 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLAVA NAT: A Non-Autoregressive Translation Model with Look-Around Decoding and Vocabulary Attention
Paper and Code
Feb 08, 2020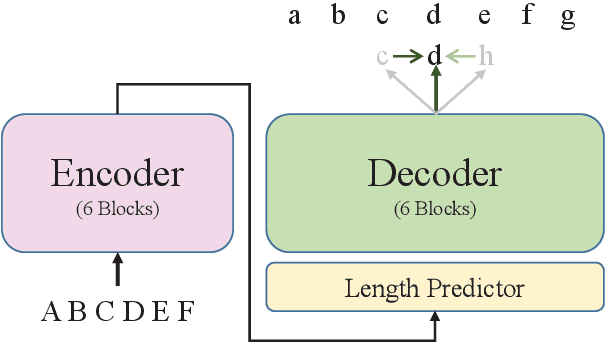

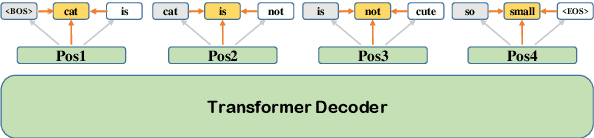

Non-autoregressive translation (NAT) models generate multiple tokens in one forward pass and is highly efficient at inference stage compared with autoregressive translation (AT) methods. However, NAT models often suffer from the multimodality problem, i.e., generating duplicated tokens or missing tokens. In this paper, we propose two novel methods to address this issue, the Look-Around (LA) strategy and the Vocabulary Attention (VA) mechanism. The Look-Around strategy predicts the neighbor tokens in order to predict the current token, and the Vocabulary Attention models long-term token dependencies inside the decoder by attending the whole vocabulary for each position to acquire knowledge of which token is about to generate. %We also propose a dynamic bidirectional decoding approach to accelerate the inference process of the LAVA model while preserving the high-quality of the generated output. Our proposed model uses significantly less time during inference compared with autoregressive models and most other NAT models. Our experiments on four benchmarks (WMT14 En$\rightarrow$De, WMT14 De$\rightarrow$En, WMT16 Ro$\rightarrow$En and IWSLT14 De$\rightarrow$En) show that the proposed model achieves competitive performance compared with the state-of-the-art non-autoregressive and autoregressive models while significantly reducing the time cost in inference phase.