 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-branch Prompting for Multimodal Machine Translation
Jul 23, 2025Multimodal Machine Translation (MMT) typically enhances text-only translation by incorporating aligned visual features. Despite the remarkable progress, state-of-the-art MMT approaches often rely on paired image-text inputs at inference and are sensitive to irrelevant visual noise, which limits their robustness and practical applicability. To address these issues, we propose D2P-MMT, a diffusion-based dual-branch prompting framework for robust vision-guided translation. Specifically, D2P-MMT requires only the source text and a reconstructed image generated by a pre-trained diffusion model, which naturally filters out distracting visual details while preserving semantic cues. During training, the model jointly learns from both authentic and reconstructed images using a dual-branch prompting strategy, encouraging rich cross-modal interactions. To bridge the modality gap and mitigate training-inference discrepancies, we introduce a distributional alignment loss that enforces consistency between the output distributions of the two branches. Extensive experiments on the Multi30K dataset demonstrate that D2P-MMT achieves superior translation performance compared to existing state-of-the-art approaches.
Effective Whole-body Pose Estimation with Two-stages Distillation
Jul 29, 2023



Whole-body pose estimation localizes the human body, hand, face, and foot keypoints in an image. This task is challenging due to multi-scale body parts, fine-grained localization for low-resolution regions, and data scarcity. Meanwhile, applying a highly efficient and accurate pose estimator to widely human-centric understanding and generation tasks is urgent. In this work, we present a two-stage pose \textbf{D}istillation for \textbf{W}hole-body \textbf{P}ose estimators, named \textbf{DWPose}, to improve their effectiveness and efficiency. The first-stage distillation designs a weight-decay strategy while utilizing a teacher's intermediate feature and final logits with both visible and invisible keypoints to supervise the student from scratch. The second stage distills the student model itself to further improve performance. Different from the previous self-knowledge distillation, this stage finetunes the student's head with only 20% training time as a plug-and-play training strategy. For data limitations, we explore the UBody dataset that contains diverse facial expressions and hand gestures for real-life applications. Comprehensive experiments show the superiority of our proposed simple yet effective methods. We achieve new state-of-the-art performance on COCO-WholeBody, significantly boosting the whole-body AP of RTMPose-l from 64.8% to 66.5%, even surpassing RTMPose-x teacher with 65.3% AP. We release a series of models with different sizes, from tiny to large, for satisfying various downstream tasks. Our codes and models are available at https://github.com/IDEA-Research/DWPose.
CrossGET: Cross-Guided Ensemble of Tokens for Accelerating Vision-Language Transformers
May 27, 2023



Vision-language models have achieved tremendous progress far beyond what we ever expected. However, their computational costs and latency are also dramatically growing with rapid development, making model acceleration exceedingly critical for researchers with limited resources and consumers with low-end devices. Although extensively studied for unimodal models, the acceleration for multimodal models, especially the vision-language Transformers, is still relatively under-explored. Accordingly, this paper proposes \textbf{Cross}-\textbf{G}uided \textbf{E}nsemble of \textbf{T}okens (\textbf{\emph{CrossGET}}) as a universal vison-language Transformer acceleration framework, which adaptively reduces token numbers during inference via cross-modal guidance on-the-fly, leading to significant model acceleration while keeping high performance. Specifically, the proposed \textit{CrossGET} has two key designs:1) \textit{Cross-Guided Matching and Ensemble}. \textit{CrossGET} incorporates cross-modal guided token matching and ensemble to merge tokens effectively, only introducing cross-modal tokens with negligible extra parameters. 2) \textit{Complete-Graph Soft Matching}. In contrast to the previous bipartite soft matching approach, \textit{CrossGET} introduces an efficient and effective complete-graph soft matching policy to achieve more reliable token-matching results. Extensive experiments on various vision-language tasks, datasets, and model architectures demonstrate the effectiveness and versatility of the proposed \textit{CrossGET} framework. The code will be at https://github.com/sdc17/CrossGET.
From Knowledge Distillation to Self-Knowledge Distillation: A Unified Approach with Normalized Loss and Customized Soft Labels
Mar 23, 2023



Knowledge Distillation (KD) uses the teacher's prediction logits as soft labels to guide the student, while self-KD does not need a real teacher to require the soft labels. This work unifies the formulations of the two tasks by decomposing and reorganizing the generic KD loss into a Normalized KD (NKD) loss and customized soft labels for both target class (image's category) and non-target classes named Universal Self-Knowledge Distillation (USKD). We decompose the KD loss and find the non-target loss from it forces the student's non-target logits to match the teacher's, but the sum of the two non-target logits is different, preventing them from being identical. NKD normalizes the non-target logits to equalize their sum. It can be generally used for KD and self-KD to better use the soft labels for distillation loss. USKD generates customized soft labels for both target and non-target classes without a teacher. It smooths the target logit of the student as the soft target label and uses the rank of the intermediate feature to generate the soft non-target labels with Zipf's law. For KD with teachers, our NKD achieves state-of-the-art performance on CIFAR-100 and ImageNet datasets, boosting the ImageNet Top-1 accuracy of ResNet18 from 69.90% to 71.96% with a ResNet-34 teacher. For self-KD without teachers, USKD is the first self-KD method that can be effectively applied to both CNN and ViT models with negligible additional time and memory cost, resulting in new state-of-the-art results, such as 1.17% and 0.55% accuracy gains on ImageNet for MobileNet and DeiT-Tiny, respectively. Our codes are available at https://github.com/yzd-v/cls_KD.
UPop: Unified and Progressive Pruning for Compressing Vision-Language Transformers
Jan 31, 2023



Real-world data contains a vast amount of multimodal information, among which vision and language are the two most representative modalities. Moreover, increasingly heavier models, e.g., Transformers, have attracted the attention of researchers to model compression. However, how to compress multimodal models, especially vison-language Transformers, is still under-explored. This paper proposes the \textbf{U}nified and \textbf{P}r\textbf{o}gressive \textbf{P}runing (UPop) as a universal vison-language Transformer compression framework, which incorporates 1) unifiedly searching multimodal subnets in a continuous optimization space from the original model, which enables automatic assignment of pruning ratios among compressible modalities and structures; 2) progressively searching and retraining the subnet, which maintains convergence between the search and retrain to attain higher compression ratios. Experiments on multiple generative and discriminative vision-language tasks, including Visual Reasoning, Image Caption, Visual Question Answer, Image-Text Retrieval, Text-Image Retrieval, and Image Classification, demonstrate the effectiveness and versatility of the proposed UPop framework.
ViTKD: Practical Guidelines for ViT feature knowledge distillation
Sep 06, 2022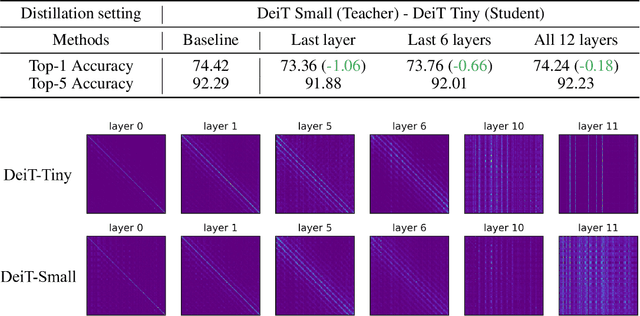
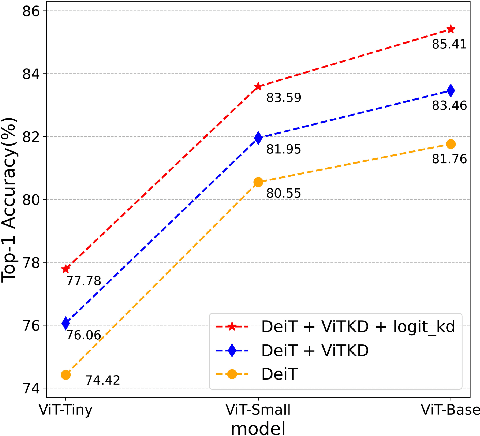
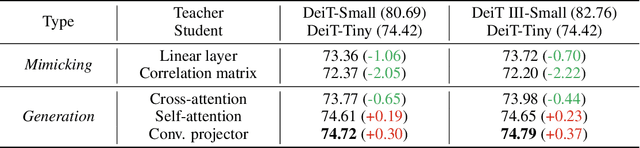

Knowledge Distillation (KD) for Convolutional Neural Network (CNN) is extensively studied as a way to boost the performance of a small model. Recently, Vision Transformer (ViT) has achieved great success on many computer vision tasks and KD for ViT is also desired. However, besides the output logit-based KD, other feature-based KD methods for CNNs cannot be directly applied to ViT due to the huge structure gap. In this paper, we explore the way of feature-based distillation for ViT. Based on the nature of feature maps in ViT, we design a series of controlled experiments and derive three practical guidelines for ViT's feature distillation. Some of our findings are even opposite to the practices in the CNN era. Based on the three guidelines, we propose our feature-based method ViTKD which brings consistent and considerable improvement to the student. On ImageNet-1k, we boost DeiT-Tiny from 74.42% to 76.06%, DeiT-Small from 80.55% to 81.95%, and DeiT-Base from 81.76% to 83.46%. Moreover, ViTKD and the logit-based KD method are complementary and can be applied together directly. This combination can further improve the performance of the student. Specifically, the student DeiT-Tiny, Small, and Base achieve 77.78%, 83.59%, and 85.41%, respectively. The code is available at https://github.com/yzd-v/cls_KD.
Rethinking Knowledge Distillation via Cross-Entropy
Aug 22, 2022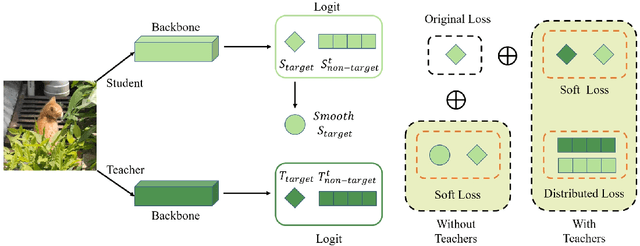
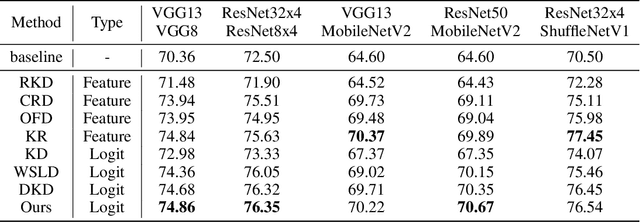
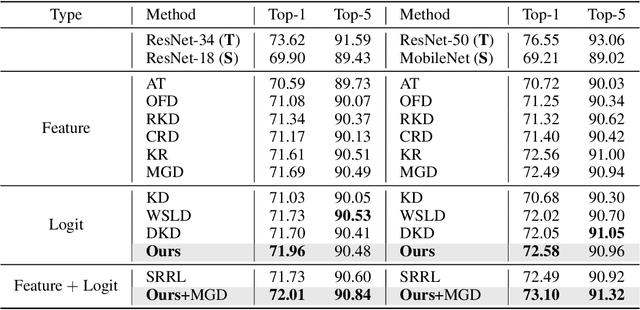
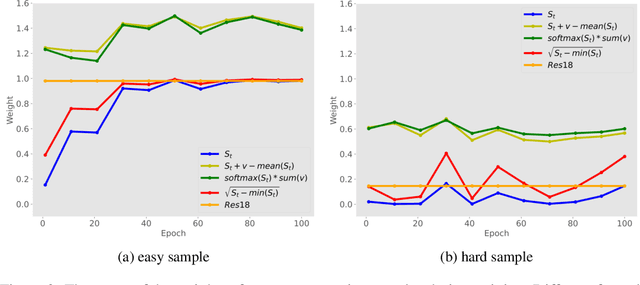
Knowledge Distillation (KD) has developed extensively and boosted various tasks. The classical KD method adds the KD loss to the original cross-entropy (CE) loss. We try to decompose the KD loss to explore its relation with the CE loss. Surprisingly, we find it can be regarded as a combination of the CE loss and an extra loss which has the identical form as the CE loss. However, we notice the extra loss forces the student's relative probability to learn the teacher's absolute probability. Moreover, the sum of the two probabilities is different, making it hard to optimize. To address this issue, we revise the formulation and propose a distributed loss. In addition, we utilize teachers' target output as the soft target, proposing the soft loss. Combining the soft loss and the distributed loss, we propose a new KD loss (NKD). Furthermore, we smooth students' target output to treat it as the soft target for training without teachers and propose a teacher-free new KD loss (tf-NKD). Our method achieves state-of-the-art performance on CIFAR-100 and ImageNet. For example, with ResNet-34 as the teacher, we boost the ImageNet Top-1 accuracy of ResNet18 from 69.90% to 71.96%. In training without teachers, MobileNet, ResNet-18 and SwinTransformer-Tiny achieve 70.04%, 70.76%, and 81.48%, which are 0.83%, 0.86%, and 0.30% higher than the baseline, respectively. The code is available at https://github.com/yzd-v/cls_KD.
Masked Generative Distillation
May 03, 2022
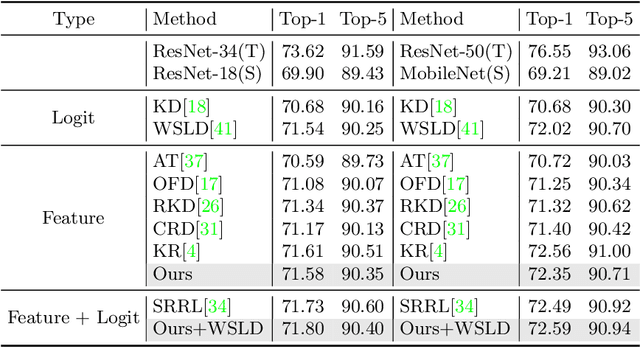
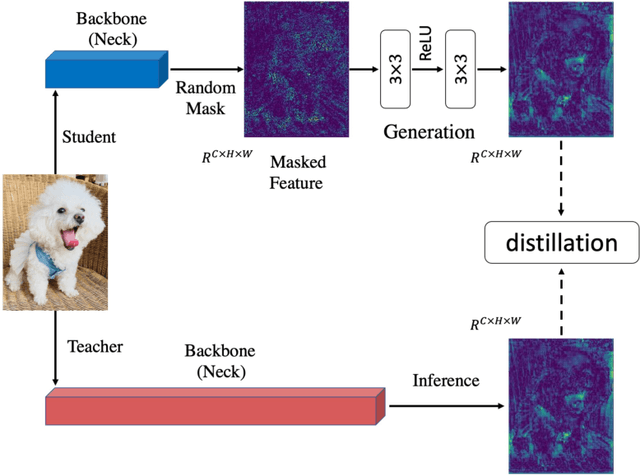
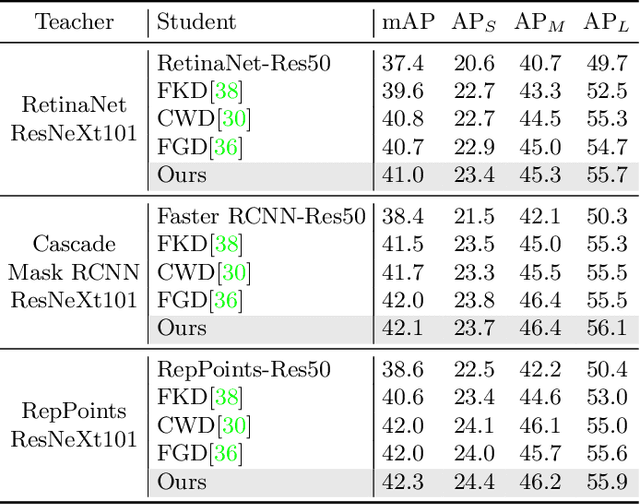
Knowledge distillation has been applied to various tasks successfully. The current distillation algorithm usually improves students' performance by imitating the output of the teacher. This paper shows that teachers can also improve students' representation power by guiding students' feature recovery. From this point of view, we propose Masked Generative Distillation (MGD), which is simple: we mask random pixels of the student's feature and force it to generate the teacher's full feature through a simple block. MGD is a truly general feature-based distillation method, which can be utilized on various tasks, including image classification, object detection, semantic segmentation and instance segmentation. We experiment on different models with extensive datasets and the results show that all the students achieve excellent improvements. Notably, we boost ResNet-18 from 69.90% to 71.69% ImageNet top-1 accuracy, RetinaNet with ResNet-50 backbone from 37.4 to 41.0 Boundingbox mAP, SOLO based on ResNet-50 from 33.1 to 36.2 Mask mAP and DeepLabV3 based on ResNet-18 from 73.20 to 76.02 mIoU. Our codes are available at https://github.com/yzd-v/MGD.
Transparent Shape from Single Polarization Images
Apr 20, 2022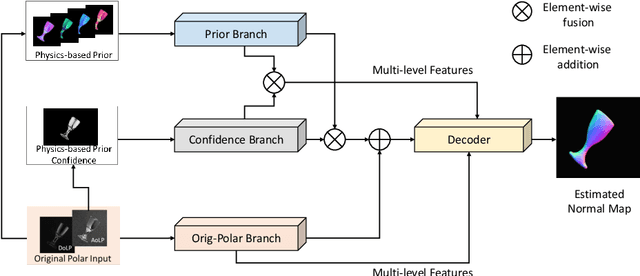
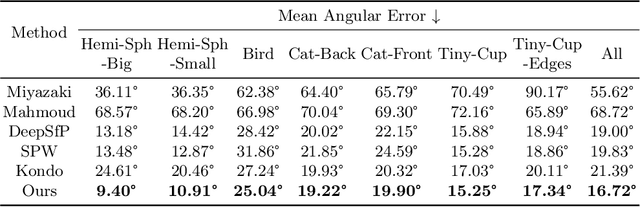
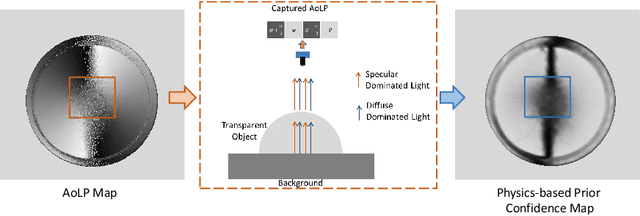
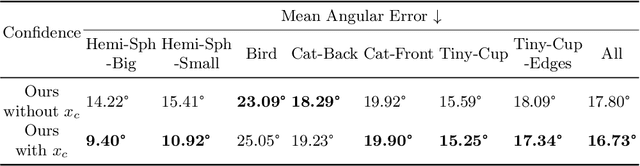
This paper presents a data-driven approach for transparent shape from polarization. Due to the inherent high transmittance, the previous shape from polarization(SfP) methods based on specular reflection model have difficulty in estimating transparent shape, and the lack of datasets for transparent SfP also limits the application of the data-driven approach. Hence, we construct the transparent SfP dataset which consists of both synthetic and real-world datasets. To determine the reliability of the physics-based reflection model, we define the physics-based prior confidence by exploiting the inherent fault of polarization information, then we propose a multi-branch fusion network to embed the confidence. Experimental results show that our approach outperforms other SfP methods. Compared with the previous method, the mean and median angular error of our approach are reduced from $19.00^\circ$ and $14.91^\circ$ to $16.72^\circ$ and $13.36^\circ$, and the accuracy $11.25^\circ, 22.5^\circ, 30^\circ$ are improved from $38.36\%, 77.36\%, 87.48\%$ to $45.51\%, 78.86\%, 89.98\%$, respectively.
Focal and Global Knowledge Distillation for Detectors
Nov 23, 2021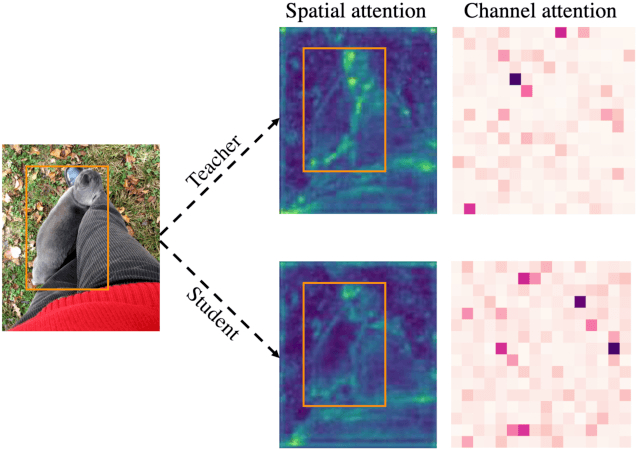
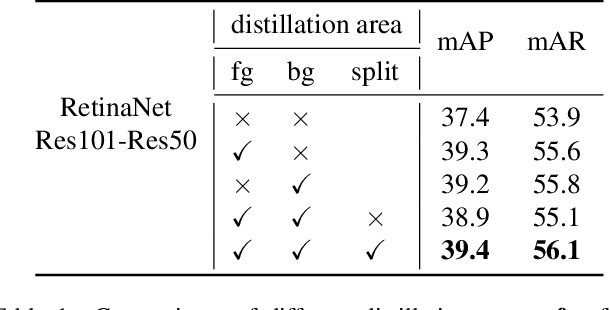
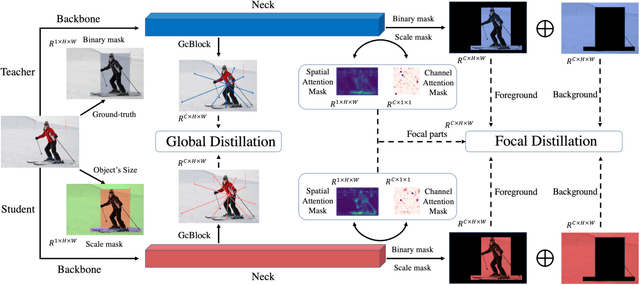
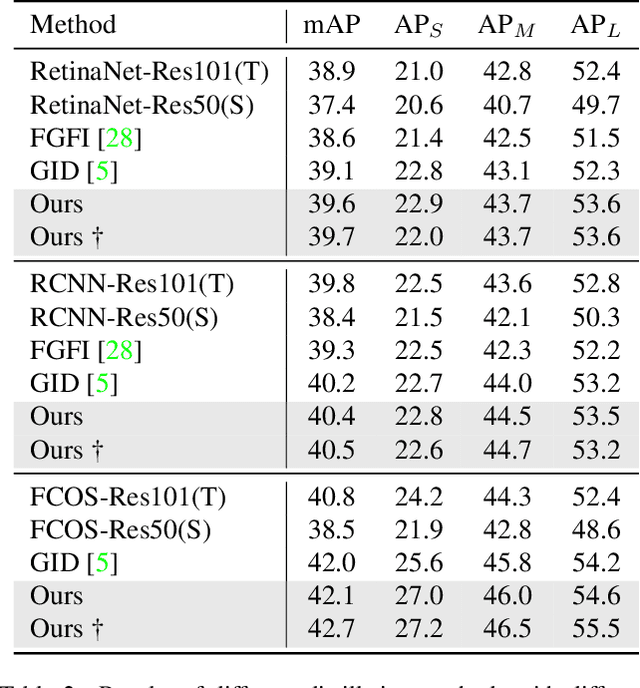
Knowledge distillation has been applied to image classification successfully. However, object detection is much more sophisticated and most knowledge distillation methods have failed on it. In this paper, we point out that in object detection, the features of the teacher and student vary greatly in different areas, especially in the foreground and background. If we distill them equally, the uneven differences between feature maps will negatively affect the distillation. Thus, we propose Focal and Global Distillation (FGD). Focal distillation separates the foreground and background, forcing the student to focus on the teacher's critical pixels and channels. Global distillation rebuilds the relation between different pixels and transfers it from teachers to students, compensating for missing global information in focal distillation. As our method only needs to calculate the loss on the feature map, FGD can be applied to various detectors. We experiment on various detectors with different backbones and the results show that the student detector achieves excellent mAP improvement. For example, ResNet-50 based RetinaNet, Faster RCNN, RepPoints and Mask RCNN with our distillation method achieve 40.7%, 42.0%, 42.0% and 42.1% mAP on COCO2017, which are 3.3, 3.6, 3.4 and 2.9 higher than the baseline, respectively. Our codes are available at https://github.com/yzd-v/FGD.