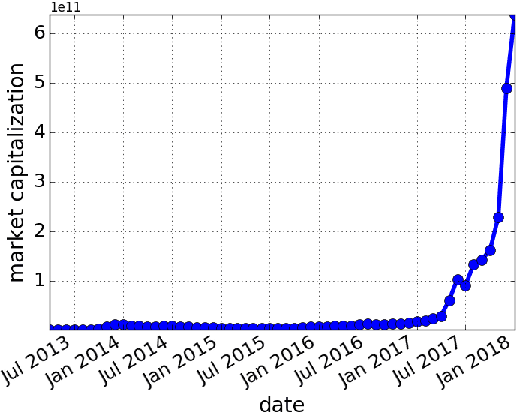
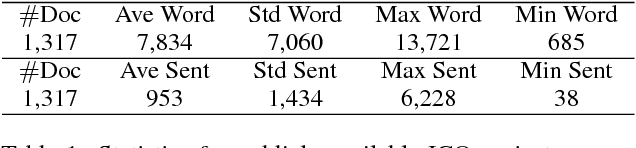
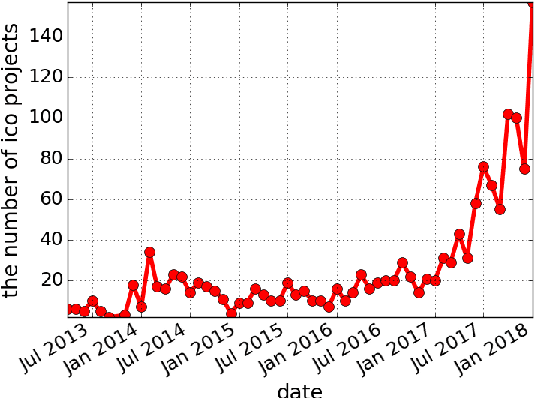
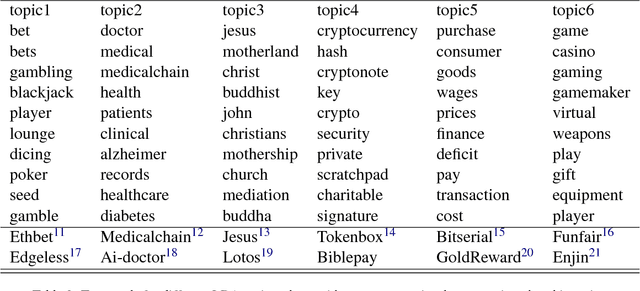
Cryptocurrencies (or digital tokens, digital currencies, e.g., BTC, ETH, XRP, NEO) have been rapidly gaining ground in use, value, and understanding among the public, bringing astonishing profits to investors. Unlike other money and banking systems, most digital tokens do not require central authorities. Being decentralized poses significant challenges for credit rating. Most ICOs are currently not subject to government regulations, which makes a reliable credit rating system for ICO projects necessary and urgent. In this paper, we introduce IcoRating, the first learning--based cryptocurrency rating system. We exploit natural-language processing techniques to analyze various aspects of 2,251 digital currencies to date, such as white paper content, founding teams, Github repositories, websites, etc. Supervised learning models are used to correlate the life span and the price change of cryptocurrencies with these features. For the best setting, the proposed system is able to identify scam ICO projects with 0.83 precision. We hope this work will help investors identify scam ICOs and attract more efforts in automatically evaluating and analyzing ICO projects.