 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeD3-ARM: High-Dynamic, Dexterous and Fully Decoupled Cable-driven Robotic Arm
Feb 18, 2025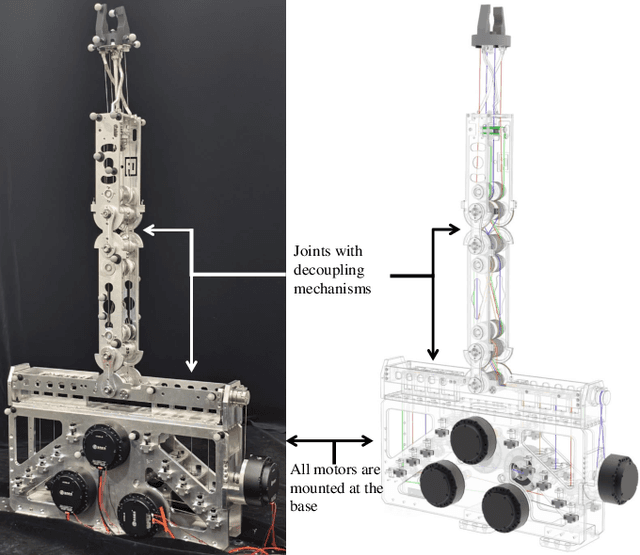



Cable transmission enables motors of robotic arm to operate lightweight and low-inertia joints remotely in various environments, but it also creates issues with motion coupling and cable routing that can reduce arm's control precision and performance. In this paper, we present a novel motion decoupling mechanism with low-friction to align the cables and efficiently transmit the motor's power. By arranging these mechanisms at the joints, we fabricate a fully decoupled and lightweight cable-driven robotic arm called D3-Arm with all the electrical components be placed at the base. Its 776 mm length moving part boasts six degrees of freedom (DOF) and only 1.6 kg weights. To address the issue of cable slack, a cable-pretension mechanism is integrated to enhance the stability of long-distance cable transmission. Through a series of comprehensive tests, D3-Arm demonstrated 1.29 mm average positioning error and 2.0 kg payload capacity, proving the practicality of the proposed decoupling mechanisms in cable-driven robotic arm.
Interpretable Spectrum Transformation Attacks to Speaker Recognition
Feb 21, 2023



The success of adversarial attacks to speaker recognition is mainly in white-box scenarios. When applying the adversarial voices that are generated by attacking white-box surrogate models to black-box victim models, i.e. \textit{transfer-based} black-box attacks, the transferability of the adversarial voices is not only far from satisfactory, but also lacks interpretable basis. To address these issues, in this paper, we propose a general framework, named spectral transformation attack based on modified discrete cosine transform (STA-MDCT), to improve the transferability of the adversarial voices to a black-box victim model. Specifically, we first apply MDCT to the input voice. Then, we slightly modify the energy of different frequency bands for capturing the salient regions of the adversarial noise in the time-frequency domain that are critical to a successful attack. Unlike existing approaches that operate voices in the time domain, the proposed framework operates voices in the time-frequency domain, which improves the interpretability, transferability, and imperceptibility of the attack. Moreover, it can be implemented with any gradient-based attackers. To utilize the advantage of model ensembling, we not only implement STA-MDCT with a single white-box surrogate model, but also with an ensemble of surrogate models. Finally, we visualize the saliency maps of adversarial voices by the class activation maps (CAM), which offers an interpretable basis to transfer-based attacks in speaker recognition for the first time. Extensive comparison results with five representative attackers show that the CAM visualization clearly explains the effectiveness of STA-MDCT, and the weaknesses of the comparison methods; the proposed method outperforms the comparison methods by a large margin.
Automatic quality assessment for 2D fetal sonographic standard plane based on multi-task learning
Dec 11, 2019
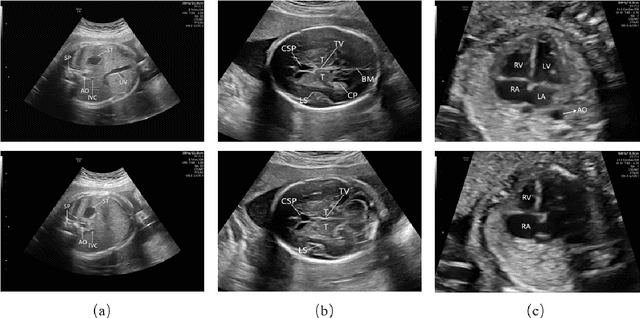
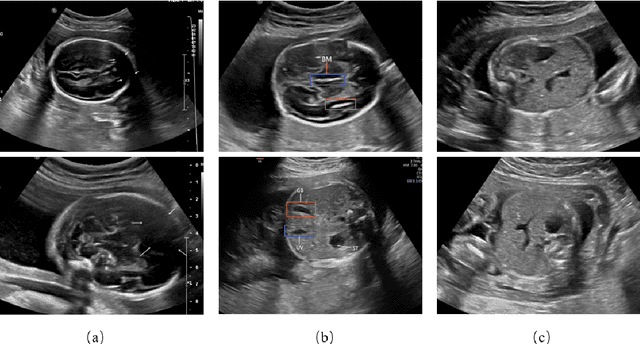
The quality control of fetal sonographic (FS) images is essential for the correct biometric measurements and fetal anomaly diagnosis. However, quality control requires professional sonographers to perform and is often labor-intensive. To solve this problem, we propose an automatic image quality assessment scheme based on multi-task learning to assist in FS image quality control. An essential criterion for FS image quality control is that all the essential anatomical structures in the section should appear full and remarkable with a clear boundary. Therefore, our scheme aims to identify those essential anatomical structures to judge whether an FS image is the standard image, which is achieved by three convolutional neural networks. The Feature Extraction Network aims to extract deep level features of FS images. Based on the extracted features, the Class Prediction Network determines whether the structure meets the standard and Region Proposal Network identifies its position. The scheme has been applied to three types of fetal sections, which are the head, abdominal, and heart. The experimental results show that our method can make a quality assessment of an FS image within less a second. Also, our method achieves competitive performance in both the detection and classification compared with state-of-the-art methods.
ESE: Efficient Speech Recognition Engine with Sparse LSTM on FPGA
Feb 20, 2017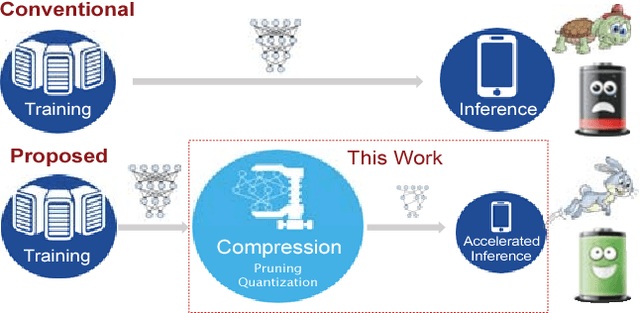

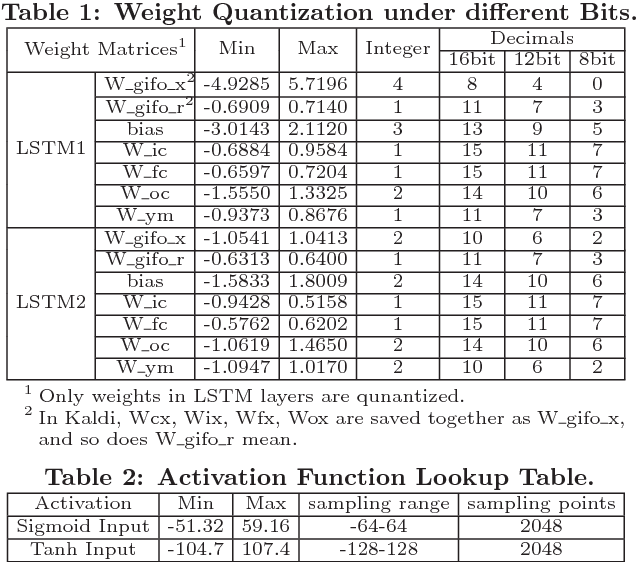
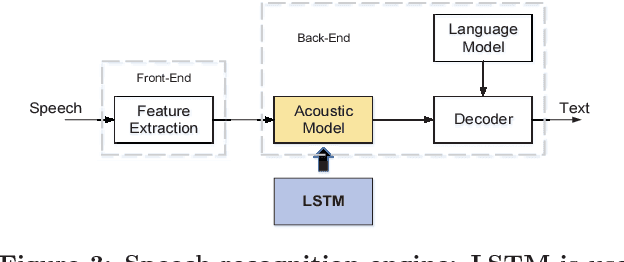
Long Short-Term Memory (LSTM) is widely used in speech recognition. In order to achieve higher prediction accuracy, machine learning scientists have built larger and larger models. Such large model is both computation intensive and memory intensive. Deploying such bulky model results in high power consumption and leads to high total cost of ownership (TCO) of a data center. In order to speedup the prediction and make it energy efficient, we first propose a load-balance-aware pruning method that can compress the LSTM model size by 20x (10x from pruning and 2x from quantization) with negligible loss of the prediction accuracy. The pruned model is friendly for parallel processing. Next, we propose scheduler that encodes and partitions the compressed model to each PE for parallelism, and schedule the complicated LSTM data flow. Finally, we design the hardware architecture, named Efficient Speech Recognition Engine (ESE) that works directly on the compressed model. Implemented on Xilinx XCKU060 FPGA running at 200MHz, ESE has a performance of 282 GOPS working directly on the compressed LSTM network, corresponding to 2.52 TOPS on the uncompressed one, and processes a full LSTM for speech recognition with a power dissipation of 41 Watts. Evaluated on the LSTM for speech recognition benchmark, ESE is 43x and 3x faster than Core i7 5930k CPU and Pascal Titan X GPU implementations. It achieves 40x and 11.5x higher energy efficiency compared with the CPU and GPU respectively.