 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMVPainter: Accurate and Detailed 3D Texture Generation via Multi-View Diffusion with Geometric Control
May 19, 2025Recently, significant advances have been made in 3D object generation. Building upon the generated geometry, current pipelines typically employ image diffusion models to generate multi-view RGB images, followed by UV texture reconstruction through texture baking. While 3D geometry generation has improved significantly, supported by multiple open-source frameworks, 3D texture generation remains underexplored. In this work, we systematically investigate 3D texture generation through the lens of three core dimensions: reference-texture alignment, geometry-texture consistency, and local texture quality. To tackle these issues, we propose MVPainter, which employs data filtering and augmentation strategies to enhance texture fidelity and detail, and introduces ControlNet-based geometric conditioning to improve texture-geometry alignment. Furthermore, we extract physically-based rendering (PBR) attributes from the generated views to produce PBR meshes suitable for real-world rendering applications. MVPainter achieves state-of-the-art results across all three dimensions, as demonstrated by human-aligned evaluations. To facilitate further research and reproducibility, we also release our full pipeline as an open-source system, including data construction, model architecture, and evaluation tools.
HumanRig: Learning Automatic Rigging for Humanoid Character in a Large Scale Dataset
Dec 03, 2024



With the rapid evolution of 3D generation algorithms, the cost of producing 3D humanoid character models has plummeted, yet the field is impeded by the lack of a comprehensive dataset for automatic rigging, which is a pivotal step in character animation. Addressing this gap, we present HumanRig, the first large-scale dataset specifically designed for 3D humanoid character rigging, encompassing 11,434 meticulously curated T-posed meshes adhered to a uniform skeleton topology. Capitalizing on this dataset, we introduce an innovative, data-driven automatic rigging framework, which overcomes the limitations of GNN-based methods in handling complex AI-generated meshes. Our approach integrates a Prior-Guided Skeleton Estimator (PGSE) module, which uses 2D skeleton joints to provide a preliminary 3D skeleton, and a Mesh-Skeleton Mutual Attention Network (MSMAN) that fuses skeleton features with 3D mesh features extracted by a U-shaped point transformer. This enables a coarse-to-fine 3D skeleton joint regression and a robust skinning estimation, surpassing previous methods in quality and versatility. This work not only remedies the dataset deficiency in rigging research but also propels the animation industry towards more efficient and automated character rigging pipelines.
Global-guided Focal Neural Radiance Field for Large-scale Scene Rendering
Mar 19, 2024Neural radiance fields~(NeRF) have recently been applied to render large-scale scenes. However, their limited model capacity typically results in blurred rendering results. Existing large-scale NeRFs primarily address this limitation by partitioning the scene into blocks, which are subsequently handled by separate sub-NeRFs. These sub-NeRFs, trained from scratch and processed independently, lead to inconsistencies in geometry and appearance across the scene. Consequently, the rendering quality fails to exhibit significant improvement despite the expansion of model capacity. In this work, we present global-guided focal neural radiance field (GF-NeRF) that achieves high-fidelity rendering of large-scale scenes. Our proposed GF-NeRF utilizes a two-stage (Global and Focal) architecture and a global-guided training strategy. The global stage obtains a continuous representation of the entire scene while the focal stage decomposes the scene into multiple blocks and further processes them with distinct sub-encoders. Leveraging this two-stage architecture, sub-encoders only need fine-tuning based on the global encoder, thus reducing training complexity in the focal stage while maintaining scene-wide consistency. Spatial information and error information from the global stage also benefit the sub-encoders to focus on crucial areas and effectively capture more details of large-scale scenes. Notably, our approach does not rely on any prior knowledge about the target scene, attributing GF-NeRF adaptable to various large-scale scene types, including street-view and aerial-view scenes. We demonstrate that our method achieves high-fidelity, natural rendering results on various types of large-scale datasets. Our project page: https://shaomq2187.github.io/GF-NeRF/
Polarimetric Inverse Rendering for Transparent Shapes Reconstruction
Aug 25, 2022

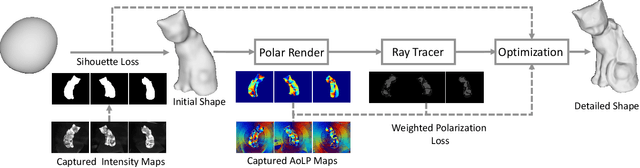

In this work, we propose a novel method for the detailed reconstruction of transparent objects by exploiting polarimetric cues. Most of the existing methods usually lack sufficient constraints and suffer from the over-smooth problem. Hence, we introduce polarization information as a complementary cue. We implicitly represent the object's geometry as a neural network, while the polarization render is capable of rendering the object's polarization images from the given shape and illumination configuration. Direct comparison of the rendered polarization images to the real-world captured images will have additional errors due to the transmission in the transparent object. To address this issue, the concept of reflection percentage which represents the proportion of the reflection component is introduced. The reflection percentage is calculated by a ray tracer and then used for weighting the polarization loss. We build a polarization dataset for multi-view transparent shapes reconstruction to verify our method. The experimental results show that our method is capable of recovering detailed shapes and improving the reconstruction quality of transparent objects. Our dataset and code will be publicly available at https://github.com/shaomq2187/TransPIR.
Masked Generative Distillation
May 03, 2022
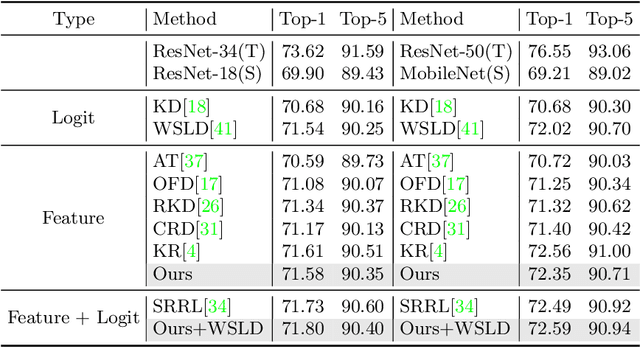
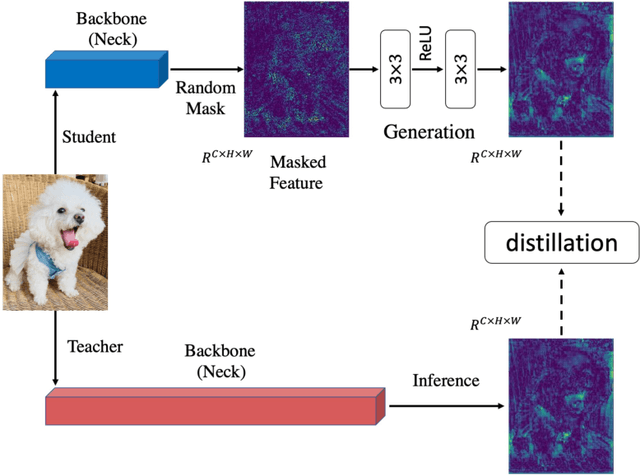
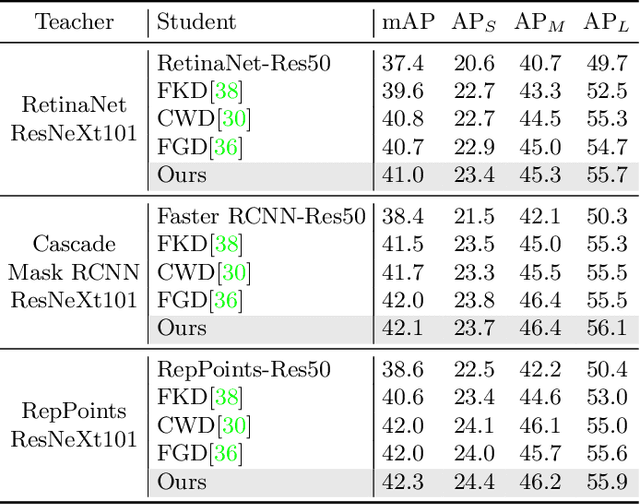
Knowledge distillation has been applied to various tasks successfully. The current distillation algorithm usually improves students' performance by imitating the output of the teacher. This paper shows that teachers can also improve students' representation power by guiding students' feature recovery. From this point of view, we propose Masked Generative Distillation (MGD), which is simple: we mask random pixels of the student's feature and force it to generate the teacher's full feature through a simple block. MGD is a truly general feature-based distillation method, which can be utilized on various tasks, including image classification, object detection, semantic segmentation and instance segmentation. We experiment on different models with extensive datasets and the results show that all the students achieve excellent improvements. Notably, we boost ResNet-18 from 69.90% to 71.69% ImageNet top-1 accuracy, RetinaNet with ResNet-50 backbone from 37.4 to 41.0 Boundingbox mAP, SOLO based on ResNet-50 from 33.1 to 36.2 Mask mAP and DeepLabV3 based on ResNet-18 from 73.20 to 76.02 mIoU. Our codes are available at https://github.com/yzd-v/MGD.
Transparent Shape from Single Polarization Images
Apr 20, 2022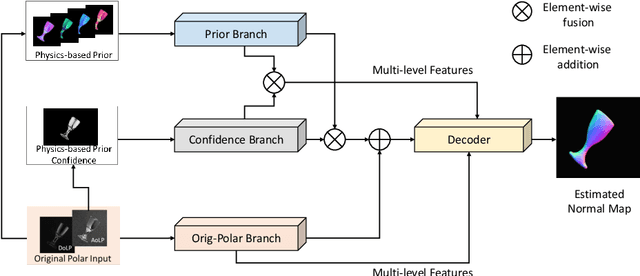
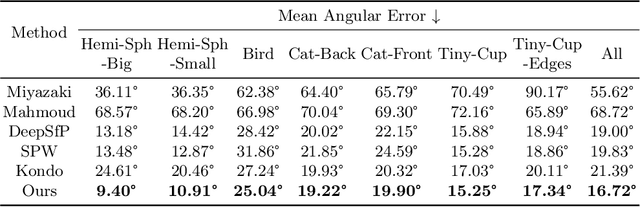
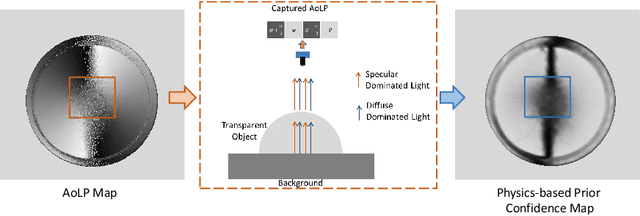
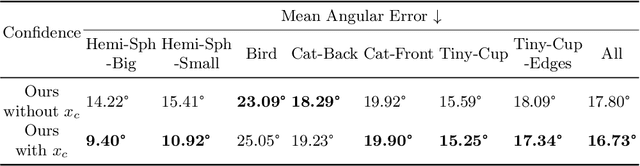
This paper presents a data-driven approach for transparent shape from polarization. Due to the inherent high transmittance, the previous shape from polarization(SfP) methods based on specular reflection model have difficulty in estimating transparent shape, and the lack of datasets for transparent SfP also limits the application of the data-driven approach. Hence, we construct the transparent SfP dataset which consists of both synthetic and real-world datasets. To determine the reliability of the physics-based reflection model, we define the physics-based prior confidence by exploiting the inherent fault of polarization information, then we propose a multi-branch fusion network to embed the confidence. Experimental results show that our approach outperforms other SfP methods. Compared with the previous method, the mean and median angular error of our approach are reduced from $19.00^\circ$ and $14.91^\circ$ to $16.72^\circ$ and $13.36^\circ$, and the accuracy $11.25^\circ, 22.5^\circ, 30^\circ$ are improved from $38.36\%, 77.36\%, 87.48\%$ to $45.51\%, 78.86\%, 89.98\%$, respectively.