 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVALLR-Pin: Uncertainty-Factorized Visual Speech Recognition for Mandarin with Pinyin Guidance
Dec 29, 2025Visual speech recognition (VSR) aims to transcribe spoken content from silent lip-motion videos and is particularly challenging in Mandarin due to severe viseme ambiguity and pervasive homophones. We propose VALLR-Pin, a two-stage Mandarin VSR framework that extends the VALLR architecture by explicitly incorporating Pinyin as an intermediate representation. In the first stage, a shared visual encoder feeds dual decoders that jointly predict Mandarin characters and their corresponding Pinyin sequences, encouraging more robust visual-linguistic representations. In the second stage, an LLM-based refinement module takes the predicted Pinyin sequence together with an N-best list of character hypotheses to resolve homophone-induced ambiguities. To further adapt the LLM to visual recognition errors, we fine-tune it on synthetic instruction data constructed from model-generated Pinyin-text pairs, enabling error-aware correction. Experiments on public Mandarin VSR benchmarks demonstrate that VALLR-Pin consistently improves transcription accuracy under multi-speaker conditions, highlighting the effectiveness of combining phonetic guidance with lightweight LLM refinement.
VALLR-Pin: Dual-Decoding Visual Speech Recognition for Mandarin with Pinyin-Guided LLM Refinement
Dec 23, 2025Visual Speech Recognition aims to transcribe spoken words from silent lip-motion videos. This task is particularly challenging for Mandarin, as visemes are highly ambiguous and homophones are prevalent. We propose VALLR-Pin, a novel two-stage framework that extends the recent VALLR architecture from English to Mandarin. First, a shared video encoder feeds into dual decoders, which jointly predict both Chinese character sequences and their standard Pinyin romanization. The multi-task learning of character and phonetic outputs fosters robust visual-semantic representations. During inference, the text decoder generates multiple candidate transcripts. We construct a prompt by concatenating the Pinyin output with these candidate Chinese sequences and feed it to a large language model to resolve ambiguities and refine the transcription. This provides the LLM with explicit phonetic context to correct homophone-induced errors. Finally, we fine-tune the LLM on synthetic noisy examples: we generate imperfect Pinyin-text pairs from intermediate VALLR-Pin checkpoints using the training data, creating instruction-response pairs for error correction. This endows the LLM with awareness of our model's specific error patterns. In summary, VALLR-Pin synergizes visual features with phonetic and linguistic context to improve Mandarin lip-reading performance.
Crossing-Domain Generative Adversarial Networks for Unsupervised Multi-Domain Image-to-Image Translation
Aug 27, 2020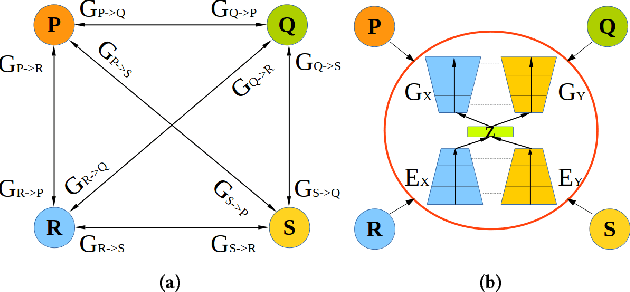
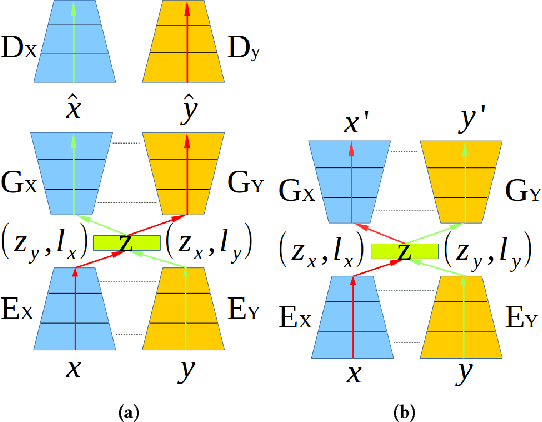
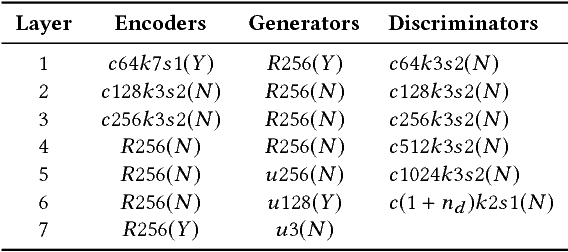
State-of-the-art techniques in Generative Adversarial Networks (GANs) have shown remarkable success in image-to-image translation from peer domain X to domain Y using paired image data. However, obtaining abundant paired data is a non-trivial and expensive process in the majority of applications. When there is a need to translate images across n domains, if the training is performed between every two domains, the complexity of the training will increase quadratically. Moreover, training with data from two domains only at a time cannot benefit from data of other domains, which prevents the extraction of more useful features and hinders the progress of this research area. In this work, we propose a general framework for unsupervised image-to-image translation across multiple domains, which can translate images from domain X to any a domain without requiring direct training between the two domains involved in image translation. A byproduct of the framework is the reduction of computing time and computing resources, since it needs less time than training the domains in pairs as is done in state-of-the-art works. Our proposed framework consists of a pair of encoders along with a pair of GANs which learns high-level features across different domains to generate diverse and realistic samples from. Our framework shows competing results on many image-to-image tasks compared with state-of-the-art techniques.
Learning Tuple Compatibility for Conditional OutfitRecommendation
Aug 18, 2020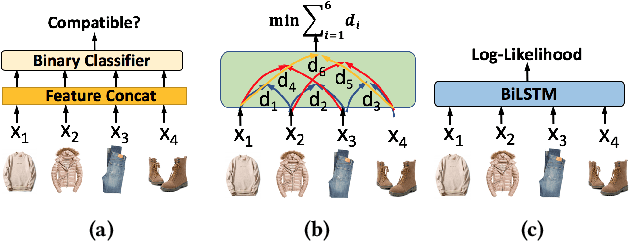
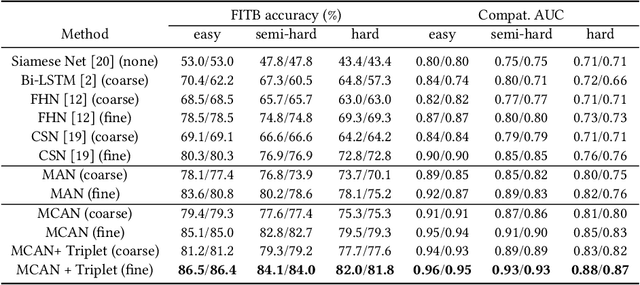
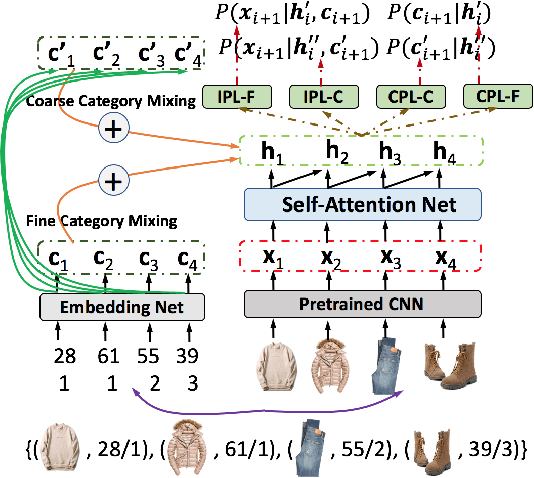
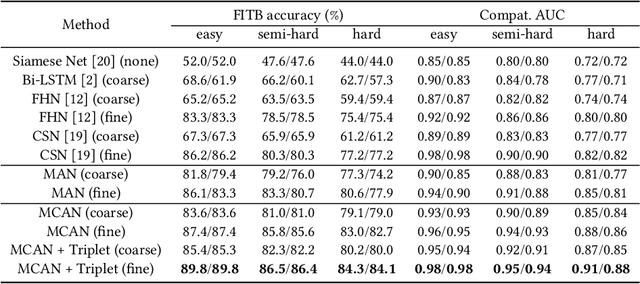
Outfit recommendation requires the answers of some challenging outfit compatibility questions such as 'Which pair of boots and school bag go well with my jeans and sweater?'. It is more complicated than conventional similarity search, and needs to consider not only visual aesthetics but also the intrinsic fine-grained and multi-category nature of fashion items. Some existing approaches solve the problem through sequential models or learning pair-wise distances between items. However, most of them only consider coarse category information in defining fashion compatibility while neglecting the fine-grained category information often desired in practical applications. To better define the fashion compatibility and more flexibly meet different needs, we propose a novel problem of learning compatibility among multiple tuples (each consisting of an item and category pair), and recommending fashion items following the category choices from customers. Our contributions include: 1) Designing a Mixed Category Attention Net (MCAN) which integrates both fine-grained and coarse category information into recommendation and learns the compatibility among fashion tuples. MCAN can explicitly and effectively generate diverse and controllable recommendations based on need. 2) Contributing a new dataset IQON, which follows eastern culture and can be used to test the generalization of recommendation systems. Our extensive experiments on a reference dataset Polyvore and our dataset IQON demonstrate that our method significantly outperforms state-of-the-art recommendation methods.
Fashion Captioning: Towards Generating Accurate Descriptions with Semantic Rewards
Aug 06, 2020
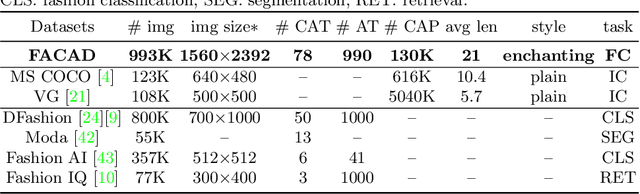
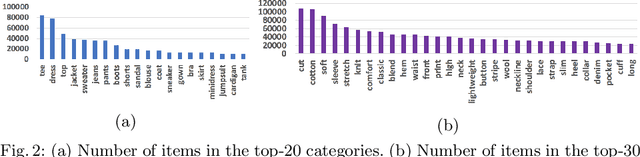
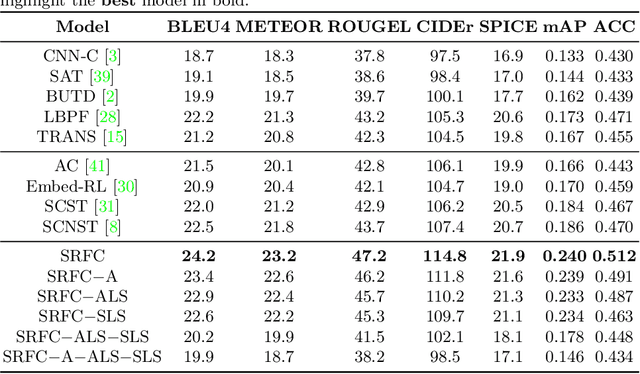
Generating accurate descriptions for online fashion items is important not only for enhancing customers' shopping experiences, but also for the increase of online sales. Besides the need of correctly presenting the attributes of items, the expressions in an enchanting style could better attract customer interests. The goal of this work is to develop a novel learning framework for accurate and expressive fashion captioning. Different from popular work on image captioning, it is hard to identify and describe the rich attributes of fashion items. We seed the description of an item by first identifying its attributes, and introduce attribute-level semantic (ALS) reward and sentence-level semantic (SLS) reward as metrics to improve the quality of text descriptions. We further integrate the training of our model with maximum likelihood estimation (MLE), attribute embedding, and Reinforcement Learning (RL). To facilitate the learning, we build a new FAshion CAptioning Dataset (FACAD), which contains 993K images and 130K corresponding enchanting and diverse descriptions. Experiments on FACAD demonstrate the effectiveness of our model.
Adaptive Activation Network and Functional Regularization for Efficient and Flexible Deep Multi-Task Learning
Nov 19, 2019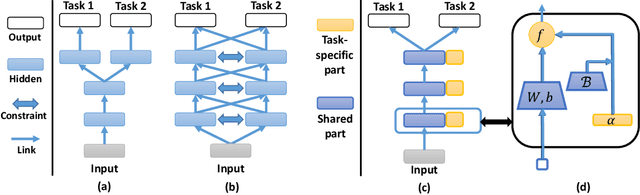
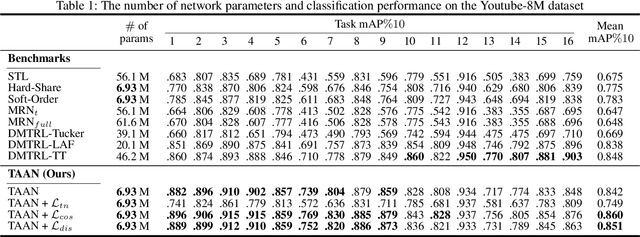
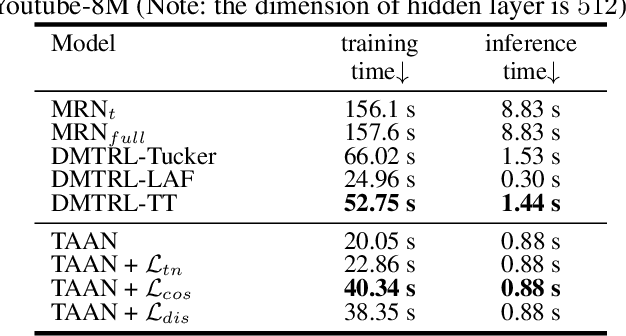
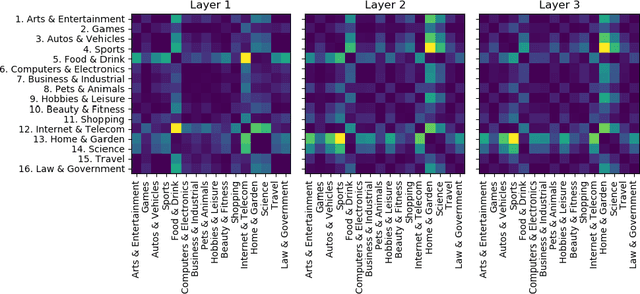
Multi-task learning (MTL) is a common paradigm that seeks to improve the generalization performance of task learning by training related tasks simultaneously. However, it is still a challenging problem to search the flexible and accurate architecture that can be shared among multiple tasks. In this paper, we propose a novel deep learning model called Task Adaptive Activation Network (TAAN) that can automatically learn the optimal network architecture for MTL. The main principle of TAAN is to derive flexible activation functions for different tasks from the data with other parameters of the network fully shared. We further propose two functional regularization methods that improve the MTL performance of TAAN. The improved performance of both TAAN and the regularization methods is demonstrated by comprehensive experiments.
Latent Part-of-Speech Sequences for Neural Machine Translation
Aug 30, 2019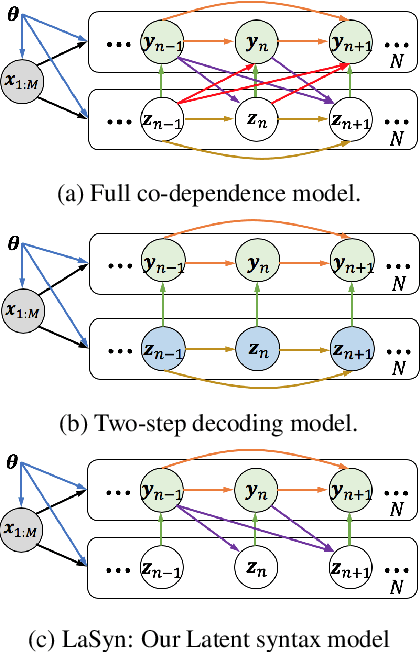
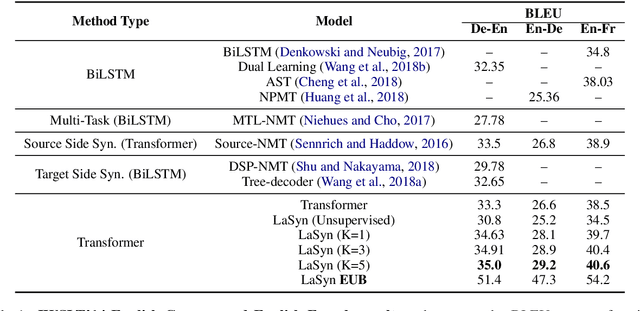
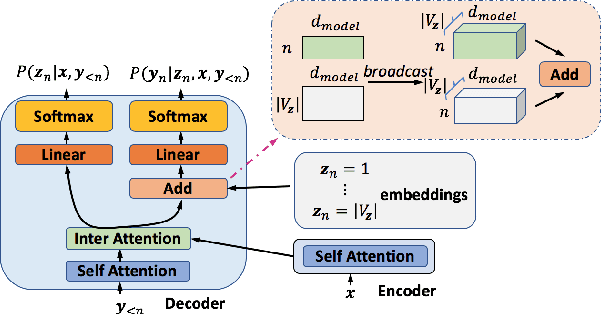

Learning target side syntactic structure has been shown to improve Neural Machine Translation (NMT). However, incorporating syntax through latent variables introduces additional complexity in inference, as the models need to marginalize over the latent syntactic structures. To avoid this, models often resort to greedy search which only allows them to explore a limited portion of the latent space. In this work, we introduce a new latent variable model, LaSyn, that captures the co-dependence between syntax and semantics, while allowing for effective and efficient inference over the latent space. LaSyn decouples direct dependence between successive latent variables, which allows its decoder to exhaustively search through the latent syntactic choices, while keeping decoding speed proportional to the size of the latent variable vocabulary. We implement LaSyn by modifying a transformer-based NMT system and design a neural expectation maximization algorithm that we regularize with part-of-speech information as the latent sequences. Evaluations on four different MT tasks show that incorporating target side syntax with LaSyn improves both translation quality, and also provides an opportunity to improve diversity.
ESE: Efficient Speech Recognition Engine with Sparse LSTM on FPGA
Feb 20, 2017

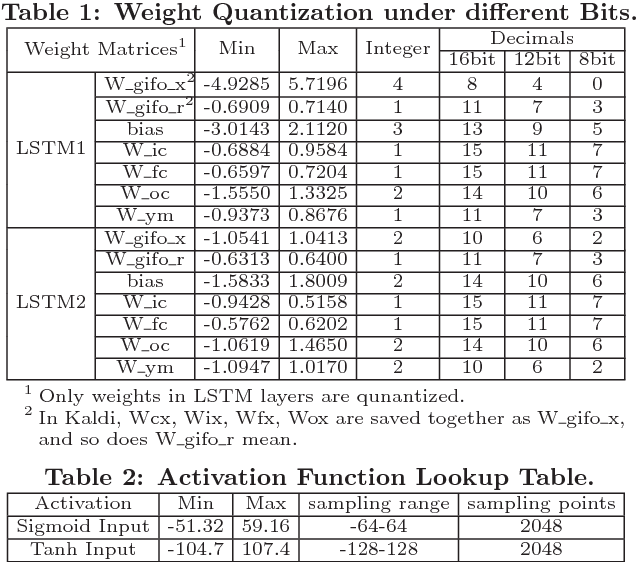
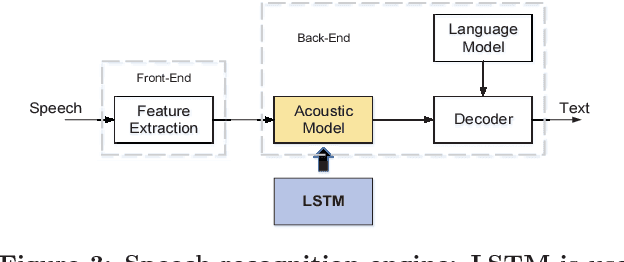
Long Short-Term Memory (LSTM) is widely used in speech recognition. In order to achieve higher prediction accuracy, machine learning scientists have built larger and larger models. Such large model is both computation intensive and memory intensive. Deploying such bulky model results in high power consumption and leads to high total cost of ownership (TCO) of a data center. In order to speedup the prediction and make it energy efficient, we first propose a load-balance-aware pruning method that can compress the LSTM model size by 20x (10x from pruning and 2x from quantization) with negligible loss of the prediction accuracy. The pruned model is friendly for parallel processing. Next, we propose scheduler that encodes and partitions the compressed model to each PE for parallelism, and schedule the complicated LSTM data flow. Finally, we design the hardware architecture, named Efficient Speech Recognition Engine (ESE) that works directly on the compressed model. Implemented on Xilinx XCKU060 FPGA running at 200MHz, ESE has a performance of 282 GOPS working directly on the compressed LSTM network, corresponding to 2.52 TOPS on the uncompressed one, and processes a full LSTM for speech recognition with a power dissipation of 41 Watts. Evaluated on the LSTM for speech recognition benchmark, ESE is 43x and 3x faster than Core i7 5930k CPU and Pascal Titan X GPU implementations. It achieves 40x and 11.5x higher energy efficiency compared with the CPU and GPU respectively.