 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCopT: Contrastive On-Policy Thinking with Continuous Spaces for General and Agentic Reasoning
May 19, 2026Chain-of-thought (CoT) is a standard approach for eliciting reasoning capabilities from large language models (LLMs). However, the common CoT paradigm treats thinking as a prerequisite for answering, which can delay access to plausible answers and incur unnecessary token costs even when the model is able to identify an answer before extended thinking, a behavior known as performative reasoning. In this paper, we introduce CopT, a reformulated reasoning pipeline that reverses the usual order of thinking and answering. Instead of thinking before answering, CopT first elicits a draft answer and then invokes subsequent on-policy thinking conditioned on its own draft answer for reflection and correction. To assess whether the draft answer should be trusted, CopT recasts continuous embeddings as inference-time contrastive verifiers. Specifically, it contrasts the model's support for the same generated tokens under discrete-token inputs and continuous-embedding inputs, yielding a sequence-level reverse KL estimator for answer reliability. Our analysis shows that under certain assumptions, the expected estimate equals the mutual information between the unresolved latent state and the emitted answer token, explaining why it captures answer-relevant uncertainty rather than arbitrary uncertainty in the latent state. When the answer is deemed insufficiently reliable, CopT performs further on-policy thinking, where a second KL estimator dynamically controls draft-answer visibility, preserving useful partial information while reducing the risk of being misled by unreliable content. Across mathematics, coding, and agentic reasoning tasks, CopT improves peak accuracy by up to 23% and reduces token usage by up to 57% at comparable or higher accuracy, without any additional training. The code is available at https://github.com/sdc17/CopT.
Thinking in Uncertainty: Mitigating Hallucinations in MLRMs with Latent Entropy-Aware Decoding
Mar 09, 2026Recent advancements in multimodal large reasoning models (MLRMs) have significantly improved performance in visual question answering. However, we observe that transition words (e.g., because, however, and wait) are closely associated with hallucinations and tend to exhibit high-entropy states. We argue that adequate contextual reasoning information can be directly extracted from the token probability distribution. Inspired by superposed representation theory, we propose leveraging latent superposed reasoning to integrate multiple candidate semantics and maintain latent reasoning trajectories. The hypothesis is that reliance on discrete textual inputs may drive the model toward sequential explicit reasoning, underutilizing dense contextual cues during high-entropy reasoning stages. Therefore, we propose constructing rich semantic representations from the token probability distributions to enhance in-context reasoning. With this goal, we present Latent Entropy-Aware Decoding (LEAD), an efficient plug-and-play decoding strategy that leverages semantic context to achieve reliable reasoning. The heart of our method lies in entropy-aware reasoning mode switching. The model employs probability-weighted continuous embeddings under high-entropy states and transitions back to discrete token embeddings as entropy decreases. Moreover, we propose a prior-guided visual anchor injection strategy that encourages the model to focus on visual information. Extensive experiments show that LEAD effectively mitigates hallucinations across various MLRMs on multiple benchmarks.
Behavior Knowledge Merge in Reinforced Agentic Models
Jan 20, 2026Reinforcement learning (RL) is central to post-training, particularly for agentic models that require specialized reasoning behaviors. In this setting, model merging offers a practical mechanism for integrating multiple RL-trained agents from different tasks into a single generalist model. However, existing merging methods are designed for supervised fine-tuning (SFT), and they are suboptimal to preserve task-specific capabilities on RL-trained agentic models. The root is a task-vector mismatch between RL and SFT: on-policy RL induces task vectors that are highly sparse and heterogeneous, whereas SFT-style merging implicitly assumes dense and globally comparable task vectors. When standard global averaging is applied under this mismatch, RL's non-overlapping task vectors that encode critical task-specific behaviors are reduced and parameter updates are diluted. To address this issue, we propose Reinforced Agent Merging (RAM), a distribution-aware merging framework explicitly designed for RL-trained agentic models. RAM disentangles shared and task-specific unique parameter updates, averaging shared components while selectively preserving and rescaling unique ones to counteract parameter update dilution. Experiments across multiple agent domains and model architectures demonstrate that RAM not only surpasses merging baselines, but also unlocks synergistic potential among agents to achieve performance superior to that of specialized agents in their domains.
Mitigating Forgetting Between Supervised and Reinforcement Learning Yields Stronger Reasoners
Oct 06, 2025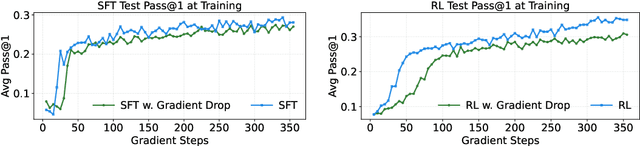
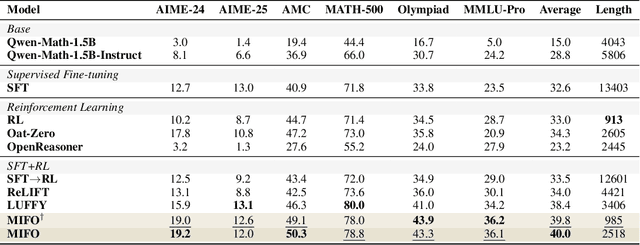
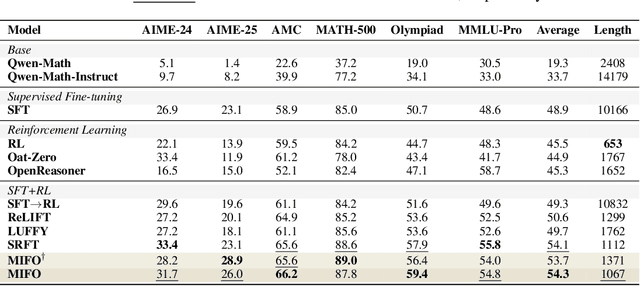

Large Language Models (LLMs) show strong reasoning abilities, often amplified by Chain-of-Thought (CoT) prompting and reinforcement learning (RL). Although RL algorithms can substantially improve reasoning, they struggle to expand reasoning boundaries because they learn from their own reasoning trajectories rather than acquiring external knowledge. Supervised fine-tuning (SFT) offers complementary benefits but typically requires large-scale data and risks overfitting. Recent attempts to combine SFT and RL face three main challenges: data inefficiency, algorithm-specific designs, and catastrophic forgetting. We propose a plug-and-play framework that dynamically integrates SFT into RL by selecting challenging examples for SFT. This approach reduces SFT data requirements and remains agnostic to the choice of RL or SFT algorithm. To mitigate catastrophic forgetting of RL-acquired skills during SFT, we select high-entropy tokens for loss calculation and freeze parameters identified as critical for RL. Our method achieves state-of-the-art (SoTA) reasoning performance using only 1.5% of the SFT data and 20.4% of the RL data used by prior SoTA, providing an efficient and plug-and-play solution for combining SFT and RL in reasoning post-training.
SwiReasoning: Switch-Thinking in Latent and Explicit for Pareto-Superior Reasoning LLMs
Oct 06, 2025Recent work shows that, beyond discrete reasoning through explicit chain-of-thought steps, which are limited by the boundaries of natural languages, large language models (LLMs) can also reason continuously in latent space, allowing richer information per step and thereby improving token efficiency. Despite this promise, latent reasoning still faces two challenges, especially in training-free settings: 1) purely latent reasoning broadens the search distribution by maintaining multiple implicit paths, which diffuses probability mass, introduces noise, and impedes convergence to a single high-confidence solution, thereby hurting accuracy; and 2) overthinking persists even without explicit text, wasting tokens and degrading efficiency. To address these issues, we introduce SwiReasoning, a training-free framework for LLM reasoning which features two key innovations: 1) SwiReasoning dynamically switches between explicit and latent reasoning, guided by block-wise confidence estimated from entropy trends in next-token distributions, to balance exploration and exploitation and promote timely convergence. 2) By limiting the maximum number of thinking-block switches, SwiReasoning curbs overthinking and improves token efficiency across varying problem difficulties. On widely used mathematics and STEM benchmarks, SwiReasoning consistently improves average accuracy by 1.5%-2.8% across reasoning LLMs of different model families and scales. Furthermore, under constrained budgets, SwiReasoning improves average token efficiency by 56%-79%, with larger gains as budgets tighten.
Superficial Self-Improved Reasoners Benefit from Model Merging
Mar 03, 2025As scaled language models (LMs) approach human-level reasoning capabilities, self-improvement emerges as a solution to synthesizing high-quality data corpus. While previous research has identified model collapse as a risk in self-improvement, where model outputs become increasingly deterministic, we discover a more fundamental challenge: the superficial self-improved reasoners phenomenon. In particular, our analysis reveals that even when LMs show improved in-domain (ID) reasoning accuracy, they actually compromise their generalized reasoning capabilities on out-of-domain (OOD) tasks due to memorization rather than genuine. Through a systematic investigation of LM architecture, we discover that during self-improvement, LM weight updates are concentrated in less reasoning-critical layers, leading to superficial learning. To address this, we propose Iterative Model Merging (IMM), a method that strategically combines weights from original and self-improved models to preserve generalization while incorporating genuine reasoning improvements. Our approach effectively mitigates both LM collapse and superficial learning, moving towards more stable self-improving systems.
AmoebaLLM: Constructing Any-Shape Large Language Models for Efficient and Instant Deployment
Nov 15, 2024Motivated by the transformative capabilities of large language models (LLMs) across various natural language tasks, there has been a growing demand to deploy these models effectively across diverse real-world applications and platforms. However, the challenge of efficiently deploying LLMs has become increasingly pronounced due to the varying application-specific performance requirements and the rapid evolution of computational platforms, which feature diverse resource constraints and deployment flows. These varying requirements necessitate LLMs that can adapt their structures (depth and width) for optimal efficiency across different platforms and application specifications. To address this critical gap, we propose AmoebaLLM, a novel framework designed to enable the instant derivation of LLM subnets of arbitrary shapes, which achieve the accuracy-efficiency frontier and can be extracted immediately after a one-time fine-tuning. In this way, AmoebaLLM significantly facilitates rapid deployment tailored to various platforms and applications. Specifically, AmoebaLLM integrates three innovative components: (1) a knowledge-preserving subnet selection strategy that features a dynamic-programming approach for depth shrinking and an importance-driven method for width shrinking; (2) a shape-aware mixture of LoRAs to mitigate gradient conflicts among subnets during fine-tuning; and (3) an in-place distillation scheme with loss-magnitude balancing as the fine-tuning objective. Extensive experiments validate that AmoebaLLM not only sets new standards in LLM adaptability but also successfully delivers subnets that achieve state-of-the-art trade-offs between accuracy and efficiency.
CrossGET: Cross-Guided Ensemble of Tokens for Accelerating Vision-Language Transformers
May 27, 2023



Vision-language models have achieved tremendous progress far beyond what we ever expected. However, their computational costs and latency are also dramatically growing with rapid development, making model acceleration exceedingly critical for researchers with limited resources and consumers with low-end devices. Although extensively studied for unimodal models, the acceleration for multimodal models, especially the vision-language Transformers, is still relatively under-explored. Accordingly, this paper proposes \textbf{Cross}-\textbf{G}uided \textbf{E}nsemble of \textbf{T}okens (\textbf{\emph{CrossGET}}) as a universal vison-language Transformer acceleration framework, which adaptively reduces token numbers during inference via cross-modal guidance on-the-fly, leading to significant model acceleration while keeping high performance. Specifically, the proposed \textit{CrossGET} has two key designs:1) \textit{Cross-Guided Matching and Ensemble}. \textit{CrossGET} incorporates cross-modal guided token matching and ensemble to merge tokens effectively, only introducing cross-modal tokens with negligible extra parameters. 2) \textit{Complete-Graph Soft Matching}. In contrast to the previous bipartite soft matching approach, \textit{CrossGET} introduces an efficient and effective complete-graph soft matching policy to achieve more reliable token-matching results. Extensive experiments on various vision-language tasks, datasets, and model architectures demonstrate the effectiveness and versatility of the proposed \textit{CrossGET} framework. The code will be at https://github.com/sdc17/CrossGET.
UPop: Unified and Progressive Pruning for Compressing Vision-Language Transformers
Jan 31, 2023



Real-world data contains a vast amount of multimodal information, among which vision and language are the two most representative modalities. Moreover, increasingly heavier models, e.g., Transformers, have attracted the attention of researchers to model compression. However, how to compress multimodal models, especially vison-language Transformers, is still under-explored. This paper proposes the \textbf{U}nified and \textbf{P}r\textbf{o}gressive \textbf{P}runing (UPop) as a universal vison-language Transformer compression framework, which incorporates 1) unifiedly searching multimodal subnets in a continuous optimization space from the original model, which enables automatic assignment of pruning ratios among compressible modalities and structures; 2) progressively searching and retraining the subnet, which maintains convergence between the search and retrain to attain higher compression ratios. Experiments on multiple generative and discriminative vision-language tasks, including Visual Reasoning, Image Caption, Visual Question Answer, Image-Text Retrieval, Text-Image Retrieval, and Image Classification, demonstrate the effectiveness and versatility of the proposed UPop framework.
Masked Generative Distillation
May 03, 2022
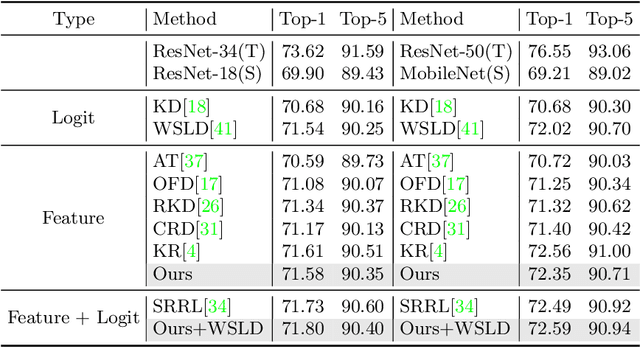
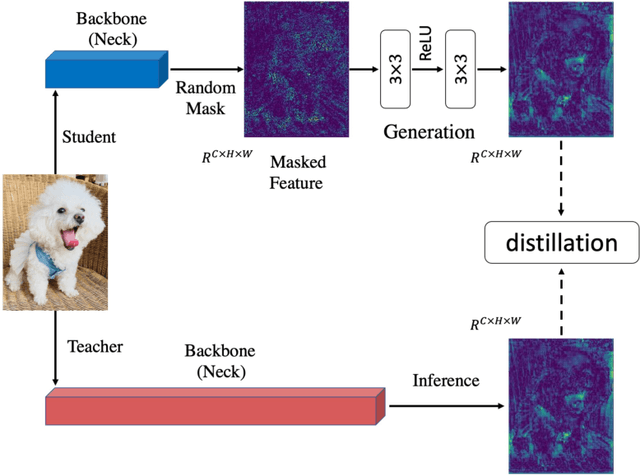
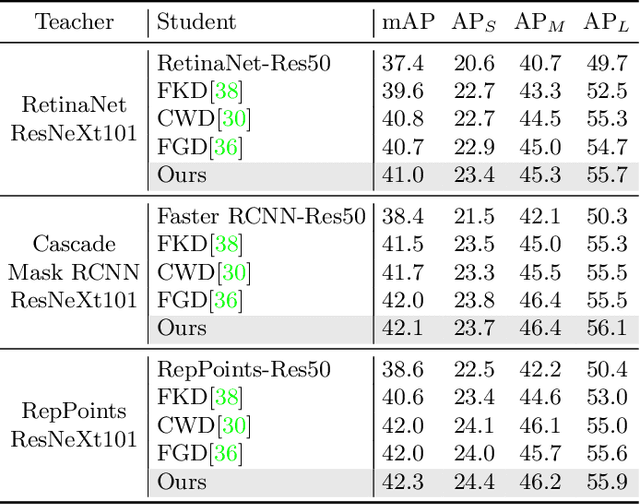
Knowledge distillation has been applied to various tasks successfully. The current distillation algorithm usually improves students' performance by imitating the output of the teacher. This paper shows that teachers can also improve students' representation power by guiding students' feature recovery. From this point of view, we propose Masked Generative Distillation (MGD), which is simple: we mask random pixels of the student's feature and force it to generate the teacher's full feature through a simple block. MGD is a truly general feature-based distillation method, which can be utilized on various tasks, including image classification, object detection, semantic segmentation and instance segmentation. We experiment on different models with extensive datasets and the results show that all the students achieve excellent improvements. Notably, we boost ResNet-18 from 69.90% to 71.69% ImageNet top-1 accuracy, RetinaNet with ResNet-50 backbone from 37.4 to 41.0 Boundingbox mAP, SOLO based on ResNet-50 from 33.1 to 36.2 Mask mAP and DeepLabV3 based on ResNet-18 from 73.20 to 76.02 mIoU. Our codes are available at https://github.com/yzd-v/MGD.