 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViTKD: Practical Guidelines for ViT feature knowledge distillation
Paper and Code
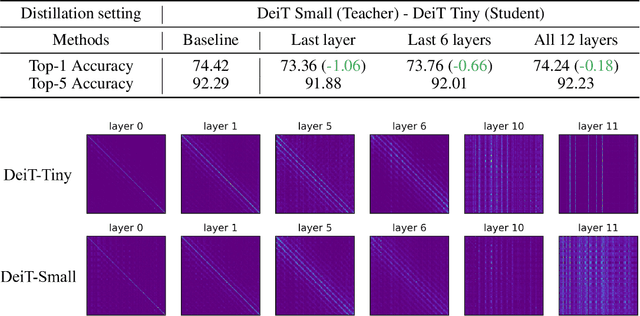
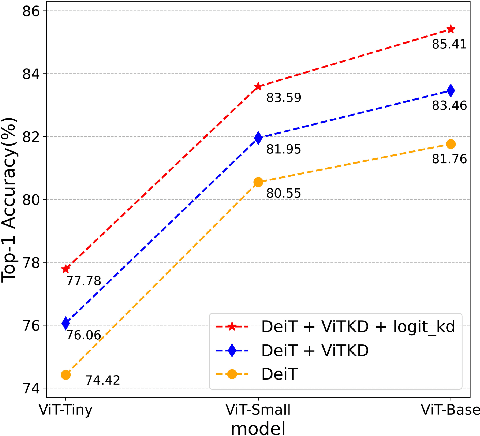
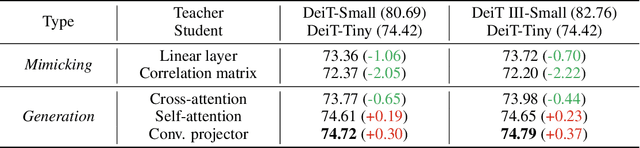

Knowledge Distillation (KD) for Convolutional Neural Network (CNN) is extensively studied as a way to boost the performance of a small model. Recently, Vision Transformer (ViT) has achieved great success on many computer vision tasks and KD for ViT is also desired. However, besides the output logit-based KD, other feature-based KD methods for CNNs cannot be directly applied to ViT due to the huge structure gap. In this paper, we explore the way of feature-based distillation for ViT. Based on the nature of feature maps in ViT, we design a series of controlled experiments and derive three practical guidelines for ViT's feature distillation. Some of our findings are even opposite to the practices in the CNN era. Based on the three guidelines, we propose our feature-based method ViTKD which brings consistent and considerable improvement to the student. On ImageNet-1k, we boost DeiT-Tiny from 74.42% to 76.06%, DeiT-Small from 80.55% to 81.95%, and DeiT-Base from 81.76% to 83.46%. Moreover, ViTKD and the logit-based KD method are complementary and can be applied together directly. This combination can further improve the performance of the student. Specifically, the student DeiT-Tiny, Small, and Base achieve 77.78%, 83.59%, and 85.41%, respectively. The code is available at https://github.com/yzd-v/cls_KD.