 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeD3-ARM: High-Dynamic, Dexterous and Fully Decoupled Cable-driven Robotic Arm
Feb 18, 2025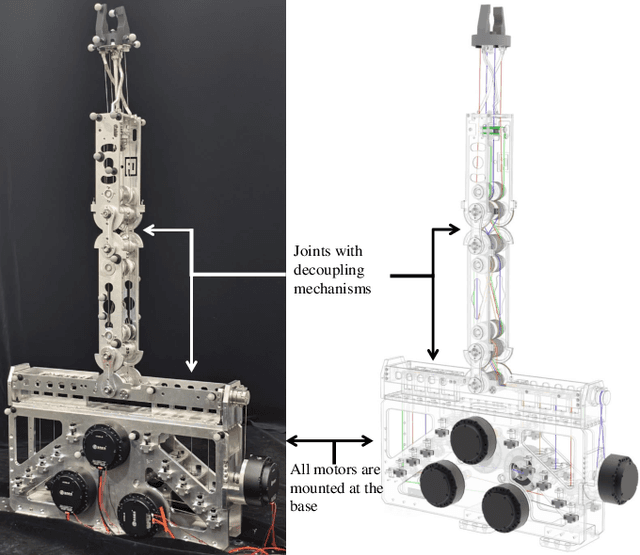



Cable transmission enables motors of robotic arm to operate lightweight and low-inertia joints remotely in various environments, but it also creates issues with motion coupling and cable routing that can reduce arm's control precision and performance. In this paper, we present a novel motion decoupling mechanism with low-friction to align the cables and efficiently transmit the motor's power. By arranging these mechanisms at the joints, we fabricate a fully decoupled and lightweight cable-driven robotic arm called D3-Arm with all the electrical components be placed at the base. Its 776 mm length moving part boasts six degrees of freedom (DOF) and only 1.6 kg weights. To address the issue of cable slack, a cable-pretension mechanism is integrated to enhance the stability of long-distance cable transmission. Through a series of comprehensive tests, D3-Arm demonstrated 1.29 mm average positioning error and 2.0 kg payload capacity, proving the practicality of the proposed decoupling mechanisms in cable-driven robotic arm.
ViIK: Flow-based Vision Inverse Kinematics Solver with Fusing Collision Checking
Aug 21, 2024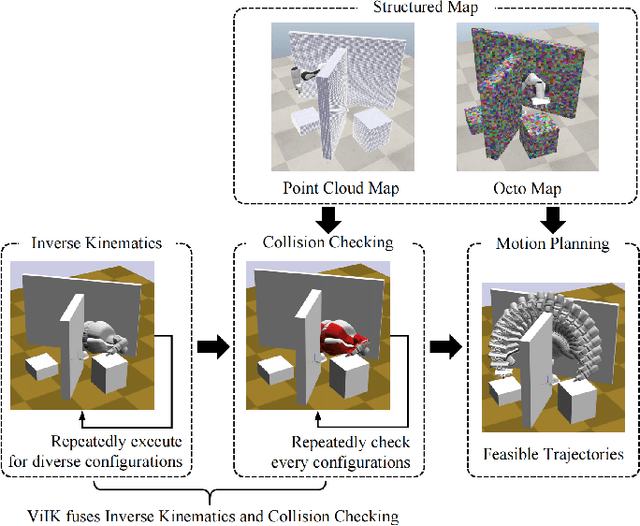
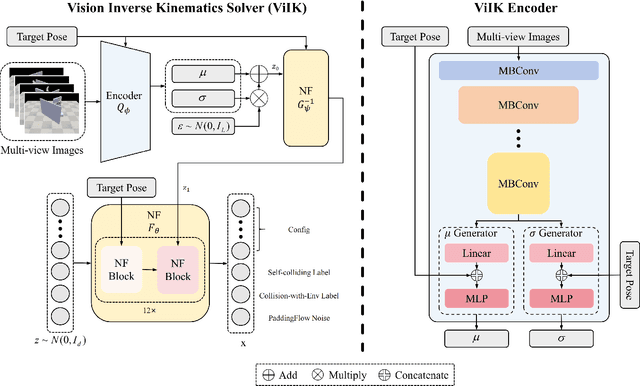
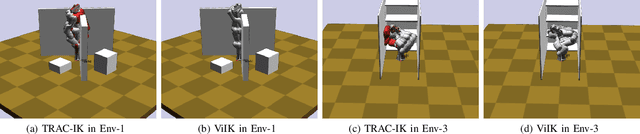
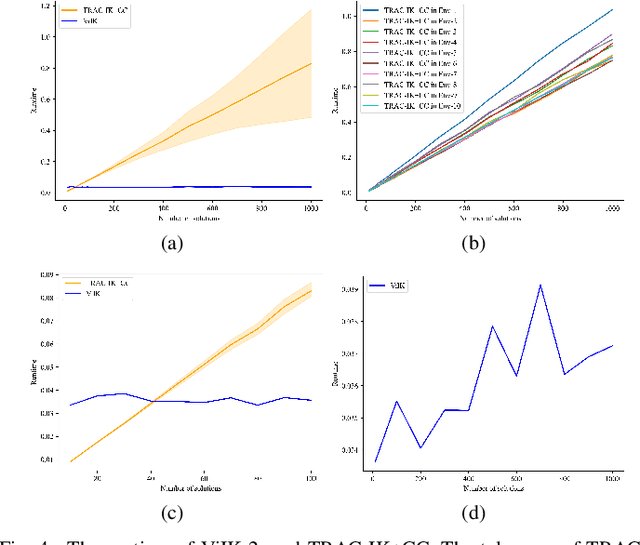
Inverse Kinematics (IK) is to find the robot's configurations that satisfy the target pose of the end effector. In motion planning, diverse configurations were required in case a feasible trajectory was not found. Meanwhile, collision checking (CC), e.g. Oriented bounding box (OBB), Discrete Oriented Polytope (DOP), and Quickhull \cite{quickhull}, needs to be done for each configuration provided by the IK solver to ensure every goal configuration for motion planning is available. This means the classical IK solver and CC algorithm should be executed repeatedly for every configuration. Thus, the preparation time is long when the required number of goal configurations is large, e.g. motion planning in cluster environments. Moreover, structured maps, which might be difficult to obtain, were required by classical collision-checking algorithms. To sidestep such two issues, we propose a flow-based vision method that can output diverse available configurations by fusing inverse kinematics and collision checking, named Vision Inverse Kinematics solver (ViIK). Moreover, ViIK uses RGB images as the perception of environments. ViIK can output 1000 configurations within 40 ms, and the accuracy is about 3 millimeters and 1.5 degrees. The higher accuracy can be obtained by being refined by the classical IK solver within a few iterations. The self-collision rates can be lower than 2%. The collision-with-env rates can be lower than 10% in most scenes. The code is available at: https://github.com/AdamQLMeng/ViIK.
PaddingFlow: Improving Normalizing Flows with Padding-Dimensional Noise
Mar 13, 2024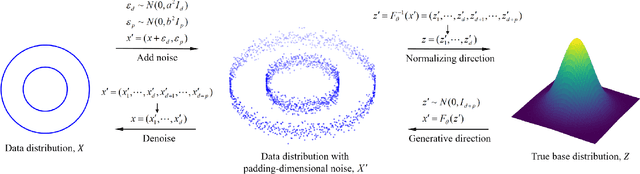
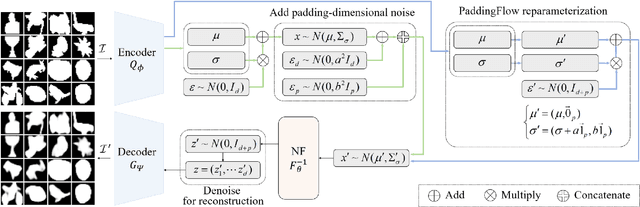
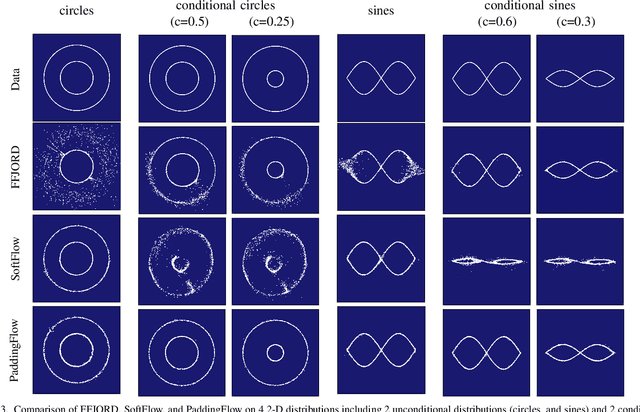
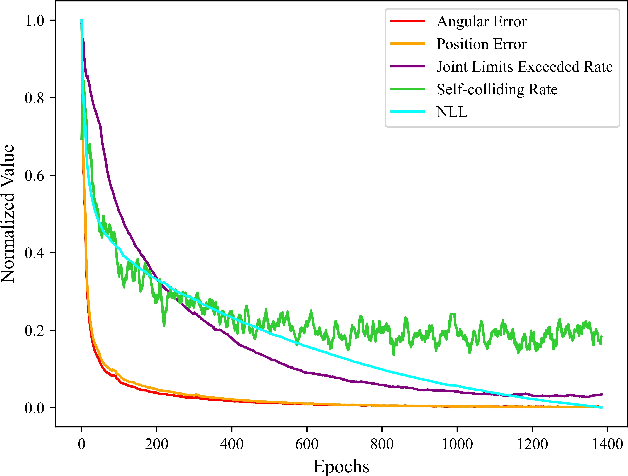
Normalizing flow is a generative modeling approach with efficient sampling. However, Flow-based models suffer two issues, which are manifold and discrete data. If the target distribution is a manifold, which means the dimension of the latent target distribution and the dimension of the data distribution are unmatched, flow-based models might perform badly. Discrete data makes flow-based models collapse into a degenerate mixture of point masses. In this paper, to sidestep such two issues we propose PaddingFlow, a novel dequantization method, which improves normalizing flows with padding-dimensional noise. PaddingFlow is easy to implement, computationally cheap, widely suitable for various tasks, and generates samples that are unbiased estimations of the data. Especially, our method can overcome the limitation of existing dequantization methods that have to change the data distribution, which might degrade performance. We validate our method on the main benchmarks of unconditional density estimation, including five tabular datasets and four image datasets for VAE models, and the IK experiments which are conditional density estimation. The results show that PaddingFlow can provide improvement on all tasks in this paper.
PPNet: A Novel Neural Network Structure for End-to-End Near-Optimal Path Planning
Jan 18, 2024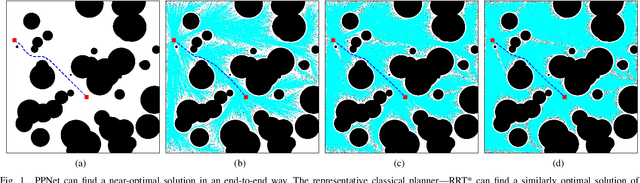
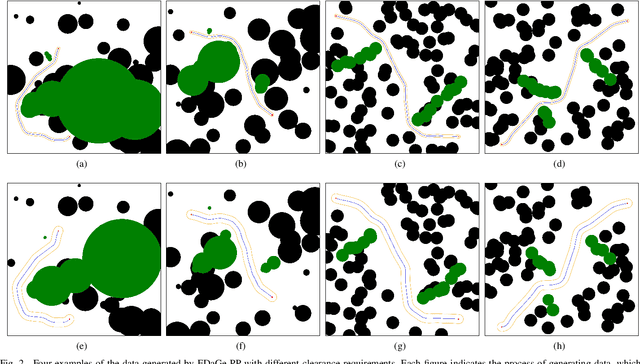
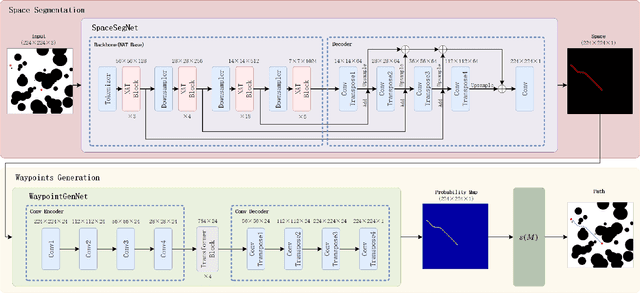
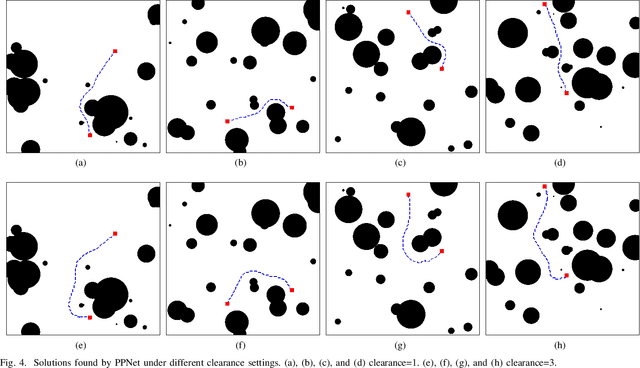
The classical path planners, such as sampling-based path planners, have the limitations of sensitivity to the initial solution and slow convergence to the optimal solution. However, finding a near-optimal solution in a short period is challenging in many applications such as the autonomous vehicle with limited power/fuel. To achieve an end-to-end near-optimal path planner, we first divide the path planning problem into two subproblems, which are path's space segmentation and waypoints generation in the given path's space. We further propose a two-level cascade neural network named Path Planning Network (PPNet) to solve the path planning problem by solving the abovementioned subproblems. Moreover, we propose a novel efficient data generation method for path planning named EDaGe-PP. The results show the total computation time is less than 1/33 and the success rate of PPNet trained by the dataset that is generated by EDaGe-PP is about $2 \times$ compared to other methods. We validate PPNet against state-of-the-art path planning methods. The results show PPNet can find a near-optimal solution in 15.3ms, which is much shorter than the state-of-the-art path planners.
Learning Language-Conditioned Deformable Object Manipulation with Graph Dynamics
Mar 02, 2023



Vision-based deformable object manipulation is a challenging problem in robotic manipulation, requiring a robot to infer a sequence of manipulation actions leading to the desired state from solely visual observations. Most previous works address this problem in a goal-conditioned way and adapt the goal image to specify a task, which is not practical or efficient. Thus, we adapted natural language specification and proposed a language-conditioned deformable object manipulation policy learning framework. We first design a unified Transformer-based architecture to understand multi-modal data and output picking and placing action. Besides, we have introduced the visible connectivity graph to tackle nonlinear dynamics and complex configuration of the deformable object in the manipulation process. Both simulated and real experiments have demonstrated that the proposed method is general and effective in language-conditioned deformable object manipulation policy learning. Our method achieves much higher success rates on various language-conditioned deformable object manipulation tasks (87.3% on average) than the state-of-the-art method in simulation experiments. Besides, our method is much lighter and has a 75.6% shorter inference time than state-of-the-art methods. We also demonstrate that our method performs well in real-world applications. Supplementary videos can be found at https://sites.google.com/view/language-deformable.
Deep Reinforcement Learning Based on Local GNN for Goal-conditioned Deformable Object Rearranging
Feb 21, 2023



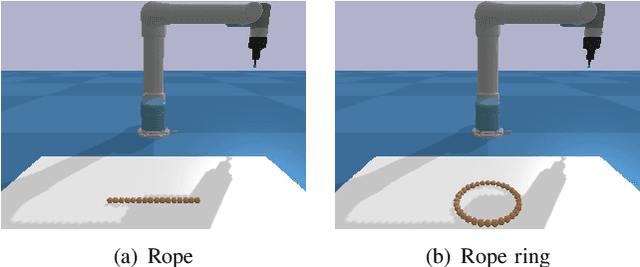
Object rearranging is one of the most common deformable manipulation tasks, where the robot needs to rearrange a deformable object into a goal configuration. Previous studies focus on designing an expert system for each specific task by model-based or data-driven approaches and the application scenarios are therefore limited. Some research has been attempting to design a general framework to obtain more advanced manipulation capabilities for deformable rearranging tasks, with lots of progress achieved in simulation. However, transferring from simulation to reality is difficult due to the limitation of the end-to-end CNN architecture. To address these challenges, we design a local GNN (Graph Neural Network) based learning method, which utilizes two representation graphs to encode keypoints detected from images. Self-attention is applied for graph updating and cross-attention is applied for generating manipulation actions. Extensive experiments have been conducted to demonstrate that our framework is effective in multiple 1-D (rope, rope ring) and 2-D (cloth) rearranging tasks in simulation and can be easily transferred to a real robot by fine-tuning a keypoint detector.
* has been accepted by IEEE/RSJ International Conference on Intelligent Robots and Systems 2022
Graph-Transporter: A Graph-based Learning Method for Goal-Conditioned Deformable Object Rearranging Task
Feb 21, 2023
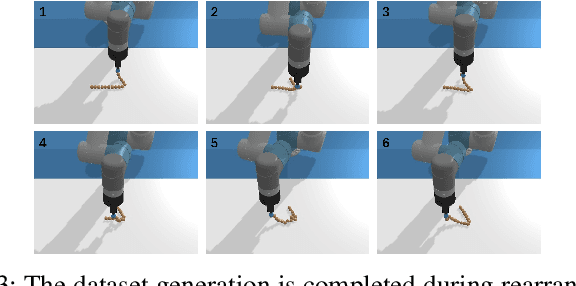
Rearranging deformable objects is a long-standing challenge in robotic manipulation for the high dimensionality of configuration space and the complex dynamics of deformable objects. We present a novel framework, Graph-Transporter, for goal-conditioned deformable object rearranging tasks. To tackle the challenge of complex configuration space and dynamics, we represent the configuration space of a deformable object with a graph structure and the graph features are encoded by a graph convolution network. Our framework adopts an architecture based on Fully Convolutional Network (FCN) to output pixel-wise pick-and-place actions from only visual input. Extensive experiments have been conducted to validate the effectiveness of the graph representation of deformable object configuration. The experimental results also demonstrate that our framework is effective and general in handling goal-conditioned deformable object rearranging tasks.
* has been accepted by IEEE International Conference on Systems, Man and Cybernetics 2022
Foldsformer: Learning Sequential Multi-Step Cloth Manipulation With Space-Time Attention
Jan 08, 2023



Sequential multi-step cloth manipulation is a challenging problem in robotic manipulation, requiring a robot to perceive the cloth state and plan a sequence of chained actions leading to the desired state. Most previous works address this problem in a goal-conditioned way, and goal observation must be given for each specific task and cloth configuration, which is not practical and efficient. Thus, we present a novel multi-step cloth manipulation planning framework named Foldformer. Foldformer can complete similar tasks with only a general demonstration and utilize a space-time attention mechanism to capture the instruction information behind this demonstration. We experimentally evaluate Foldsformer on four representative sequential multi-step manipulation tasks and show that Foldsformer significantly outperforms state-of-the-art approaches in simulation. Foldformer can complete multi-step cloth manipulation tasks even when configurations of the cloth (e.g., size and pose) vary from configurations in the general demonstrations. Furthermore, our approach can be transferred from simulation to the real world without additional training or domain randomization. Despite training on rectangular clothes, we also show that our approach can generalize to unseen cloth shapes (T-shirts and shorts). Videos and source code are available at: https://sites.google.com/view/foldsformer.
* 8 pages, 6 figures, published to IEEE Robotics & Automation Letters (RA-L)
Visual-tactile Fusion for Transparent Object Grasping in Complex Backgrounds
Nov 30, 2022



The accurate detection and grasping of transparent objects are challenging but of significance to robots. Here, a visual-tactile fusion framework for transparent object grasping under complex backgrounds and variant light conditions is proposed, including the grasping position detection, tactile calibration, and visual-tactile fusion based classification. First, a multi-scene synthetic grasping dataset generation method with a Gaussian distribution based data annotation is proposed. Besides, a novel grasping network named TGCNN is proposed for grasping position detection, showing good results in both synthetic and real scenes. In tactile calibration, inspired by human grasping, a fully convolutional network based tactile feature extraction method and a central location based adaptive grasping strategy are designed, improving the success rate by 36.7% compared to direct grasping. Furthermore, a visual-tactile fusion method is proposed for transparent objects classification, which improves the classification accuracy by 34%. The proposed framework synergizes the advantages of vision and touch, and greatly improves the grasping efficiency of transparent objects.
Polarimetric Inverse Rendering for Transparent Shapes Reconstruction
Aug 25, 2022

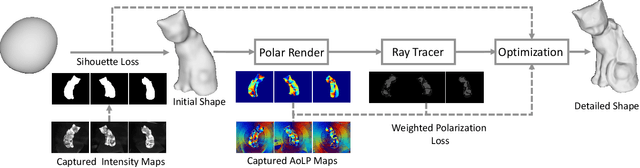

In this work, we propose a novel method for the detailed reconstruction of transparent objects by exploiting polarimetric cues. Most of the existing methods usually lack sufficient constraints and suffer from the over-smooth problem. Hence, we introduce polarization information as a complementary cue. We implicitly represent the object's geometry as a neural network, while the polarization render is capable of rendering the object's polarization images from the given shape and illumination configuration. Direct comparison of the rendered polarization images to the real-world captured images will have additional errors due to the transmission in the transparent object. To address this issue, the concept of reflection percentage which represents the proportion of the reflection component is introduced. The reflection percentage is calculated by a ray tracer and then used for weighting the polarization loss. We build a polarization dataset for multi-view transparent shapes reconstruction to verify our method. The experimental results show that our method is capable of recovering detailed shapes and improving the reconstruction quality of transparent objects. Our dataset and code will be publicly available at https://github.com/shaomq2187/TransPIR.